关联分析算法
一. 关联分析
关联分析是在大规模数据集中寻找有趣关系的任务。包括两方面:频繁项集(经常一起出现的物品的集合)、关联规则(暗示两种物品之间可能存在很强的关系)。
算法涉及的度量标准:
- 支持度(support):某一项集(即本项目中的某个app组合)的支持度为数据集中包含该项集的记录所占比例。(support度量频繁项集)
supportX,Y=PXY=number(XY)number(AllSamples)
- 置信度(confidence):一个数据出现后,另一个数据出现的概率,即数据的条件概率。(confidence度量关联规则)
confidenceYZ⇒X=PX|YZ=support(XYZ)support(YZ)
二. Apriori算法
- Apriori算法原理:
假设我们有一家经营着4种商品(商品0,商品1,商品2和商品3)的杂货店。图1显示了所有商品之间所有的可能组合. 对于单个项集的支持度,我们可以通过遍历每条记录并检查该记录是否包含该项集来计算。对于包含N种物品的数据集共有2N-1 种项集组合,重复上述计算过程是不现实的。
Apriori原理,可以帮助我们减少计算量。Apriori原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。更常用的是它的逆否命题,即如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
如图2中,已知阴影项集{2,3}是非频繁的。利用这个知识,我们就知道项集{0,2,3},{1,2,3}以及{0,1,2,3}也是非频繁的。也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁的后,就可以紧接着排除{0,2,3}、{1,2,3}和{0,1,2,3}。
Apriori算法从单元素项集开始,通过组合满足最小支持度的项集来形成更大的集合。



图1 集合{0,1,2,3,4}中所有可能的项集 图2 所有可能集合,非频繁的用灰色表示
2. Apriori算法挖掘频繁项集
Apriori算法采用了迭代的方法,先搜索出候选1项集及对应的支持度,剪枝去掉低于支持度的1项集,得到频繁1项集。然后对剩下的频繁1项集进行连接,得到候选的频繁2项集,筛选去掉低于支持度的候选频繁2项集,得到真正的频繁二项集,以此类推,迭代下去,直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果。
可见这个算法还是很简洁的,第i次的迭代过程包括扫描计算候选频繁i项集的支持度,剪枝得到真正频繁i项集和连接生成候选频繁i+1项集三步


图3 Apriori算法流程 图4 Apriori算法流程举例
3. Apriori算法挖掘关联规则
图5给出了从项集{0,1,2,3}产生的所有关联规则,其中阴影区域给出的是低可信度的规则。可以发现如果{0,1,2}➞{3}是一条低可信度规则,那么所有其他以3作为后件(箭头右部包含3)的规则均为低可信度的。可以观察到,如果某条规则并不满足最小可信度要求,那么该规则的所有子集也不会满足最小可信度要求。可以利用关联规则的上述性质属性来减少需要测试的规则数目,类似于Apriori算法求解频繁项集。

图5 关联规则集合,不满足置信度的用灰色表示
4.总结
关联分析是用于发现大数据集中元素间有趣关系的一个工具集,可以采用两种方式来量化这些有趣的关系。第一种方式是使用频繁项集,它会给出经常在一起出现的元素项。第二种方式是关联规则,每条关联规则意味着元素项之间的“如果……那么”关系。
发现元素项间不同的组合是个十分耗时的任务,不可避免需要大量昂贵的计算资源,这就需要一些更智能的方法在合理的时间范围内找到频繁项集。能够实现这一目标的一个方法是Apriori算法。Aprior算法是一个非常经典的频繁项集的挖掘算法,Apriori原理是说如果一个元素项是不频繁的,那么那些包含该元素的超集也是不频繁的。每次增加频繁项集的大小,Apriori算法都会重新扫描整个数据集。当数据集很大时,这会显著降低频繁项集发现的速度。
三. FP-growth算法
FP-growth算法基于Apriori构建,但采用了高级的数据结构减少扫描次数,大大加快了算法速度。FP-growth算法只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法的速度要比Apriori算法快。其缺点是实现比较困难,在某些数据集上性能会下降;适用数据类型为离散型数据。
1. FP-growth数据结构
为了减少I/O次数,FP-growth算法引入了一些数据结构来临时存储数据。这个数据结构包括三部分,第一部分是一个项头表,里面记录了所有的1项频繁集出现的次数,按照次数降序排列;第二部分是FP Tree,它将原始数据集映射到了内存中的一颗FP树;第三部分是节点链表。所有项头表里的1项频繁集都是一个节点链表的头,它依次指向FP树中该1项频繁集出现的位置。这样做主要是方便项头表和FP Tree之间的联系查找和更新。

图6 FP-growth三种数据结构
2. 项头表的建立
第一次扫描数据,得到所有1项集的的计数。然后删除支持度低于阈值的项,将1项集放入项头表,并按照支持度降序排列。接着第二次也是最后一次扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。我们用下面这个例子来具体讲解。
假设我们有10条数据,首先第一次扫描数据并对1项集计数,我们发现F,O,I,L,J,P,M, N都只出现一次,支持度低于20%的阈值,因此他们不会出现在下面的项头表中。剩下的A,C,E,G,B,D,F按照支持度的大小降序排列,组成了我们的项头表。接着我们第二次扫描数据,对于每条数据剔除非频繁1项集,并按照支持度降序排列。比如数据项ABCEFO,里面O是非频繁1项集,因此被剔除,只剩下了ABCEF。按照支持度的顺序排序,它变成了ACEBF。其他的数据项以此类推。将原始数据集里的频繁1项数据项进行排序,这是为了后面的FP树的建立时,可以尽可能的共用祖先节点。

图7 项头表及排序后数据集
3. FP-tree的建立
开始时FP树没有数据,建立FP树时我们一条条的读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
用第二节的例子来描述。首先,我们插入第一条数据ACEBF,如下图所示。此时FP树没有节点,因此ACEBF是一个独立的路径,所有节点计数为1, 项头表通过节点链表链接上对应的新增节点。接着我们插入数据ACG,如下图所示。由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。当然,对应的G节点的节点链表要更新。


图8(a) 插入ACEBF 图8(b) 插入ACG
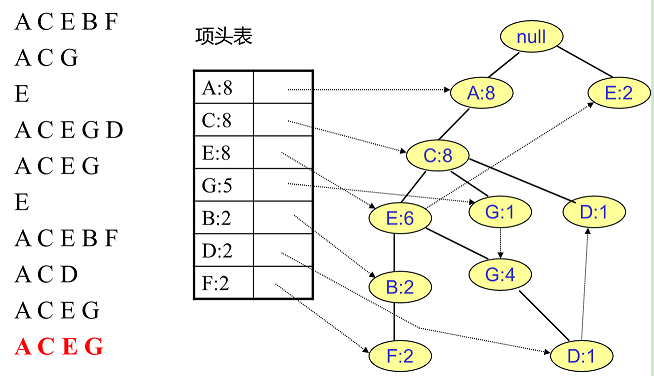
图8(c) 插入全部10条记录
4. FP-tree的挖掘
得到了FP树和项头表以及节点链表,我们首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,我们要找到它的条件模式基。
所谓条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,我们就可以递归挖掘得到频繁项集了。
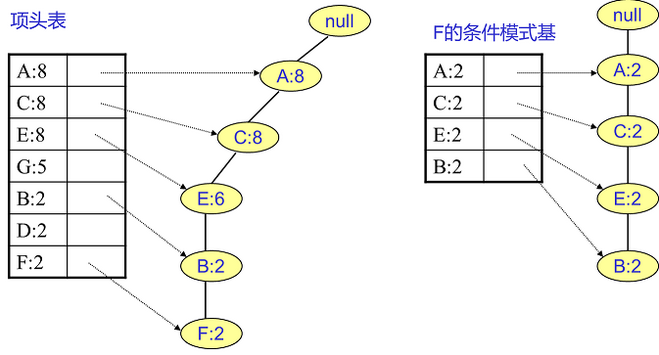
以上面的例子来讲解。我们看看先从最底下的F节点开始,我们先来寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2, F:2}。我们接着将所有的祖先节点计数设置为叶子节点的计数,即FP子树变成{A:2,C:2,E:2,B:2, F:2}。一般我们的条件模式基可以不写叶子节点,因此最终的F的条件模式基如图所示。
通过它,我们很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},...还有一些频繁三项集,就不写了。当然一直递归下去,最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}。
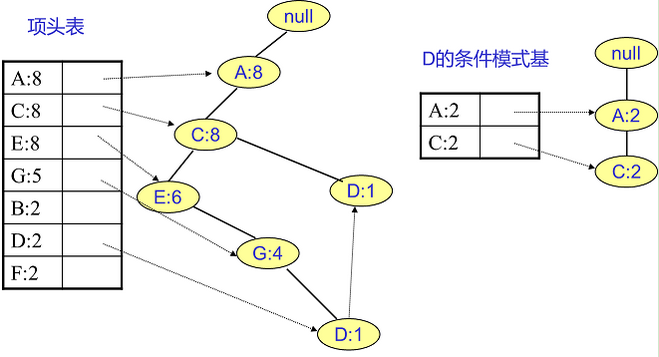
F挖掘完了,我们开始挖掘D节点。D节点比F节点复杂一些,因为它有两个叶子节点,因此首先得到的FP子树如下图左。我们接着将所有的祖先节点计数设置为叶子节点的计数,即变成{A:2, C:2,E:1 G:1,D:1, D:1}此时E节点和G节点由于在条件模式基里面的支持度低于阈值,被我们删除,最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}。通过它,我们很容易得到D的频繁2项集为{A:2,D:2}, {C:2,D:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,D:2}。D对应的最大的频繁项集为频繁3项集。以此类推。
5. FP-growth算法流程
1)扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。
2)扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
3)读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
4)从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项的频繁项集。
5)如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。
6. 总结
FP-growth算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构。利用内存数据结构以空间换时间是常用的提高算法运行时间瓶颈的办法。
四. Relim算法
FP-growth算法是当前挖掘频繁项集算法中速度最快,应用最广,并且不需要候选项集的一种频繁项集挖掘算法,但是FP-growth也存在着算法结构复杂和空间利用率低等缺点。Relim算法是在FP-growth算法的基础上提出的一种新的不需要候选项集的频繁项集挖掘算法。它具有算法结构简单,空间利用率高,易于实现等显著优点。
Relim vs.FP-growth
相同:仅需扫描数据集两次
基于递归搜索
不产生候选项集
不同:FP-growth创建频繁模式树
Relim建立事务链表组
1.Relim算法步骤
1)如FP-growth的第一步,两次扫描原始数据,剔除非频繁一项集,并按支持度升序排列每一项。
2)将排序后的每条数据插入链表组。
3)如以e开头的链表可生成频繁项{e,c:2},{e,d:2},{e,b:2},挖掘完后删除该链表,创建e的前缀链表组,并将其与删除e开头的链表合并,再次进行挖掘。如此递归。

图11 原始数据(left)和删除非频繁项及按升序排序后的数据(right)

图12 Relim算法流程

2. Relim/ FP-growth算法性能比较
1)算法结构:由以上所述,显而易见Relim算法的结构比FP-growth算法简单。该算法没有复杂的数据结构,因而易于实现。
2)空间利用率:FP-growth算法主要是通过建立频繁模式树来实现关联规则挖掘。频繁模式树从挖掘开始时建立,一直到挖掘结束时都完整地保存在内存里。而Relim算法主要是通过建立事务链表组来实现挖掘的,事务链表组中的事务链表依次地被挖掘。当一个事务链表中的关联项集被挖掘完后,此事务链表就被删除,所占的内存空间也就被释放。由此可见,Relim算法的空间利用率比FP-growth算法的要高很多。
3)运行速度:Relim算法的运行速度与FP-growth算法相比并不慢,而且当对最小支持度高或者频繁规则比较少的数据集进行挖掘时,Relim算法的运行速度往往比FP-growth算法要快。由此,对最小支持度高或者频繁规则比较少的数据集进行数据挖掘时,用Relim 算法可以节约大量的运算时间。
4)计算复杂度:Relim算法在挖掘长模式的数据库时计算复杂,因此,只适合于挖掘短模式的数据库。如果,要将其用于长模式的数据库挖掘,则通过数据库分解方法将长模式变成短模式可能是一个可行的方法。
五. 参考资料
[1] https://www.cnblogs.com/qwertWZ/p/4510857.html
[2] https://zhuanlan.zhihu.com/p/30033395
[3] Keeping things simple: finding frequent item sets by recursive elimination
[4] 一个新的不需要候选集的挖掘关联规则算法—Relim算法的研究
[5] 机器学习实战
[6] 数据挖掘导论
[7] 数据挖掘:概念与技术(第03版)