solr的简单使用
M:solr是干嘛用的呢?
D:Solr是一个独立的企业级搜应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。solr将非结构化数据,通过分词、词法分析、过滤停词、语义分析等手段来转成结构化数据,存储为索引。
Z:就是说,solr是一种全网搜索,但是其还支持语义相同的关键词。(例如:搜索solr,却可以查询出来lucene内容)
M:那安装solr服务器需要配置什么环境呢?
Z:jdk、tomcat 、IK Analyzer。
M:jdk怎么安装配置呢?
Z:1. 首先下载jdk安装包jdk-7u55-linux-i586.tar.gz。
然后解压到指定的文件夹下
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /usr/lib/jvm配置环境变量
vim /etc/sysconfig/network-scripts/ifcfg-eth0export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_55 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH执行profile
source /etc/profile即可检查jdkjava -version是否安装成功了。
M:tomcat安装在哪里呢?
Z:/usr/local/solr/tomcat
M:那命令为:tar -zxvf apache-tomcat-7.0.47.tar.gz -C /usr/local/solr/tomcat ,如果没有文件夹需要创建指定文件夹。
M:那现在可以安装solr了吧,solr安装到哪里呢?
Z:这个安装的方式可有点不同,具体操作是把/dist/solr-4.10.3.war复制到tomcat的webapps下,运行tomcat进行自动解压。(运行bin下的startup.sh)
M:为什么我启动的时候报错:tomcat Neither the JAVA_HOME nor the JRE_HOME environment variable is defined
Z:因为你使用的jdk不是通过yum安装的,而是下载拉进去的,虽然也配置了java_home,但tomcat不太智能,仍然没有自动识别出java_home路径。所以需要编辑文件,tomcat下的catalina.shtomcat/bin/catalina.sh,添加以下两行代码在开头处:
# -----------------------------------------------------------------------------
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_55
export JRE_HOME=/usr/lib/jvm/jdk1.7.0_55/jreM:如果要看tomcat的启动情况怎么做?
Z:可以用tail -f logs/catalina.out查看日志。
M:那tomcat要怎么关闭呢?
Z: 执行bin下的shutdown.sh,顺便说一下,war包的删除需要关闭tomcat。
M:除了war包,还需要别的什么吗?
Z:还有 jar包 & 配置文件
- 把
solr-4.10.3/example/lib/ext下的jar包复制到webapps的/webapps/solr-4.10.3/WEB-INF/lib中。 - 拷贝log4j.properties文件,在Tomcat下webapps\solr\WEB-INF目录中创建文件 classes文件夹,复制Solr目录下
example\resources\log4j.properties至Tomcat下webapps\solr\WEB-INF\classes目录。 - 把
solr-4.10.3/example/下的solr拷贝到/usr/local/solr/solrhome与tomcat同级的目录下:cp -r solr /usr/local/solr(文件夹需要添加-r)
M:但是solr工程怎么知道自己的配置文件在哪里呢?
Z:所以需要修改solr工程的web.xml文件,配置JNDI,指向配置文件的目录
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solr/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>M:完成之后怎么测试呢?
Z:linux中启动tomcat,然后进行访问8080/solr看看有没有solr页面,有则搭建成功了。
M:但是为什么我现在显示当前机子无法访问目标主机呢?
Z:你可以尝试使用Nat自动获取ip的方式,如果这样可以ping得通的话,就可以启动后进行访问了(记得修改解压文件夹名为solr)。
M:安装完solr之后要怎么使用呢?
Z:需要先配置中文分析器,再配置业务字段。
M:什么是中文分析器?
Z:中文分词器 IK Analyzer 。例如输入 基于java语言开发的轻量级的中文分词工具包,可以自动切割为基于|java|语言|开发|的|轻量级|的|中文|分词|工具包|。
M:IK Analyzer怎么安装呢?
Z:安装IK Analyzer步骤如下
需要把IK Analyzer 的jar包
IKAnalyzer2012FF_u1.jar添加到solr工程的lib文件夹下。拷贝IK Analyzer 的配置文件
IKAnalyzer.cfg.xml,相关字典ext_stopword.dic,mydict.dic到WEB-INF的classes文件夹下,如果没有该文件夹,新建一个。配置文件配置fieldType,位置在
/solrhome/collection1/conf/schema.xml<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
M:那业务字段要怎么配置呢?
Z:首先要确定配置哪些字段。
M:那要怎么判断这字段需不需要配置呢?
Z:判断标准 1.搜索时是否需要该字段 2.后序业务用到不
需要用到字段如下
商品id
商品title
卖点
价格
商品图片
商品分类名称
商品描述M:添加在哪里呢?
Z:之前的schema.xml文件中
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="long" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" />
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>M:name对应的是id,stored是什么意思?
Z:stored为true的时候表示存储,存储不存储根据是否搜索该信息决定,desc描述只用于展示,所以不需要存储。
M:下面的copyField是什么,有什么作用?
Z:复制域,是一种优化方式。把其他域复制到一块域上,更便于搜索。
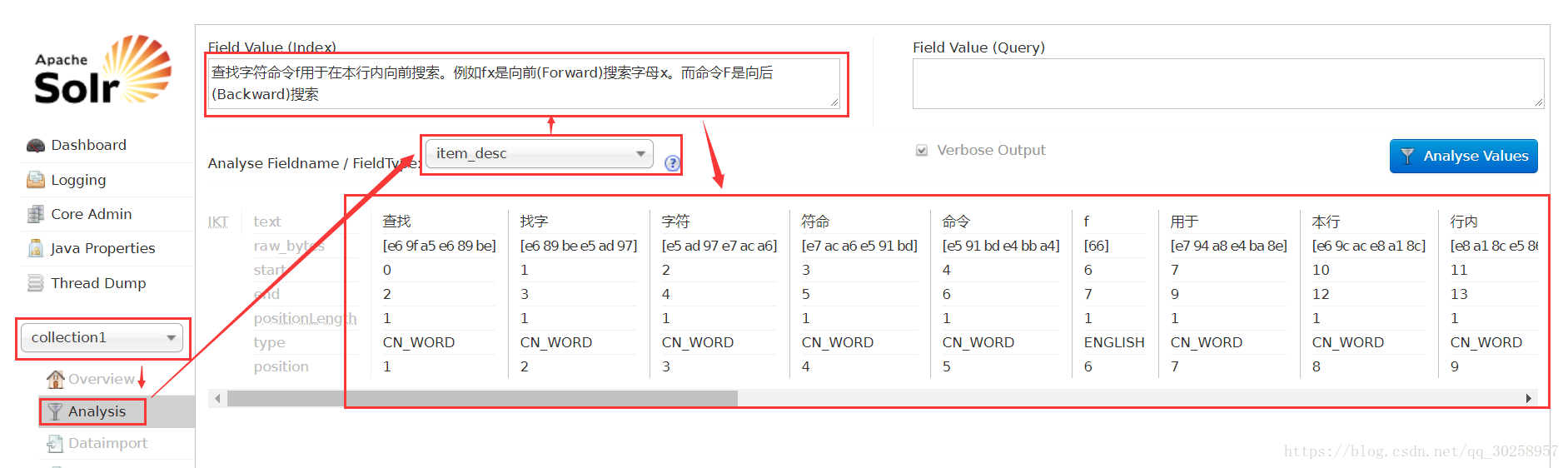
M:那怎么测试业务字段是否配置成功呢?
Z:选择colletion1,如果FieldType下拉框中有添加的业务字段,并且对中文成功分割,则说明IK Analyzer中文分析器已配置成功。
M:怎么进行索引库的添加、删除、修改 ?
Z:solr命令
1. 删除 :``<delete><id>001</id></delete>`` ,``<delete><query>*:*</query></delete>`` 删除之后需要进行提交 ``<commit/>``
2. 查询:``<query>*:*</query>``
M:为什么没有修改呢?
Z:修改就是重新添加一次,只要id一样,内容就会被更新。
M:那要怎么将数据存进索引库中呢?不会是一条一条写进去吧。
Z:可以通过写java代码实现数据的导入。
M:那用到什么东西呢?
Z:需要用到solrJ客户端,所以要在maven工程中添加依赖。(parent统一管理中能找到)
<!-- solr客户端 -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
</dependency>M:solrJ怎么做数据导入呢?
Z:使用solrServer对象提交solr文档对象
@Test
public void addDocument() throws SolrServerException, IOException {
//创建连接
SolrServer solrServer = new HttpSolrServer("http://192.168.175.129:8080/solr");
//创建文档对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "test001");
document.addField("item_title", "测试商品1");
document.addField("item_price", 12345);
//文档对象写入索引库
solrServer.add(document);
//提交
solrServer.commit();
}M:那要怎么知道自己的索引是否导入成功呢?
Z:只要打开solr界面进行查询就可以了。
M:那删除的方法呢?
Z:删除有多种操作方式,可以通过id,id List,甚至query语句
@Test
public void deleteDocument() throws SolrServerException, IOException{
//创建连接
SolrServer solrServer = new HttpSolrServer("http://192.168.175.129:8080/solr");
// solrServer.deleteById("001"); //通过id删除
solrServer.deleteByQuery("*:*"); //通过语句删除
solrServer.commit();
}M:大量的数据信息导入,要怎么做数据库跟索引库的对接呢?
Z:就是一个从数据库取出来,存到索引库的过程
@Override
public TaotaoResult importAllItems(){
try {
//查询商品列表
List<Item> list = itemMapper.getItemList();
//商品信息写入索引库
for (Item item:list) {
//创建文档对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", item.getId());
document.addField("item_title", item.getTitle());
document.addField("item_sell_point", item.getSell_point());
document.addField("item_price", item.getPrice());
document.addField("item_image", item.getImage());
document.addField("item_category_name", item.getCategory_name());
document.addField("item_desc", item.getItem_des());
// //创建连接
// SolrServer solrServer = new HttpSolrServer("http://192.168.175.129:8080/solr");
solrServer.add(document);
}
solrServer.commit();
} catch (Exception e) {
e.printStackTrace();
return TaotaoResult.build(500, ExceptionUtil.getStackTrace(e));
}
return TaotaoResult.ok();
}pojo对象
private String id; private String title; private String sell_point; private long price; private String image; private String category_name; private String item_des;mapper层
public interface ItemMapper { List<Item> getItemList(); }<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.taotao.search.mapper.ItemMapper" > <select id="getItemList" resultType="com.taotao.search.pojo.Item"> SELECT a.id, a.title, a.sell_point, a.price, a.image, b. NAME category_name FROM tb_item a LEFT JOIN tb_item_cat b ON a.cid = b.id </select> </mapper>
M:SolrServer对象不new,那怎么获取到呢?
Z:通过Spring容器注入进来,需要在spring配置文件中新增-solr的配置文件,注入方式如下:
<!-- 单机版 -->
<bean id="httpSolrServer" class="org.apache.solr.client.solrj.impl.HttpSolrServer">
<constructor-arg name="baseURL" value="${SOLR.SERVER.URL}"></constructor-arg>
</bean>${变量}可以从指定的配置文件中获取对应值
M:这个注入的xml是怎么配置的呢?
Z:其实就是调用某个类的构造方法,传值进去。
因为是new HttpSolrServer,所以指定org.apache.solr.client.solrj.impl.HttpSolrServer类。然后该类的构造方法有一个baseURL的属性,我们将其赋值为${SOLR.SERVER.URL}
public HttpSolrServer(String baseURL) {
this(baseURL, null, new BinaryResponseParser());
}M:为什么solr要单独做一个服务呢?
Z:因为solr搜索可能有高负载的问题,单独分离出来便于分布式部署。
M:rest(商品数据获取工程)有redis,solr需要redis吗?
Z:不需要,因为solr里面自带有缓存。
M:需要依赖什么项目,怎么确定呢?
Z:因为不需要对数据进行维护,只是导入而已,所以不需要依赖mapper工程。但是可能会用到common工程的工具,所以依赖common工程。
<dependencies>
<dependency>
<groupId>com.taotao</groupId>
<artifactId>taotao-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>需要依赖的jar包
spring:到处用到
springmvc:发布服务
solrj:操作solr
mybatis:查询语句。为了方便,可以修改直接依赖
taotao-manager-mapper工程,它本身就已经依赖了common工程<dependencies> <dependency> <groupId>com.taotao</groupId> <artifactId>taotao-manager-mapper</artifactId> <version>0.0.1-SNAPSHOT</version> </dependency> </dependencies>
用到mapper需要配置资源扫描
<!-- 如果不添加此节点mybatis的mapper.xml文件都会被漏掉。 -->
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
</build>M:为什么要添加两个资源扫描?
D:比如mybatis的mapper.xml文件,我们习惯把它和Mapper.java放一起,都在src/main/java下面,这样利用maven打包时,就需要修改pom.xml文件,来把mapper.xml文件一起打包进jar或者war里了,否则,这些文件不会被打包的。(maven认为src/main/java只是java的源代码路径)
Z:当只配置src/main/java的时候,默认的src/main/resources就会获取不到,所以需要同时配置src/main/resources。
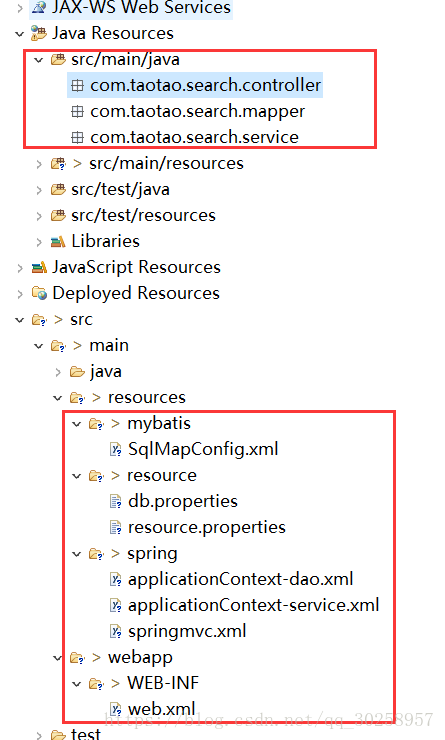
M:除了依赖,还需要什么配置文件呢?
Z:配置文件大致如下
webapp下的
WEB-INF/web.xmlmybatis配置文件
spring控制dao的配置文件,添加扫描包
<!-- 配置扫描包,加载mapper代理对象 --> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.taotao.mapper,com.taotao.search.mapper"></property> </bean>spring控制service的文件,修改扫描包
springmvc.xml,也就是spring控制controller的文件,修改扫描包
M:为什么不需要spring的trans事务配置文件?
Z:只有在对数据库维护的时候才需要事务,这里只是单方面查询。
M:整合后的目录结构如下:
M:怎么导入成功呢?
Z:运行对应Controller,返回200即成功导入
M:为什么页面访问一直404报错?
Z:地址存在问题。
确定地址的三元素,地址 = tomcat的server.xml + 项目的web.xml + Controller的RequestMapping地址
tomcat的server.xml
<Context docBase="taotao-search" path="/" reloadable="true" source="org.eclipse.jst.jee.server:taotao-search"/></Host>
web.xml
<servlet-mapping>
<servlet-name>taotao-search</servlet-name>
<url-pattern>/search/*</url-pattern>
</servlet-mapping>最终地址示例如:http://localhost:8084/search/manager/importall
M:用java代码我要怎么将数据提取出来呢?
Z:可以使用solrServer的方法,进行部分提取
@Test
public void queryDocument() throws Exception {
SolrServer solrServer = new HttpSolrServer("http://192.168.175.129:8080/solr");
//创建一个查询对象
SolrQuery query = new SolrQuery();
//设置查询条件
query.setQuery("*:*");
query.setStart(0); //开始页
query.setRows(6); //显示行数
//执行查询
QueryResponse response = solrServer.query(query);
//取查询结果
SolrDocumentList solrDocumentList = response.getResults(); //获取对象列表
System.out.println("共查询到记录:" + solrDocumentList.getNumFound());
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id")); //获取指定属性
System.out.println(solrDocument.get("item_title"));
System.out.println(solrDocument.get("item_price"));
System.out.println(solrDocument.get("item_image"));
}
}M:数据已经知道怎么提取,那在代码中,要怎么使用呢?
Z:编写dao层,取出SolrQuery对象,并对其进行高亮,封装成Item处理。
public SearchResult search(SolrQuery query) throws SolrServerException {
//返回值对象
SearchResult result = new SearchResult();
//根据查询条件查询索引库
QueryResponse queryResponse = solrServer.query(query);
//取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
//取查询结果总数量
result.setRecordCount(solrDocumentList.getNumFound());
//商品列表
List<Item> itemList = new ArrayList<>();
//取高亮显示
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
//取商品列表
for (SolrDocument solrDocument : solrDocumentList) {
//创建一商品对象
Item item = new Item();
item.setId((String) solrDocument.get("id"));
//取高亮显示的结果
List<String> list = highlighting.get(solrDocument.get("id")).get("item_title");
String title = "";
if (list != null && list.size()>0) {
title = list.get(0);
} else {
title = (String) solrDocument.get("item_title");
}
item.setTitle(title);
item.setImage((String) solrDocument.get("item_image"));
item.setPrice((long) solrDocument.get("item_price"));
item.setSell_point((String) solrDocument.get("item_sell_point"));
item.setCategory_name((String) solrDocument.get("item_category_name"));
//添加的商品列表
itemList.add(item);
}
result.setItemList(itemList);
return result;
}M:这个取高亮是怎么回事?
Z:solr在查询之后会返回一些高亮的标记数据,这里就是将高亮的数据拿出来,存进title里。
//取高亮显示的结果
List<String> list = highlighting.get(solrDocument.get("id")).get("item_title");
String title = "";
if (list != null && list.size()>0) {
title = list.get(0);
} else {
title = (String) solrDocument.get("item_title");
}效果如:"title":"金国威(SanCup)D600荣耀 老人<em style=\"color:red\">手机</em>移动/联通2G<em style=\"color:red\">手写手机</em> 双卡双待 褐咖啡"
M:SearchResult是怎么来的呢?
Z:用来存储相关的属性信息而定义的
public class SearchResult {
//商品列表
private List<Item> itemList;
//总记录数
private long recordCount;
//总页数
private long pageCount;
//当前页
private long curPage;
...Z:在Service处理业务逻辑,指定起始页、高亮等
public SearchResult search(String queryString, int page, int rows) throws Exception {
//创建查询对象
SolrQuery query = new SolrQuery();
//设置查询条件
query.setQuery(queryString);
//设置分页
query.setStart((page - 1) * rows);
query.setRows(rows);
//设置默认搜素域
query.set("df", "item_keywords");
//设置高亮显示
query.setHighlight(true);
query.addHighlightField("item_title");
query.setHighlightSimplePre("<em style=\"color:red\">");
query.setHighlightSimplePost("</em>");
//执行查询
SearchResult searchResult = searchDao.search(query);
//计算查询结果总页数
long recordCount = searchResult.getRecordCount();
long pageCount = recordCount / rows;
if (recordCount % rows > 0) {
pageCount++;
}
searchResult.setPageCount(pageCount);
searchResult.setCurPage(page);
return searchResult;
}M:为什么要设置高亮显示呢?
Z:高亮显示的样式标签是可以由用户自己定义的。
M:那前端拿到searchResult,要怎么使用呢?
Z:筛选值为必填,开始页与行设默认值
@RequestMapping(value="/query", method=RequestMethod.GET)
@ResponseBody
public TaotaoResult search(@RequestParam("q")String queryString,
@RequestParam(defaultValue="1")Integer page,
@RequestParam(defaultValue="60")Integer rows) {
//查询条件不能为空
if (StringUtils.isBlank(queryString)) {
return TaotaoResult.build(400, "查询条件不能为空");
}
SearchResult searchResult = null;
try {
searchResult = searchService.search(queryString, page, rows);
} catch (Exception e) {
e.printStackTrace();
return TaotaoResult.build(500, ExceptionUtil.getStackTrace(e));
}
return TaotaoResult.ok(searchResult);
}将查询的结果封装为TaotaoResult的Object属性中进行返回。
M:执行的时候报扫不到dao怎么办?
Z:介绍一下一种新的扫描方式
<context:component-scan base-package="com.taotao.search">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>与之前不同的是,它并非指定哪个包进行扫描。而是指定一堆包进行扫描,然后筛选排除表达式为Controller的注解。
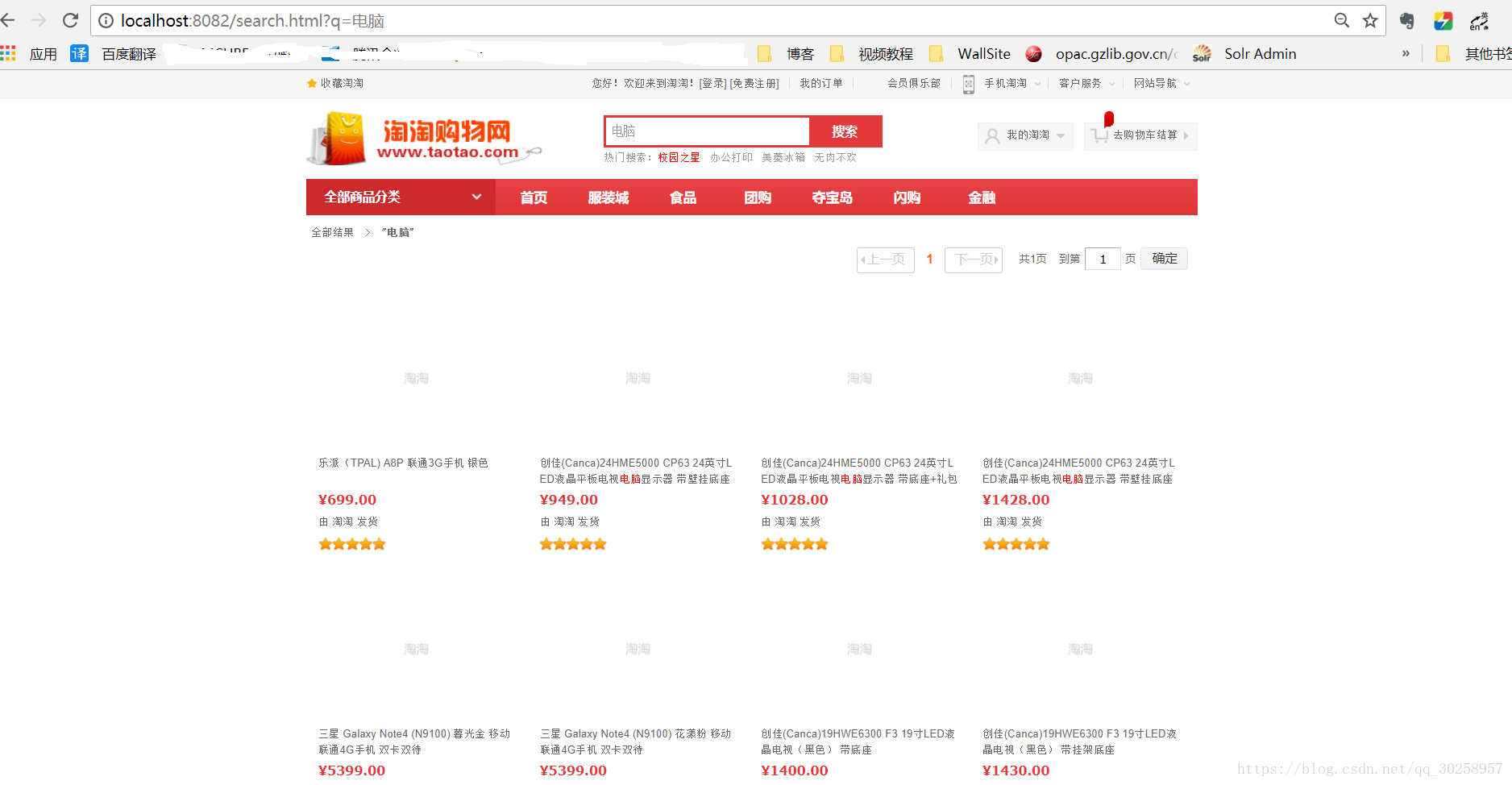
M:通过访问http://localhost:8084/search/query?q=%E6%89%8B%E6%9C%BA&page=2&rows=10,获取到了数据。但是听说get请求可能会产生乱码,怎么办呢?
Z:解决get乱码方法new String(ptype.getBytes("iso8859-1"),"utf-8");
D:我觉得上边的文章有点不详细,需要进行改进。缩小知识点到最小单位,再进行研究。
M:工程接口已经实现好了,那怎么调用search服务用到前台项目中呢?
Z:使用portal工程调用search工程进行搜索,将返回的json数据(TaotaoResult包SearchResult包List< Item> )转化为java对象,传到前端进行渲染。
M:搜索框的前端触发怎么做?
Z:编写 鼠标离开事件 和 回车事件(event.keyCode==13)
<div class="form">
<input type="text" class="text" accesskey="s" id="key" autocomplete="off" onkeydown="javascript:if(event.keyCode==13) search('key');">
<input type="button" value="搜索" class="button" onclick="search('key');return false;" clstag="homepage|keycount|home2013|03a">
</div>js方法对服务进行调用:(需要加html,因为web.xml对*.html后缀进行扫描)
function search(a) {
var b = "http://localhost:8082/search.html?q=" + encodeURIComponent(document.getElementById(a).value);
return window.location.href = b;
}调用的对象是本项目的Controller:
@RequestMapping("/search")
public String search(@RequestParam("q")String queryString,@RequestParam(defaultValue="1")Integer page, Model model){
/* if(queryString != null){
try {
queryString = new String(queryString.getBytes("iso8859-1"),"utf-8");
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}*/
SearchResult searchResult = searchService.search(queryString, page);
//向页面传递参数
model.addAttribute("query", queryString);
model.addAttribute("totalPages", searchResult.getPageCount());
model.addAttribute("page", page);
model.addAttribute("itemList", searchResult.getItemList());
return "search"; //返回逻辑视图
}Service层:
@Override
public SearchResult search(String queryString, int page) {
//调用taotao-search服务
//查询参数
Map<String, String> param = new HashMap<String,String>();
param.put("q", queryString);
param.put("page", page + "");
try {
//调用服务
String json = HttpClientUtil.doGet(SEARCH_BASE_URL,param);
//字符串转化为java对象
TaotaoResult taotaoResult = TaotaoResult.formatToPojo(json, SearchResult.class);
if(taotaoResult.getStatus() == 200){
SearchResult result = (SearchResult) taotaoResult.getData();
return result;
}
} catch (Exception e) {
// TODO: handle exception
}
return null;
}这个Service不对数据库直接进行操作,而是用HttpClientUtil调用接口来获取数据
M:encodeURIComponent()方法是干嘛用的?
Z:encodeURIComponent() 函数可把字符串作为 URI 组件进行编码。
效果如下:
<script type="text/javascript">
document.write("测试一:"+encodeURIComponent("你好,世界!")+ "<br />")
document.write("测试二:"+encodeURIComponent("Hello world!")+ "<br />")
document.write("测试三:"+encodeURIComponent(",/?:@&=+$#"))
</script>
输出结果:
测试一:%E4%BD%A0%E5%A5%BD%EF%BC%8C%E4%B8%96%E7%95%8C%EF%BC%81
测试二:Hello%20world!
测试三:%2C%2F%3F%3A%40%26%3D%2B%24%23M:那查询之后返回的结果怎么显示?
Z:返回的为search.jsp页面,在页面标签之间进行回显。
<c:forEach items="${itemList}" var="item">
<li class="item-book" bookid="11078102">
<div class="p-img">
<a target="_blank" href="/item/${item.id }.html">
<img width="160" height="160" data-img="1" data-lazyload="${item.images[0]}" /> <!-- 修改成数组第一张图 -->
</a>
</div>
<div class="p-name">
<a target="_blank" href="/item/${item.id }.html">
${item.title}
</a>
</div>
<div class="p-price">
<i>淘淘价:</i>
<strong>¥<fmt:formatNumber groupingUsed="false" maxFractionDigits="2" minFractionDigits="2" value="${item.price / 100 }"/></strong>
</div>
<div class="service">由 淘淘 发货</div>
<div class="extra">
<span class="star"><span class="star-white"><span class="star-yellow h5"> </span></span></span>
</div>
</li>
</c:forEach>