在前面的笔记中,我们已经训练出thchs30模型。
这篇文章主要介绍如何用训练好的模型识别我们自己的语音。
一、安装portaudio
首先我们cd到tools下面,执行:./install_portaudio.sh
然后在cd到src下面,执行:make ext
二、创建相关文件
从voxforge把online_demo拷贝到thchs30下,和s5同级,online_demo建online-data和work两个文件夹。online-data下建audio和models,audio放要识别的wav,models建tri1,讲s5下/exp/下的tri1下的final.mdl和35.mdl拷贝过去,把s5下的exp下的tri1下的graph_word里面的words.txt和HCLG.fst也拷过去。(使用tri1训练出来的模型)

其中,final.mdl是训练出来的模型,words.txt是字典,和HCLG.fst是有限状态机。
三、修改脚本
打开online_demo的run.sh
a)将下面这段注释掉:(这段是voxforge例子中下载现网的测试语料和识别模型的。我们测试语料自己准备,模型就是tri1了)
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Downloading test models and data ..."
wget -T 10 -t 3 $data_url;
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Download of $data_file has failed!"
exit 1
fi
fi
b) 然后再找到如下这句,将其路径改成tri1
# Change this to "tri2a" if you like to test using a ML-trained model
ac_model_type=tri2b_mmi
ac_model_type=tri1
c)把识别麦克风语音的代码修改:
online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000 \
--beam=12.0 --acoustic-scale=0.0769 $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
#online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000 \
#--beam=12.0 --acoustic-scale=0.0769 $ac_model/model $ac_model/HCLG.fst \
#$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
d)把识别已经录好的语音代码修改:
online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\--max-active=4000 --beam=12.0 --acoustic-scale=0.0769 \
scp:$decode_dir/input.scp $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
ark,t:$decode_dir/ali.txt $trans_matrix;;
#online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\# --max-active=4000 --beam=12.0 --acoustic-scale=0.0769 \
#scp:$decode_dir/input.scp $ac_model/model $ac_model/HCLG.fst \
#$ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
#ark,t:$decode_dir/ali.txt $trans_matrix;;
4. 在线识别
我们把自己要识别的语音放到/online-data/audio里,cd到online_demo下面,执行./run.sh,就开始识别回放了。
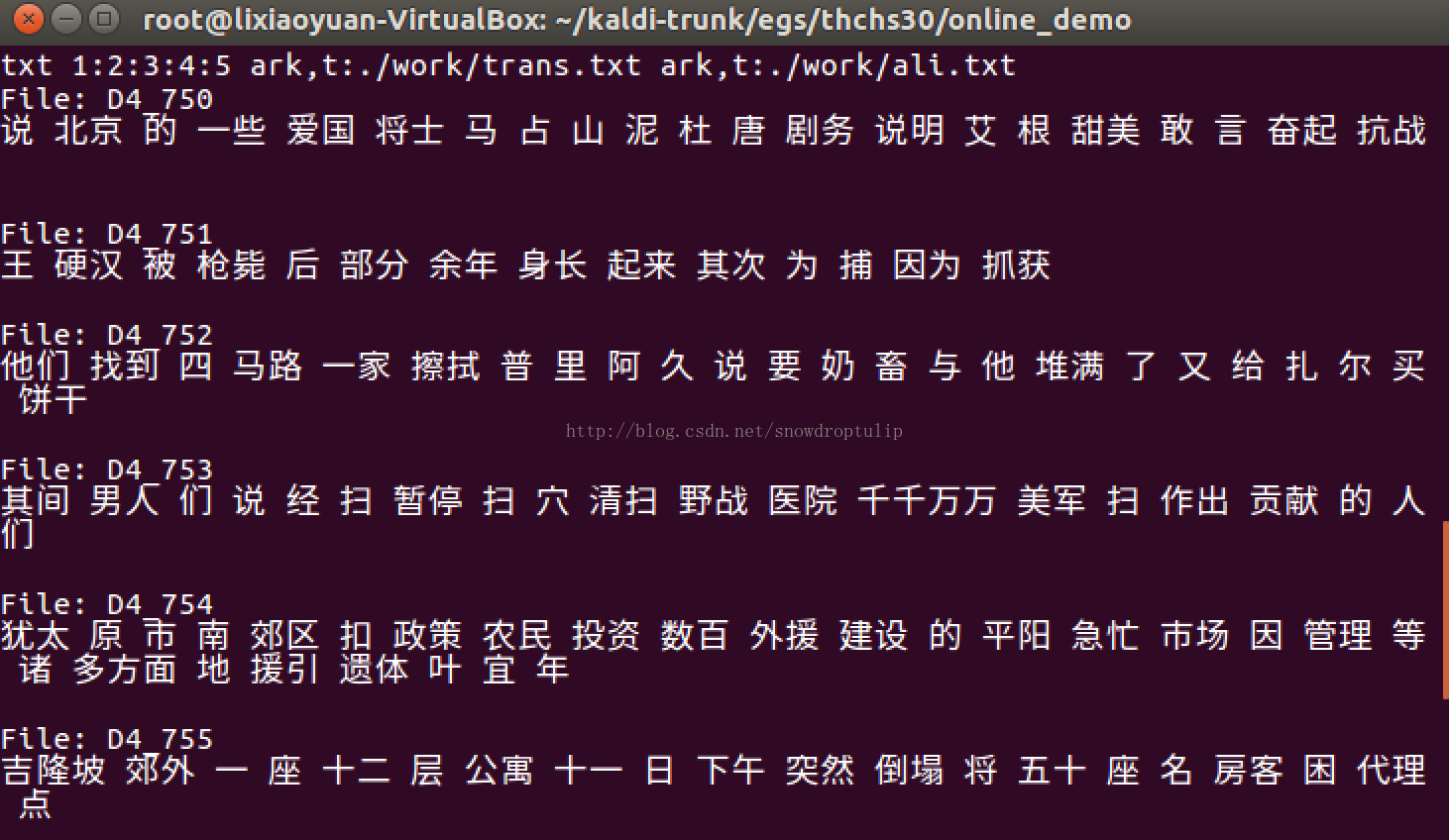
可以看到识别效果非常差。
如果想要识别麦克风的语音,可以执行:./run.sh --test-mode live,也是同样的效果
5. tri2,tri3,tri4在线识别
运行tri2(tri3,tri4同理):把s5下的exp下的tri2b下的12.mat考到models的tri2下,把final.mat考过来(好像是转移矩阵),再拷贝其他相应的文件(同tri1),所以tri2目录下包括如下文件:

在第4步的基础上修改如下内容:
1. 修改ac_model_type
ac_model_type=tri2
2. 修改trans_matrix
ac_model=${data_file}/models/$ac_model_type
trans_matrix="$ac_model/12.mat"
audio=${data_file}/audio
3. 增加--left-context=3 --right-context=3
online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000 \
--beam=12.0 --acoustic-scale=0.0769 --left-context=3 right-context=3 $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\
--max-active=4000 --beam=12.0 --acoustic-scale=0.0769 --left-context=3 --right-context=3\
scp:$decode_dir/input.scp $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
ark,t:$decode_dir/ali.txt $trans_matrix;;
最后执行./run.sh
