1、明确分析的目的和思路
目的:目前,足球比赛作为大众娱乐项目的一种,越来越受到大家的喜爱,其中不乏一些球队死忠、球星铁粉以及“赌球狗”,而希望自己支持的球队获胜也是足球比赛中的一大关注点。针对这种情况,本文通过足球比赛中产生的数据,比如射门次数、控球率、传球成功率等,运用关联规则算法进行建模、分析,探索足球比赛的胜负与哪些关键指标的关系密切。
思路:以本赛季的中超联赛(目前进行到第18轮)为分析对象,爬取体育网站上的各场比赛数据和胜负结果,经过数据处理后,采用Apriori算法,挖掘各数据指标与比赛结果之间的关系。
2、数据收集
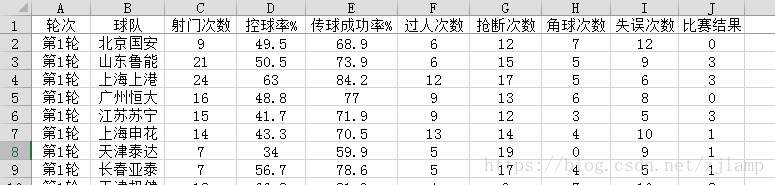
对tzuqiu网站(http://www.tzuqiu.cc/)上的每场中超比赛的数据进行爬取,包括:1、射门次数,2、控球率,3、传球成功率,4、过人次数,5、抢断次数,6、角球次数,7、失误次数,以及比赛结果(胜、平、负)。如图1所示:

最终结果共288条记录(18轮*每轮8场比赛*每场2支球队),结果如图2所示:
3、数据处理
使用Rstudio工具进行处理。
(1)数据清洗
首先导入数据,然后处理缺失值。
考虑到含有缺失值的记录较少(只有2条,第13轮上海上港与广州恒大的比赛因为天气原因延期进行),决定把源数据中含有缺失值的记录删除。
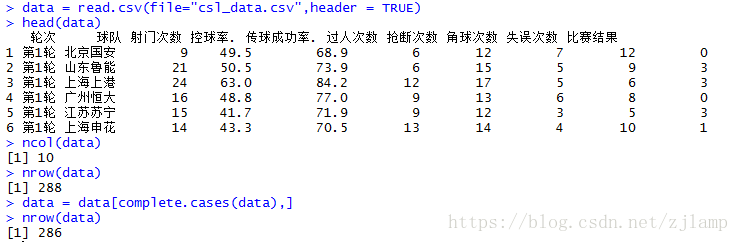
data = read.csv(file="csl_data.csv",header = TRUE) #导入数据
head(data) #列出前6条记录
ncol(data) #列数
nrow(data) #行数
data = data[complete.cases(data),] #去除含有缺失值的记录
nrow(data)
输出结果如图3:
(2)数据规约
经过处理,数据集中有10个变量、286条记录。
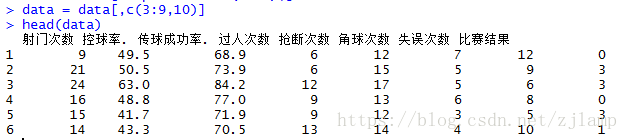
为了有效地进行建模分析,将其中与建模任务不相关的属性剔除。因此,选取“射门次数”、“控球率%”、“传球成功率%”、“过人次数”、“抢断次数”、“角球次数”、“失误次数”和“比赛结果”列构成的数据集,其中“比赛结果”列中,3表示胜,1表示平,0表示负。
data = data[,c(3:9,10)] #取出指标列和结果列
head(data)输出结果如图4:
(3)数据离散化
由于Apriori算法无法处理连续型数值变量,为了将原始数据格式转换成适合建模的格式,需要对数据进行离散化。
采用聚类算法对各个数据指标进行离散化处理,将每个属性分成五类。
type = 5 #数据离散化的分组个数
index = 8 #比赛结果列
typelabel = c("A","B","C","D","E","F","G") #离散化后的标识前缀
cols = ncol(data[,1:7]) #数据指标列的个数
rows = nrow(data[,1:7]) #数据集的行数
disdata = matrix(NA,rows,cols+1) #初始化
for (i in 1:cols){
cl = kmeans(data[,i],type,nstart = 20)
disdata[,i] = paste(typelabel[i],cl$cluster,sep="")
} #建立循环,对每个数据指标列进行聚类
disdata[,cols+1] = paste("H",data[,index],sep = "") #对结果列进行离散化
disdata = data.frame(disdata) #转换为数据框格式
colnames(disdata) = c("射门次数","控球率%","传球成功率%","过人次数","抢断次数","角球次数","失误次数","比赛结果") #修改列名
head(disdata)输出结果如图5:

各个属性离散化后的结果如表1所示。
| 标识 | 聚类中心 | 标识 | 聚类中心 | 标识 | 聚类中心 | 标识 | 聚类中心 | 标识 | 聚类中心 | 标识 | 聚类中心 | 标识 | 聚类中心 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A1 | 24.7 | B1 | 57.65 | C1 | 66.63 | D1 | 12.13 | E1 | 11.48 | F1 | 1.64 | G1 | 19.27 |
| A2 | 18.55 | B2 | 67.14 | C2 | 57.97 | D2 | 8.92 | E2 | 20.74 | F2 | 10.16 | G2 | 14.06 |
| A3 | 6.78 | B3 | 42.35 | C3 | 84.38 | D3 | 5.89 | E3 | 29.17 | F3 | 7.33 | G3 | 4.81 |
| A4 | 14.26 | B4 | 50 | C4 | 78.94 | D4 | 17.21 | E4 | 7.33 | F4 | 5.43 | G4 | 8 |
| A5 | 10.43 | B5 | 32.86 | C5 | 73.13 | D5 | 3.26 | E5 | 16.14 | F5 | 3.54 | G5 | 10.97 |
4、数据建模
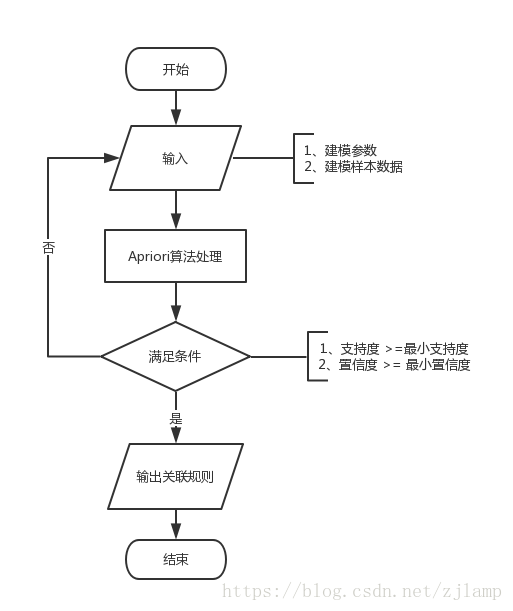
采用Apriori关联规则算法,挖掘数据指标与比赛结果之间的关联关系。建模的流程如图6所示。
library(arules)
trans = as(disdata,"transactions") #将数据转换为transactions格式
rules = apriori(trans,parameter = list(support=0.03,confidence=0.75)) #调用Apriori算法生成关联规则rules
inspect(rules)输出结果如图7所示

5、结果分析
由于探究数据指标与比赛结果之间的关系,我们只关注关联规则集中的第六条和第八条规则。
(1)B4、C4、D1 => H3,支持度达到3.5%,置信度达到76.92%。
说明当控球率达到50%、传球成功率达到79%和过人次数达到12次左右时,赢得比赛的可能性为76.92%,这种情况在统计的数据中发生的可能性为3.5%。
(2)A4、C4、G4 => H0,支持度达到3.5%,置信度达到83.33%。
说明当射门次数14次左右、传球成功率79%和失误次数8次左右时,输掉比赛的可能性为83.33%,这种情况在统计的数据中发生的可能性为3.5%。
综上所述,在中超赛场上,若要赢得比赛胜利,需要保持均衡的控球率,提高传球成功率以及多尝试过人;同时为了避免输球,注意控制失误次数以及提高射门次数。