转载自:https://blog.csdn.net/qisibajie/article/details/56482182
大数据分析的技术栈
Apache Kafka是一个分布式的流系统。Kafka作为流系统有下面的几个能力:
- 作为消息处理系统,可以和我们EMS里面的Queue和Topic这些做一些类比。
- 可以作为一个存储系统,因为是分布式的结构,所以存储能力是很强的。
- 作为一个流处理系统,实现实时处理的需求。
本片文章主要介绍的是第一个能力,也就是作为消息处理系统的能力。
kafka适合构建什么系统呢?
- 作为一个消息中间件,在不同的程序和系统之间传递消息。
- 构建实时处理消息或者传递消息的实时系统。
为了构建上面两种系统,Kafka提供了四种核心的API。
Kafka核心API
1. Producer API
Producer是Kafka作为消息处理系统的时候,消息的生产者,换句话说这个是生产者send消息相关的API。
2. Consumer API
Consumer是Kafka作为消息处理系统的时候,消息的消费者,所以这个API是接收消息的API。
3. Stream API
这个是Kafka构建实时处理系统的时候需要用的API。
4. Connector API
Connector一般用于连接到数据库,可以实时的检测数据库里面表的change。
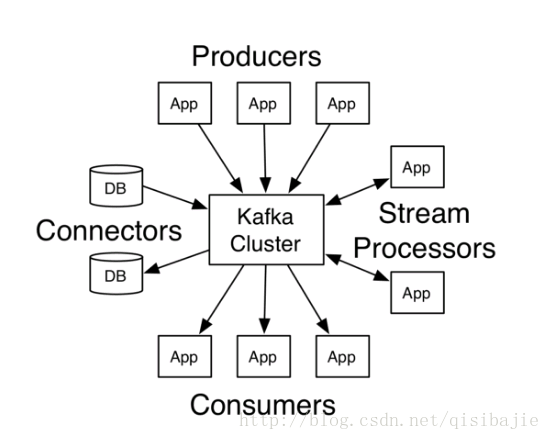
(参考Kafka官方文档)
Kafka的模块
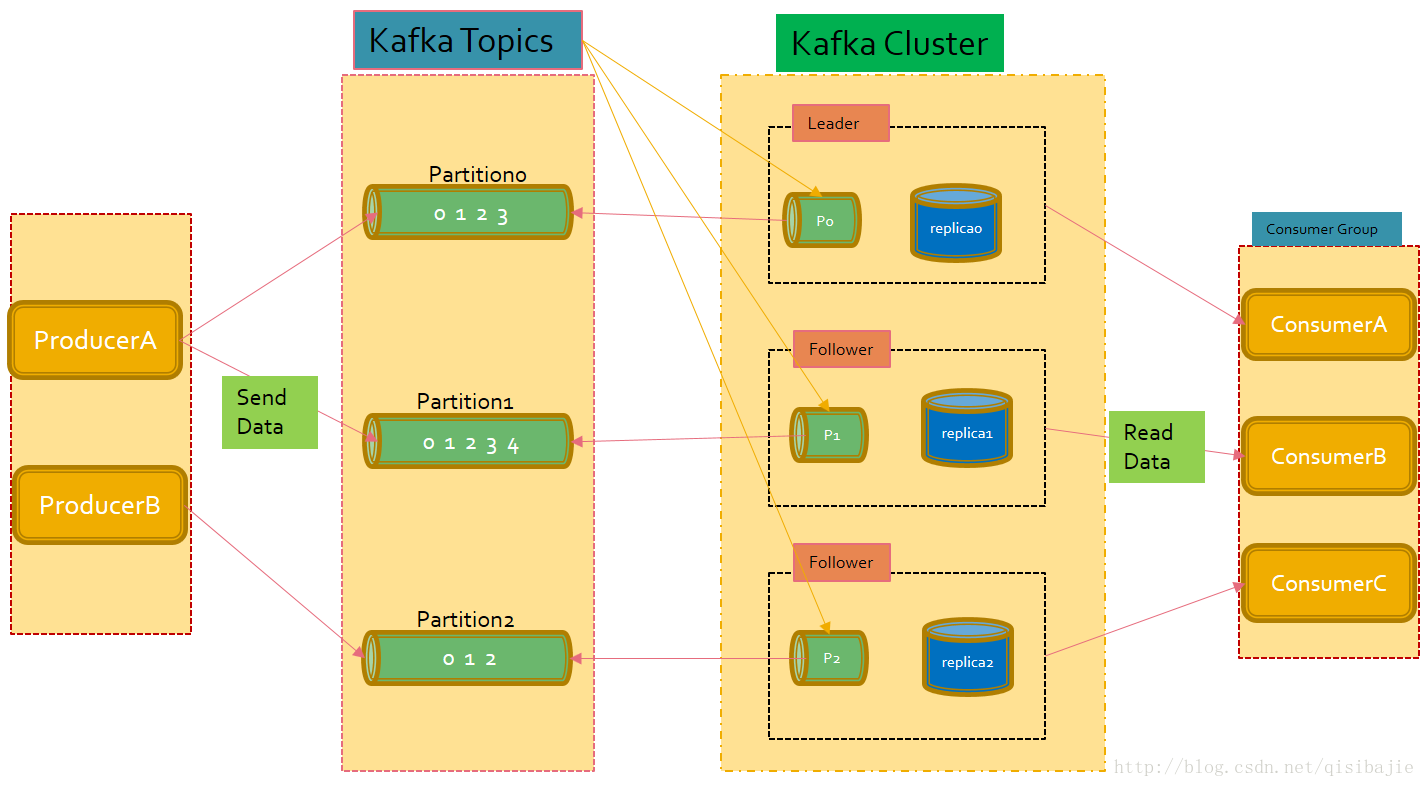
看到这个架构图,有密集恐惧症的可能直接就离开这篇博客了,但是我还是上了这幅图,因为用这张图解释的话,很多概念就会更加的直观。
Producer
这里的Producer是消息的产生者,负责把消息发送到Topic。在实际的项目中,这部分一般是嵌入到我们真正的Application里面,负责收集Application的信息,例如Log,用户操作信息等等。
Topic
在Kafka消息处理系统中,Topic是存储和中转消息的地方,一般是一类信息的统称。Producer把信息发送到不同的Topic里面。等待着消费者去处理。一个Topic会被分为多个Partition,而Partition就是真正存储消息的地方。而Partition的分布是分布式,在上图中Topic被分为了三个Partition,而这三个Partition分布在三个server上面(Leader, Follower, Follower)。每个Partition有一个备份,这是一种容错机制,防止消息的丢失。而每个Topic分为几个Partition,每个Partition有几个备份,这些都是在Topic被创建的时候就确定的。而具体的信息被存储到Partition里面,当Producer发送信息的时候,可以指定消息发送到哪个Partition里面。但是一个消息只会被发送到一个Partition里面。如果你没有指定Partition,相同key的信息会被发送到相同的Partition里面。
Partition
就像上面提到的那样,每个Topic会被分为若干个Partition,Partition是存储消息的实体。消息在Partition里面是怎么存储的呢?
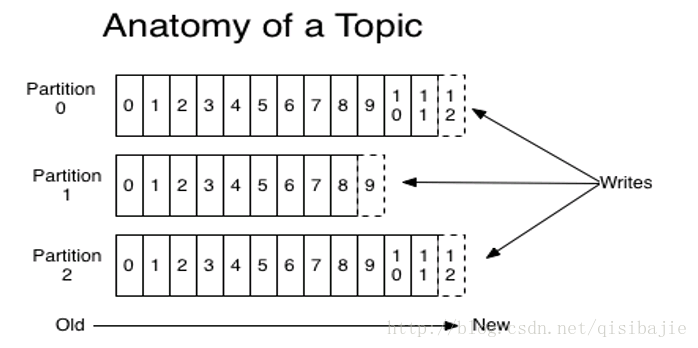
(参开Kafka官方文档)
消息在Partition里面是以Log文件的方式存储的。每来一条信息就会被追加到Log file的结尾,并且会有一个offset去标识这条信息。Offset是每条信息的唯一的标识。同一个Producer发送的信息,在同一个Partition里面也是有先后顺序的。
Kafka Cluster
Kafka是有多个server组成的,每个server被称为一个broker,而多个这样的broker一起就被称为cluster。
Leader
Leader是Kafka中的一个broker,也就是server. 每个Partition都有一个server管理它的read和write,这样的server就被称为这个partition的Leader。
Follower
Follower也是Kafka中的一个broker,它是和leader相对应的,Leader负责Partition的read和write,而Follower则是负责同步leader的信息,如果leader挂了,Follower中的一个就会被举荐为Leader.这是Kafka容错机制的一个重要的方面。
Consumer
在传统的消息处理系统中Queue和Topic都有自己的特性。
Queue:
优点: 能做到很好的负载均衡。
缺点:Queue里面的信息被一个consumer处理后,这条消息就会被消除。因此一条信息只能被一个consumer消费。
Topic:
优点: 每条消息可以被多个consumer消费。
缺点:因为topic里面的信息是被广播给每个消费者,所以没有办法控制规模的。每个consumer都会被动的处理这条消息。
而Kafka Topic可以综合传统的Queue和Topic的优点,避免他们的缺点。它是怎么实现的呢。
1. 增加了customer group的概念,订阅message的时候是以customer group为单位的。
2. 遵循规则,每个Partition只能被group里面的一个consumer消费。
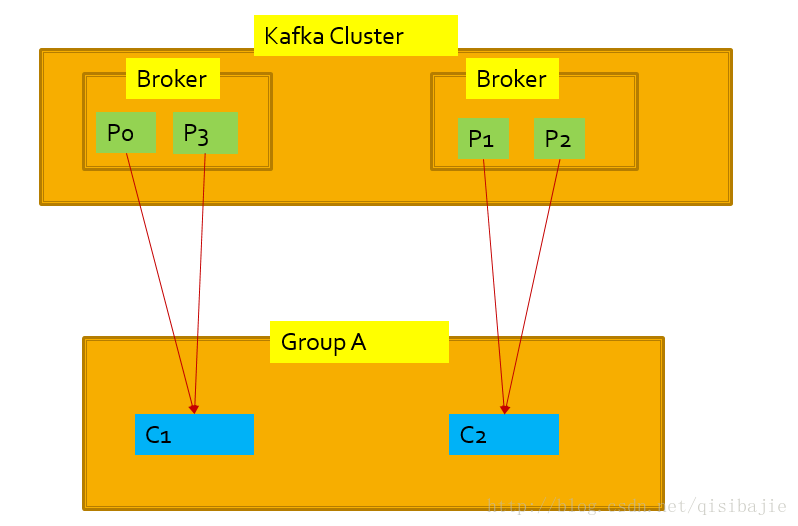
每个consumer都属于相同的group,这种情况下Kafka就类似于传统的Queue,即每个partition只能被一个consumer消费,例如P0只能被C1消费,不能被C2消费。
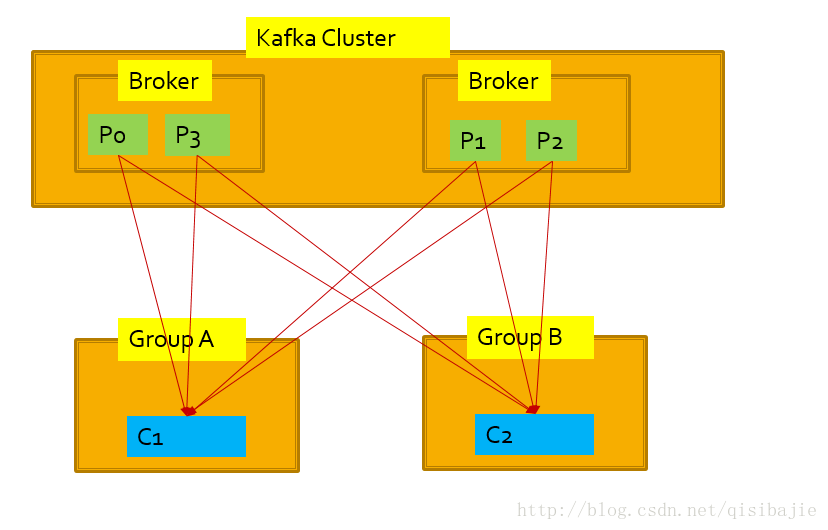
每个consumer都属于不同的group,这种情况下Kafka类似于传统的Topic,每个consumer都必须处理每个Patition的信息。
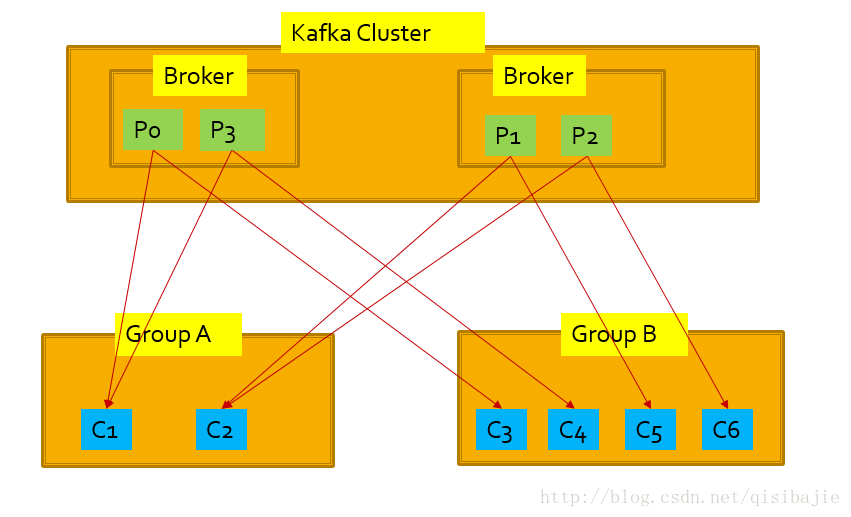
这个才是最佳的情况,以group为单位看,每个group都会收到全部partition的信息,这是传统的Topic的优点,而在每个group里面,这条消息只会被一个consumer消费,这是Queue的特性,实现了负载均衡。这样Kafka Topic就结合了传统的Queue和Topic的优点。
应用场景
- 作为一个消息处理系统。
- 网站用户行为的实时收集。
- 应用程序Log的集中收集。