正则表达式是什么?能做什么?
1,把一个文件中所有的手机号码都找出来 从大段的文字中找到符合规则的内容
open打开文件
读文件 str
从一长串的字符串中找到所有的11位数字
是一个字符一个字符的读
2.输入手机号 判断某个字符串是否完全符合规则
验证这个手机号是否合法
给这个手机号发送一个验证码
用户收到验证码 填写验证码
完成注册
正则表达式
从大段的文字中找到符合规则的内容
爬虫 从网页的字符串中获取到你想要的数据
日志分析 提取所有的时间段的内容
判断某个字符串是否完全符合规则
表单验证:手机号 qq号 邮箱 银行卡 身分证号 密码
正则表达式 只和字符串打交道
正则表达式的规则
规则 字符串 从字符串中找到符合规则的内容
字符组 : [ ] 写在中括号中的内容,都出现在下面的某一个字符的位置上都是符合规则的
[0-9] 匹配数字
[a-z] 匹配小写字母
[A-Z] 匹配大写字母
[8-9] 匹配8-9
[a-zA-Z] 匹配大小写字母
[a-zA-Z0-9] 匹配大小写字母和数字
[a-zA-Z0-9_] 匹配数字字母下划线
元字符
\w 匹配数字字母下划线 word关键字 相当于[a-zA-Z0-9_]
\d 匹配所有的数字 digit [0-9]
\s 匹配所有的空白符 回车/换行符 制表符 空格 space [\n\t]
匹配换行符 回车 \n
匹配制表符 tab \t
匹配空格
\W \D 和 \w \d \s 取反
[\s\S] [\d\D] [\w\W]是三组全集 意思是匹配所有的字符
\b 表示单词的边界
和转义字母相关的元字符
\w \d \s(\n\t) \b \W \D \S
^ $
^ 匹配一个字符串的开始
$ 匹配一个字符串的结束
. 一个点表示匹配除换行符之外的所有的字符
[] 只要出现在中括号中的内容都可以被匹配
[^] 只要不出现在中括号的内容都可以被匹配
有一些有特殊意义的元字符进入字符组中会恢复它本来的意义: . | [] ()
a|b 或 符合a规则或者b规则的都可以被匹配
如果a规则是b规则的一部分,且a规则要苛刻/长,就把a规则写在前边
将更复杂的\更长的规则写在最前边
() 分组 表示给几个字符加上量词约束的需求的时候,就给这些量词分在一个组
量词
{n}表示 这个量词之前的字符\出现n次
{n,} 表示这个量词之前的字符至少出现n次
{n,m} 表示这个量词之前的字符出现n-m次
? 表示匹配量词之前的字符出现 0次 或者 一次 表示可有可无
+ 表示匹配量词之前的字符出现 1次 或者 多次
* 表示匹配量词之前的字符出现 0次 或者 多次
匹配整数 \d+
匹配小数 \d+\.\d+
匹配整数和小数 \d+(\.\d+)?
匹配负数和负小数 -?\d+(\.\d+)?
匹配省份证号码: [1-9]\d{14}(\d{2}[\dX])?
正则表达式的匹配特点:贪婪匹配
它会在允许的范围内去最长的结果
非贪婪模式/惰性匹配 : 在量词后边加上?
.*?X 匹配任意非换行符任意长度 直到遇到了X(停止条件)就停止
print(r'\\n')
print(r'\n')
关于字符串挪到python中的转义问题:只需要在工具中测试完毕,确认可以匹配上后,挪到 python中在字符串的外边加上r,r' '即可
re 模块
使用re模块之前必须引入re模块
import re
查找
findall: 匹配所有 每一项都是列表中的每一个元素


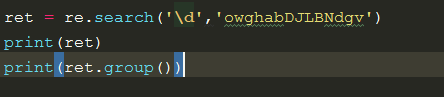
search:只匹配从左到右的第一个,得到的不是直接结果,而是一个变量,通过这个变量的group方法来获取结果


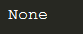
如果没有匹配到会返回None,如果继续使用group会报错
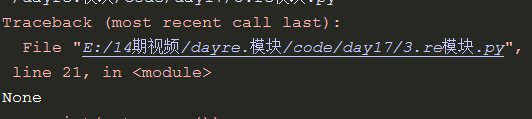
match 从头开始匹配,相当于search中的正则表达式加上一个^

在math的方法的正则表达式后边加上$,结果就是None

字符串处理的扩展: 替换 切割
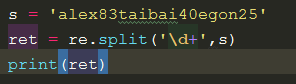
split

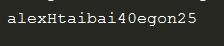
sub 替换 谁 旧的 新的 替换多少次


加替换次数的

subn 返回一个元组,第二个元素是替换次数


re模块的进阶 :
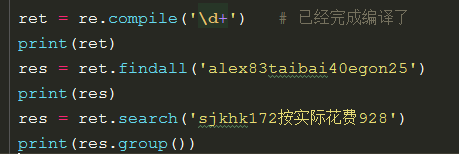
compile 节省使用正则表达式解决问题的时间
编译正则表达式 编译成字节码
在多次使用过程中 不会多次进行编译
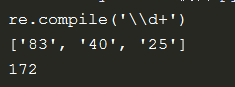
finditer 节省使用正则表达式解决问题的空间/内存

