1. MyBatis的好处
(1)封装JDBC操作
(2)完成对象到关系,关系到对象的映射
(3)可以在xml文件中灵活的编写sql
2. 初始化MyBatis过程
以下部分源码来自官方文档
根据官方文档,如果需要使用mybatis
(1)可以使用xml声明
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>(2)使用java
DataSource dataSource = BlogDataSourceFactory.getBlogDataSource();
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(BlogMapper.class);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);无论是使用哪种方式,都需要构造Configuration这个对象(org.apache.ibatis.session.Configuration)。
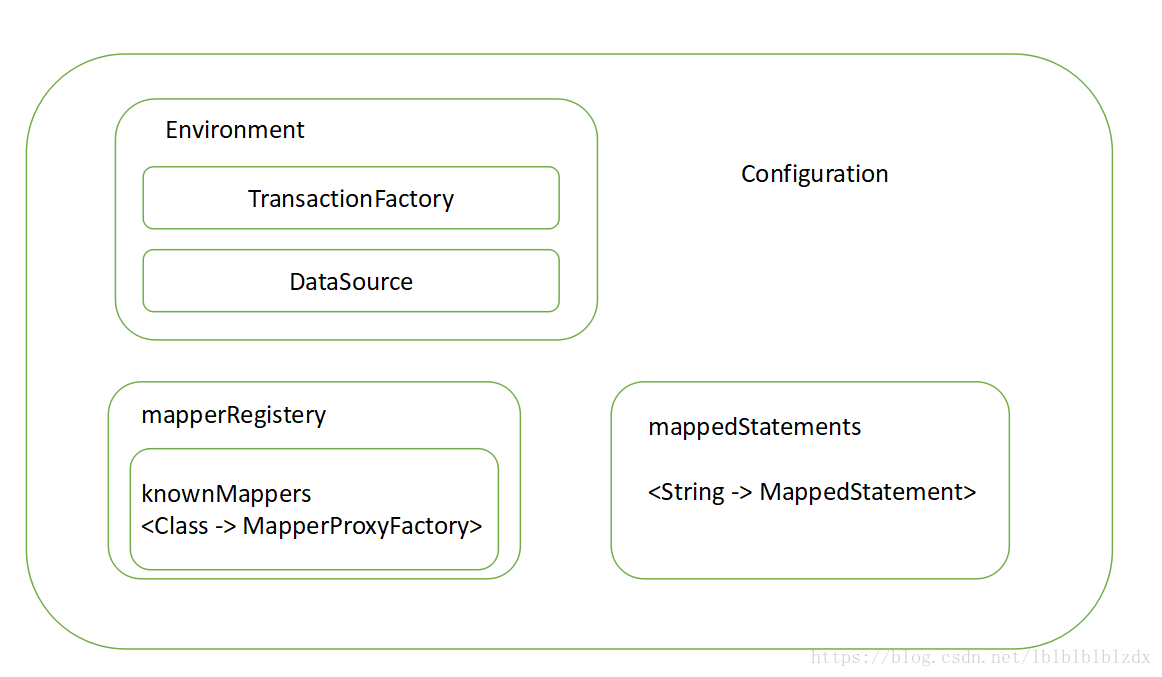
3. 添加mapper
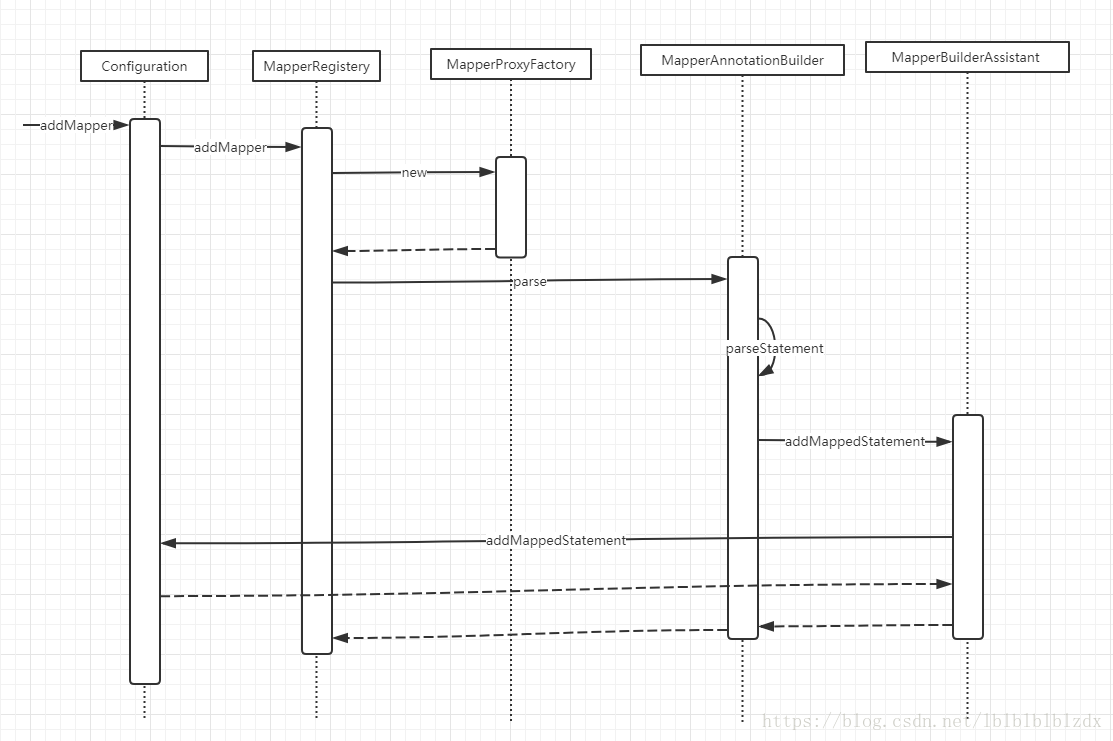
添加mapper主要做这两个事
(1)在mapperRegistery中注册一个MapperProxyFactory,这个MapperProxyFactory是用来生成该mapper代理类的。
(2)解析mapper对应xml中的sql语句成MappedStatement,并存到Configuration中的mappedStatements中。
4. getMapper
mapper是一个接口类,并没有实际的逻辑,它是如何与sql关联起来的呢
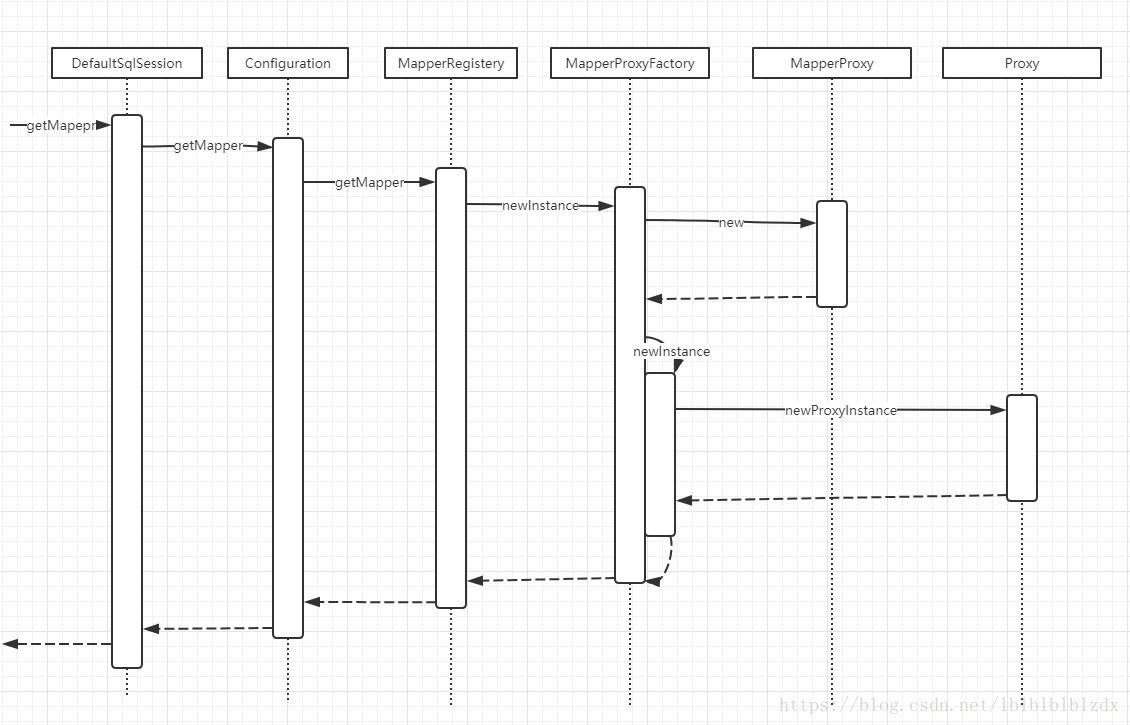
getMapper最后会调用MapperProxyFactory的newInstance方法,让mapper代理工厂生成一个mapper代理类,这里使用的是JDK动态代理。
5. 执行查询
调用Mapper的方法进行查询时,会直接调用MapperProxy的invoke方法,可以从这里追溯。
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}这是查询的处理流程:
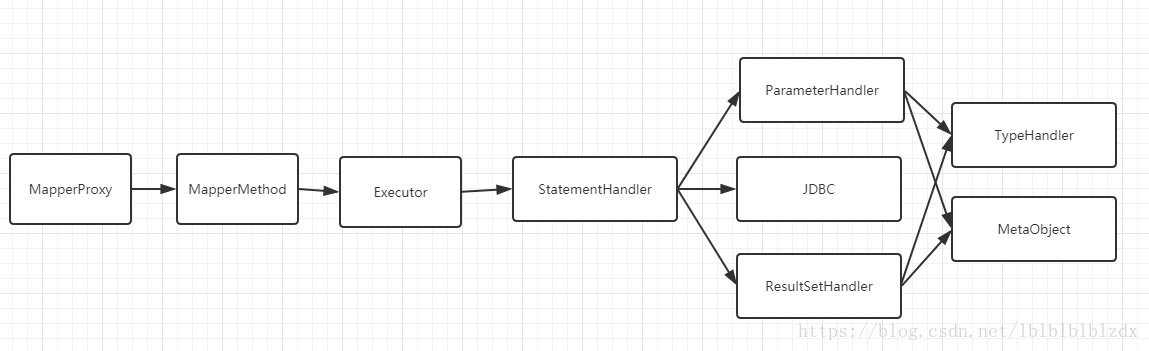
(1)查询任务会交给Executor运行,由于Configuration的cacheEnabled默认为true,所以这里会先交给CachingExecutor处理,然后交给SimpleExecutor处理。
(2)ParameterHandler会将处理传入参数,生成最终的sql
(3)ResultSetHandler会处理得到的结果,转换成对象
(4)对象都会被封装成MetaObject,MetaObject里会使用JDK反射完成对象到关系,关系到对象的操作。
6. 获取SqlSession

7. 连接池管理
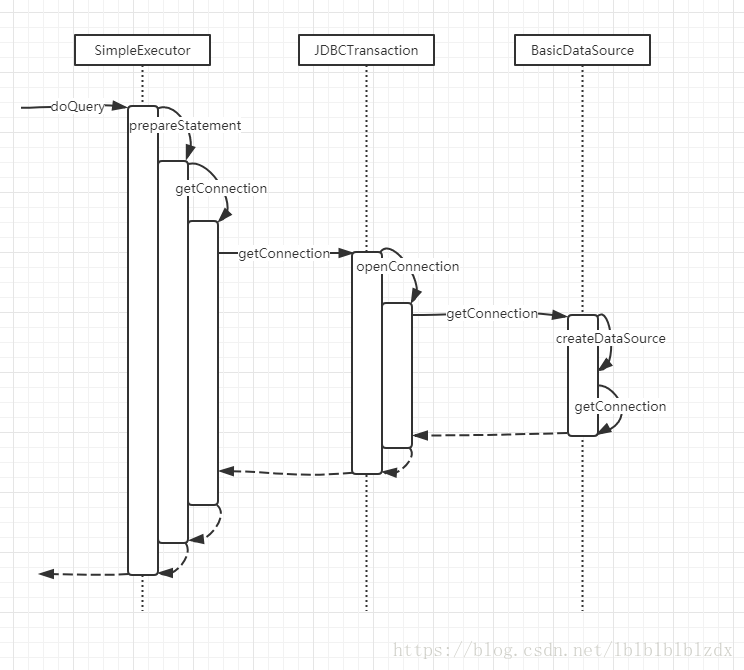
这里DataSource使用的是org.apache.commons.dbcp.BasicDataSource。
当执行查询时,Executor会向Transaction获取连接,而Transaction会向DataSource获取连接,这里的BasicDataSource会建立一个连接池,每次getConnection会从连接池中取连接。
8. 缓存机制
8.1 一级缓存
一级缓存是默认开启的,在执行查询时,BasicExecutor的query方法中,会从localCache中获取缓存,获取不到则从查询数据库。
(1)这个localCache是BasicExecutor的变量,由于Executor是在openSession时创建的,每个Session一个Executor,所以一级缓存是SqlSession级别的。
(2)再看CacheKey的组成,当这些都一致时,才能获取缓存而不是查数据库。
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
cacheKey.update(parameterObject);
cacheKey.update(metaObject.getValue(propertyName));
cacheKey.update(boundSql.getAdditionalParameter(propertyName));(3)Executor中的clearLocalCache方法会在update等操作后被调用,所以一旦有更新操作,则会清除缓存。
8.2 二级缓存
二级缓存默认是没有开启,需要在mapper.xml中开启
<cache/ >
<select useCache="true">第一个cache标签是表明初始化mapper的cache
第二个useCache是表明该查询使用缓存
缓存的逻辑在CachingExecutor的query方法中
(1)cache是整个mapper共有的,每个语句里均存储一个引用,所以与sqlsession无关,是mapper级别的。
(2)如果useCache为true且缓存是非dirty的(没有提交过修改),则使用缓存
(3)当update过会清空缓存,并设为dirty,此次session将不会使用缓存
9. 分页
9.1 内存分页
内存分页是假的分页,会查出所有数据,然后在内存中选取需要的数据。
在查询时传入RowBounds即可实现内存分页,在处理结果时,ResultSetHandler会做这个分页操作。
分页代码逻辑在FastResultSetHandler的handleRowValue方法里
protected void handleRowValues(ResultSet rs, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultColumnCache resultColumnCache) throws SQLException {
final DefaultResultContext resultContext = new DefaultResultContext();
skipRows(rs, rowBounds);
while (shouldProcessMoreRows(rs, resultContext, rowBounds)) {
final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rs, resultMap, null);
Object rowValue = getRowValue(rs, discriminatedResultMap, null, resultColumnCache);
callResultHandler(resultHandler, resultContext, rowValue);
}
}skipRows会跳过不需要的行,shouldProcessMoreRows会判断哪行该结束
9.2 物理分页
需要物理分页可以使用物理分页插件com.github.pagehelper.PageInterceptor
9.2.1 使用方式
mybatis配置中声明plugin
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
</plugin>
</plugins>查询方式
PageHelper.startPage(page, count);
list = //query here
PageInfo<MyObject> pageInfo = new PageInfo<MyObject>(list);9.2.2 plugin原理
在openSession时,会创建Executor,并且把plugin装配到executor上
executor = (Executor) interceptorChain.pluginAll(executor);实际的装配方式是这样的,生成新的代理类,把原Executor封装在里面,这样调用Executor的方法时就可以先跑插件的逻辑再跑executor的逻辑。
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap));
}
return target;
}如果有多个插件,此处是会层层生成代理类(每个插件都会生成一个ExecutorProxy,第二个插件又会在ExecutorProxy的基础上生成ExecutorProxy2),所以要减少不必要的插件,提升性能。
9.2.3 com.github.pagehelper.PageInterceptor原理
调用startPage时,会将LOCAL_PAGE设置为要设置的分页信息,这里LOCAL_PAGE使用的ThreadLocal,所以不会影响到别的线程。
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();由于plugin中声明了PageInterceptor,所以调用Executor前会先被PageInterceptor的intercept方法拦截到。在PageInterceptor的intercept方法中会从线程变量LOCAL_PAGE中取出分页信息,然后根据分页信息改装sql。分页查询过程:
(1)先查出总条数
(2)再根据不同方言改造sql查出分页数据,比如mysql就是增加limit语句。
10. 延迟加载
10.1 配置方法
#configuration中配置懒加载
<setting name="lazyLoadingEnabled" value="true" />
#此设为true,会导致其中一个关联属性被加载,则会触发加载所有关联属性
<setting name="aggressiveLazyLoading" value="false"/>
#mapper.xml的resultMap中配置association
<resultMap type="UserInfo" id="UserInfoMap">
<id property="id" column="id" />
<result property="name" column="name" />
<association property="device" javaType="Device" select="findDevice" column="device_id" />
</resultMap>10.2 懒加载原理
当查询查出结果时,会交给FastResultSetHandler来处理每行的结果(getRowValue方法)。
getRowValue中主要做了两个事情:
(1)createResultObject,这里会生成一个新的目标对象,假如开启了懒加载,这里会使用cglib生成一个代理类对象,
代理类对象的callback类为EnhancedResultObjectProxyImpl。
(2)applyPropertyMappings,将值设置到对象里,如果属性为关联且开启了懒加载,则不会设值,而是往lazyLoader里添加一个ResultLoader。
当调用对象的关联属性的get方法时,会被EnhancedResultObjectProxyImpl的intercept拦截到,检测到该属性为懒加载属性且未加载,则会调用其ResultLoader提交查询获取数据。
11. 日志
参考:http://www.mybatis.org/mybatis-3/zh/logging.html
配置日志使用log4j
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>日志配置文件中增加
log4j.logger.com.xxx.xxx.mapper=DEBUG则可在调用sql时打印出语句、参数、结果
2018-08-20 10:48:53[BaseJdbcLogger:132]ooo Using Connection [jdbc:mysql://......]
2018-08-20 10:48:53[BaseJdbcLogger:132]==> Preparing: ......
2018-08-20 10:48:54[BaseJdbcLogger:132]==> Parameters: ......
2018-08-20 10:48:54[BaseJdbcLogger:138]<== Columns: ......
2018-08-20 10:48:54[BaseJdbcLogger:138]<== Row: ......但这里的语句是没有把参数置换进去的语句,如果想看替换后的语句,可以在PreparedStatementHandler中的parameterize方法打断点看,执行完这个方法后,可以看到参数替换后的sql语句。
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}