Map另一个基本的集合接口
接口中定义的所有方法:
public static interface Entry<K,V> {
public boolean equals(Object object);
public K getKey();
public V getValue();
public int hashCode();
public V setValue(V object);
};
public void clear();
public boolean containsKey(Object key);
public boolean containsValue(Object value);
public Set<Map.Entry<K,V>> entrySet();
public boolean equals(Object object);
public V get(Object key);
public int hashCode();
public boolean isEmpty();
public Set<K> keySet();
public V put(K key, V value);
public void putAll(Map<? extends K,? extends V> map);
public V remove(Object key);
public int size();
public Collection<V> values();HashMap:重要的成员变量以及构造方法
public class HashMap<K, V> extends AbstractMap<K, V> implements Cloneable, Serializable {
/**
* 常量,最小容量capacity(这个单词不陌生吧)
*/
private static final int MINIMUM_CAPACITY = 4;
/**
* 常量,最大容量,移位运算,2的30次方-----1073741824(这么大一个值)
* int的取值范围想必大家都记得(-2的31次方 到 2的31次方-1),这里取2的30次方,是一个很有深意的值
* 简单透露一下就是HashMap扩容后数组长度都保证是2的n次方,这个后面遇到我会说
*/
private static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* Entry是一个接口,HashMapEntry是它的实现类,后面有写,MINIMUM_CAPACITY >>> 1 就是2,也就
* 说一开始创建了一个长度为2的HashMapEntry[]数组对象并赋值给一个Entry[]数组实例EMPTY_TABLE。
*
*/
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
/**
*默认负载因子,一个很重要的概念,和扩容相关 .75F的意思大概数组长度到达了总长度的百分之七十五也就是
*四分之三就开始进行扩容了,后面我们会描述
*/
static final float DEFAULT_LOAD_FACTOR = .75F;
/**
* HashMap集合其实就是保存了HashMapEntry<K, V>对象,这里定义一个table数组实例。
*/
transient HashMapEntry<K, V>[] table;
/**
* HashMap集合允许Key为null,entryForNullKey就是用来存放这个的
*/
transient HashMapEntry<K, V> entryForNullKey;
/**
* 集合数据元素数量
*/
transient int size;
/**
* 计数器,相信看过我前面文章的都见过多次了,但是估计做用是什么都不是很了解,这是一种fail-fast机制
* 当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件,比如你在for循环遍历集合的过
* 程中,其他线程在对集合进行添加和删除操作,这样的话就会发生异常,很多函数中都要先进行计数器的比较
* 从而保证不出现异常,一旦发现异常就抛出ConcurrentModificationException这个异常
*/
transient int modCount;
/**
*阈(yu四声)值 哈哈,也是和扩容相关的,很重要的一个属性
*/
private transient int threshold;
// Views - lazily initialized
//key集合,使用的是Set 这也就是键唯一原因
private transient Set<K> keySet;
private transient Set<Entry<K, V>> entrySet;
//values集合,使用的是Collection 所以值是可以重复相同的
private transient Collection<V> values;
/**
* 无参构造,将EMPTY_TABLE赋值给了table ,这两个属性上文都可以找到
* threshold 阈值默认值-1(因为HashMap使用的是懒加载,为什么到put方法的时候我会说)
* 还有这里我们可以发现table的长度是2,也就是2的1次方,还记得我说过关于容量的事吗
*/
@SuppressWarnings("unchecked")
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}
/**
*这是一个参数的构造函数,传入一个int值作为容量,你可以发现无论你传入的值是多少它都会把你传入的值变
*成一个2的n次方的值,这个n的大小有一定的计算方式。
*/
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
//传0,就相当于使用无参构造
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
//传小于MINIMUM_CAPACITY 就当你传的是MINIMUM_CAPACITY 2的2次方
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
//传大于MAXIMUM_CAPACITY 就当你传的是MAXIMUM_CAPACITY 2的30次方
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
/**
*通过Collections.roundUpToPowerOfTwo(capacity);方法计算capacity ,放心还是一个2的
*n次方的值,气不气?该方法表示的就是找到一个比capacity大的2的n次方的最小值,可能不是太明白,
*如果capacity是3就返回4,因为2的1次方比3小,不合适,所以是2的2次方,同样如果
*capacity是9则返回16,因为2的3次方是8比9小,所以返回2的4次方16,- -!好气哦
*/
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
//构建table
makeTable(capacity);
}
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
/**
*这里给threshold阈值弄一个新值,假如newCapacity 是16 16>>1就是8 加上 16>>2就是4
*8+4=12 12是16的0.75也就是四分之三(只有2的n次方才可以完美的演绎四分之三)
*/
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}
//HashMapEntry HashMap就是存储这个类的对象的
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;//看到next是不是想起了链表,没错hashMap就是一个散列链表
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
}
}- 增加
@Override
public V put(K key, V value) {
//如果key为null,这里是显示出了HashMap的key运行为null值
if (key == null) {
return putValueForNullKey(value);
}
//对key进行哈希算法(进行了两次哦,看名字就知道了)拿到key的hashCode然后调用secondaryHash再玩一遍
int hash = Collections.secondaryHash(key);
//这种出于安全性的内部变量不多说了
HashMapEntry<K, V>[] tab = table;
/**
*得出index值,是通过上面的hash值和HashMapEntry[]数组长度-1,进行与运算(位运算),最后index
*值肯定是在0~tab.length - 1之间
*/
int index = hash & (tab.length - 1);
//链表循环遍历
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
//哈希值相同key也相同那么就是替换喽
if (e.hash == hash && key.equals(e.key)) {
//★用来给子类重写使用的★
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
//扩容啊!之前说过HashMap懒加载,因为使用无参构造threshold默认值是-1啊,那么一进行put肯定if成立啊
if (size++ > threshold) {
//doubleCapacity() 看名字就知道扩容了多少
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
//★添加新元素★
addNewEntry(key, value, hash, index);
return null;
}
/**
* Give LinkedHashMap a chance to take action when we modify an existing
* entry.
*
* @param e the entry we're about to modify.
*/
void preModify(HashMapEntry<K, V> e) { }
---------------哈希部分-------------------
public int hashCode() {
int lockWord = shadow$_monitor_;
final int lockWordStateMask = 0xC0000000; // Top 2 bits.
final int lockWordStateHash = 0x80000000; // Top 2 bits are value 2 (kStateHash).
final int lockWordHashMask = 0x0FFFFFFF; // Low 28 bits.
if ((lockWord & lockWordStateMask) == lockWordStateHash) {
return lockWord & lockWordHashMask;
}
return System.identityHashCode(this);
}
public static int secondaryHash(Object key) {
return secondaryHash(key.hashCode());
}
private static int secondaryHash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
---------------put相关-------------------
private V putValueForNullKey(V value) {
HashMapEntry<K, V> entry = entryForNullKey;
//说明之前没有key为null的值添加过,首次添加key为null的值
if (entry == null) {
//★添加null key元素★
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
//说明之前有key为null的值添加过,进行vaule的替换
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}
//形成链表的重要函数
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
//创建一个NullKey的HashMapEntry对象
void addNewEntryForNullKey(V value) {
entryForNullKey = new HashMapEntry<K, V>(null, value, 0, null);
}看完put函数可能大家还有很多疑问,我们很好理解List这种结构也很好理解LinkedList这种链表结构,那么HashMap是一种怎样的散列链表呢,或者基于哈希表的Map接口实现呢
我们在put方法中可以看到,对传入的Key进行了二次哈希得到hash值,并将这个hash值与tab.length-1进行了&运算,那么大家可能发现如果2个值hash值相同,那么&运算后得到的index一定是相同,还有即使两个key的hash值不同,但是&运算还有可以导致index相同,在传统的Object[]中index相同可以就直接替换,那么这里是以一种什么方式来存在呢,其实HashMap这种散列链表结构类似于我们手机通讯录,A~Z
就是indext,但是A中会有多个数据,我们画图来表示一下大家就看的很明白了
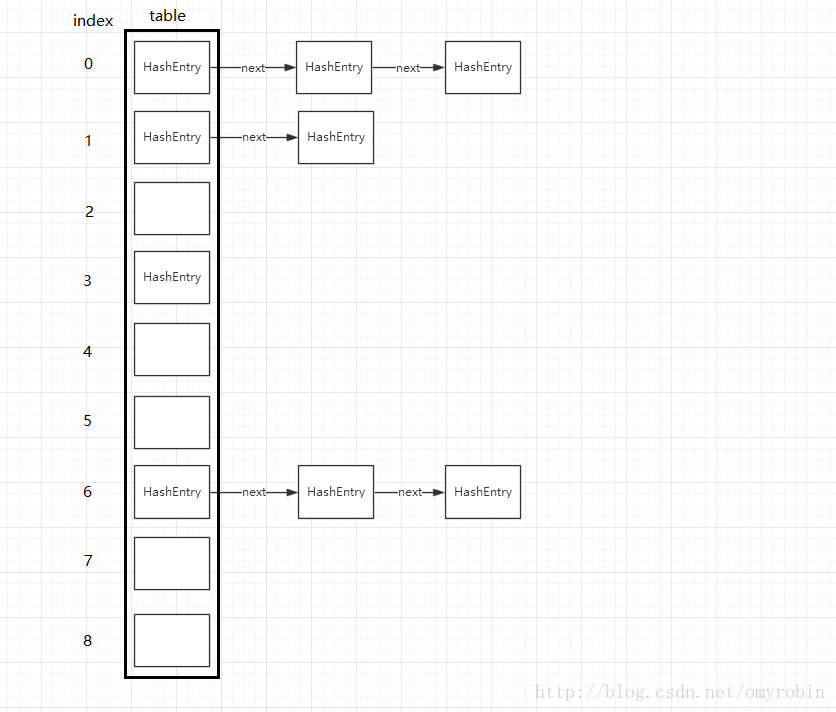
是不是很清晰,如果index相同就加入到链表中,用next来记录下一个元素的引用,注意每次新添加元素调用put方法都会执行
//形成链表的重要函数
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}我们可以发现新添加的元素都是放到链表的头部的,这个是需要大家注意的,将之前的table[index]作为新的table[index]的next。(函数是先计算等号右边哦)
- 删除
@Override
public V remove(Object key) {
if (key == null) {
return removeNullKey();
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
//相信上边这部分大家通过put方法都可以理解了
//现在来看for循环
for (HashMapEntry<K, V> e = tab[index], prev = null;
e != null; prev = e, e = e.next) {
//hash相同&&key值也相同,那么就说明找到了要删除的元素
if (e.hash == hash && key.equals(e.key)) {
//prev==null说明刚开始遍历就找到了元素,那么就说明元素是头结点
if (prev == null) {
//让头节点,变成当前元素的next元素
tab[index] = e.next;
} else {
//prev 是 e的前一个元素,让e的前一个元素的next,指向e的next元素,就完成了删除
prev.next = e.next;
}
modCount++;
size--;
//★子类进行重写★
postRemove(e);
return e.value;
}
}
return null;
}- 查找
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
//key== || hash值相同,key equals也相同
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}小贴士:当我们使用new HashMap()对HashMap进行创建的时候,会同时为我们创建一个长度为2的1次方的HashEntry