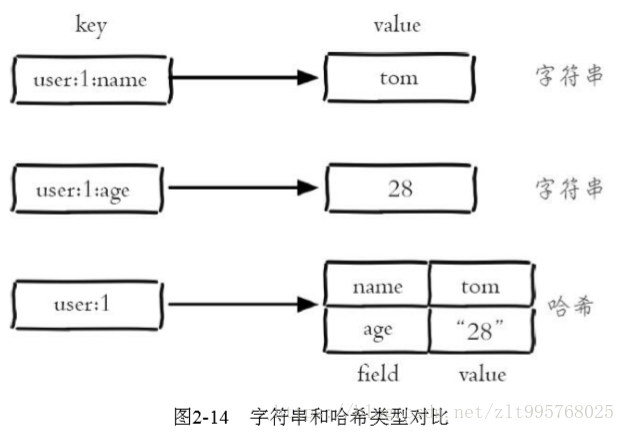
哈希
哈希类型是指键值本身又是一个键值对结构;哈希类型中的映射关系叫作field-value,注意这里的value是指field对应 的值,不是键对应的值,请注意value在不同上下文的作用。
命令
#设置值
hset key field value
#获取值,若不存在返回nil
hget key field
#删除field
hdel key field [field ...]
#计算field个数
hlen key
#批量设置或获取field-value
hmget key field [field ...]
hmset key field value [field value ...]
#判断field是否存在,存在返回1,不存在返回0
hexists key field
#获取所有field
hkeys key
#获取所有value
hvals key
#获取所有的field-value,可以尝试采用hscan该命令会渐进式遍历哈希类型
hgetall key
#自增指定数字,作用域为field
hincrby key field
#自增指定浮点数,作用域为field
hincrbyfloat key field
#计算value的字符串长度(需要redis3.2以上)
hstrlen key field内部编码
ziplist:value小于64个字节,并且field个数不会超过512个
hashtable:value大于64个字节,并且field个数超过512个使用场景
缓存用户信息,用户表属性field为表的列,每条用户信息作为行
优缺点:
优点:相比字符串缓存用户信息,哈希类型变得更加直观
缺点:若关系型数据库新增列,需要和以前存储在redis的用户信息属性保持一致,比较困难;不可做复杂查询
| 缓存方式 | 优点 | 缺点 |
|---|---|---|
| 原生字符串(生产环境不推荐) | 简单直观,每个属性都支持更新操作 | 占用过多的键,内存占用量较大,同时用户信息内聚性比较差 |
| 序列化字符串类型 | 简化编程,如果合理的使用序列化可以提高内存的使用效率 | 序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中 |
| 哈希类型 | 简单直观,如果使用合理可以减少内存空间的使用 | 控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存 |