对Disruptor 并发架构的一些思考
一、Disruptor的背景
Disruptor是一个高性能的异步处理框架,或者可以认为是最快的消息框架(轻量的JMS),也可以认为是一个观察者模式实现,或者事件-监听模式的实现,直接称disruptor模式。Disruptor最初由大神Martin Fowler 用作为LAMX系统的核心(一种新型的零售金融交易平台),其作为基于事件源驱动机制的业务逻辑处理器,完全运行在内存中,非常适用于大规模低延迟的高并发业务场景。
二、Disruptor的设计思想
Disruptor是通过一系列精巧的设计实现了在高并发情形下的高性能,其tps达到20,000,000/s。
主要有以下三方面:
1.整个架构实现无锁(仅在多个生产者写入 Ring Buffer 的场景中才出现多线程竞争修改同一个变量值的情况)
2.关键位置采用缓存行填充技术,消除内存伪共享
3.利用内存屏障保证顺序执行
其围绕RingBuffer实现了生产者-消费者模型:

三、基于Disruptor的业务模型
Disruptor除了性能非常优秀外,其架构的另一大特点就是将高并发问题通过单线程予以解决,使得我们在面对复杂问题时,多了一个解决问题有力工具。那在哪些场景中可以使用到它?我想大致可分为以下两种方式。
1.链式执行模型
最经典的是可以看LMAX的业务架构图:
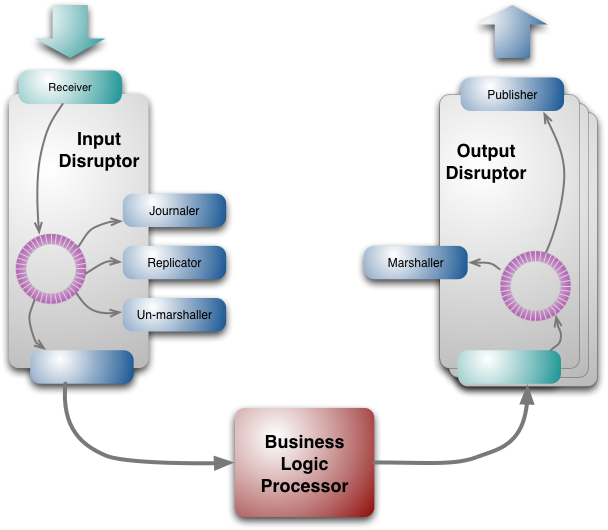
上图是整个业务流程的一段,由Receiver接收请求(这里的Receiver你可以理解为一个网络服务器),BLP处理请求,然后Publisher把处理结果交给下游,下游仍可继续使用该模式,就可将整个业务串行起来。通常对于很多较复杂的场景,在业务拆解时,系统的高性能和复杂度是难以兼顾的,而Disruptor的方式带来了一种高效的架构实现,能在保证高并发高性能的前提下,将复杂流程的业务进行链式拆解。
Disruptor支持如下多种生产-消费者模式:





通过这些模式组合,将大大有利于我们复杂业务的拆解。
2.带返回值执行模型
很多时候业务都需要在高并发的场景中进行计算后再将结果值返回,要实现这一目的就需消费者将结果缓存起来并让生产者获取到,实际可看做一个简单的内存数据库。这需要达到如下两个要求:
- 足够快速的保存和获取结果
- 足够空间缓存至少一个消费周期以上的结果(Disruptor内部实际有批处理机制,需保证一批的结果都能缓存到)
最简单的方式就是使用另一个RingBuffer进行实现,如下图

3.聚合请求模型
在一些需要聚合请求进行批处理以减少IO的场景,Disruptor也可利用其内部机制实现。
package com.lmax.disruptor;
public interface EventHandler<T> {
public void onEvent(T event, long sequence, boolean endOfBatch) throws Exception
}以上是消费者接口方法,其中利用endOfBatch标记并缓存event集,可实现一批集中处理效果,这实际是通过加大延迟来达到加大吞吐量和较少IO的目的。
四、总结
对于Disruptor带给我们的不仅仅是其优秀的内部实现机制,还开拓了我们对解决问题的思路。
作者:侯嘉逊