1、上溢和下溢
计算机无法通过有限多的位来表示无限多的实数,当我们在计算机中表示一个实数时,几乎总会存在一些误差,在许多情况下,这被称为舍入误差(指运算得到的近似值和精确值之间的差异)。舍入误差会导致一些问题,特别是进行多次运算的时候。即使是理论上可行的算法,如果在设计时没有考虑最小化摄入误差的累积,在实践时也可能导致算法失效。
1.1、下溢
当接近与0的数被四舍五入为0时发生下溢,这可能造成算法失效,把该接近于0的数当做分母就会发生。举个例子,在机器学习中经常会遇到概率预算,而概率都是介于0和1之间的数,假如一个事件发生的概率为0.1,则10个0.1相乘就非常接近于0了。
1.2、上溢
当非常大的数被认为是\(+\infty\)或者\(-\infty\)时发生上溢,这同样会造成算法失效。
1.3、一个例子:softmax函数
必须对上溢或者下溢进行数值稳定的一个例子是softmax函数。softmax 函数经常用于预测与 Multinoulli 分布相关联的概率,其定义为:

从理论上来讲,该函数值应该为
1/n。但当
x中的值
\(x_i\)都为很小的负数时,
\(exp(x_i)\)的值就会接近0,从而发生下溢,这意味着softmax函数的分母会变成0,出现除0的错误;当
x中的值
\(x_i\)都为很大的正数时,
\(exp(x_i)\)也会变得非常大,可能会超出计算机所能表示的最大数,从而发生上溢,导致最后的结果未定义。
该函数的上溢和下溢问题可以通过softmax(z),其中 \(z=x-max(x)\)同时解决,z等于 x中的每个值减去 x中的最大值,所以z中的最大值为0,上溢不会发生,z中有一个值为0,所以分母至少为1,下溢也不会发生。
2、病态条件
条件数用来衡量函数相对于输入的微小变化而变化的快慢程度。高条件数的问题被称为病态的。输入被轻微扰动而迅速改变的函数对于科学计算来说可能是有问题的,因为输入中的舍入误差可能导致输出的巨大变化。
考虑函数\(f(x)=A^{-1}x\),当\(A∈\mathbb(R)^m×n\)具有特征分解时,其条件数定义为:
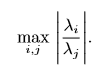
含义是最大和最小特征值的模之比。当该数很大时,矩阵求逆对输入误差特别敏感,如果输入数据有误差,矩阵会放大误差。
3、基于梯度的优化算法
3.1、最优化问题
大多数深度学习算法都涉及到某种形式的优化。优化是指改变x以最小化或最大化函数f(x)的任务。我们通常最小化f(x)指代大多数最优化问题,最大化可以通过最小化-f(x)得到。
我们把要最小化或最大化的函数称为目标函数(objective function)或准则(criterion)。当我们对其进行最小化时,我们也把它称为代价函数(cost function)、 损失函数(loss function)或误差函数(error function)。
我们通常使用一个星号上标*来表示最小化或最大化函数的x值,如\(x^*=arg\;min\;f(x)\),arg的意思是获取参数,所以该式的意义是获取f(x)取最小值时的x值。
3.2、微积分相关内容
3.2.1、导数与偏导数
函数\(y=f(x)\)的导数记为f'(x)或者dy/dx。导数f'(x)代表f(x)在x处的斜率。在二元函数z=f(x,y)中,把y固定(也就是把y看成常数),这时对x求导,称为z对x的偏导数,记为\(∂z/∂x\)或者\(∂f/∂x\)或者\(▽_xf(x)\)。
3.2.2、梯度
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y)的梯度为\([∂f/∂x, ∂f/∂y]^T\),简写为\(grad f(x,y)\)或者\(▽f(x,y)\)。在点(\(x_0,y_0)\))处的梯度就是\(▽f(x_0,y_0)\)。梯度从几何意义上讲,就是函数增加最快的方向。
3.3、梯度下降
导数对于最小化一个函数很有用,因为它告诉我们如何更改 x 来略微地改善 y。例如,我们知道对于足够小的 ϵ 来说,f(x−ϵsign(f′(x))) 是比 f(x) 小的(sign函数定义)。因此我们可以将 x 往导数的反方向移动一小步来减小 f(x)。这种技术被称为梯度下降 (gradient descent),下图给出了梯度下降的一个例子:


当 f′(x) = 0,导数无法提供往哪个方向移动的信息。f′(x) = 0 的点称为 临界点(critical point)或 驻点(stationary point)。一个 局部极小点(local minimum) 意味着这个点的 f(x) 小于所有邻近点,因此不可能通过移动无穷小的步长来减小 f(x)。一个 局部极大点(local maximum)意味着这个点的 f(x) 大于所有邻近点,因此不可能通过移动无穷小的步长来增大 f(x)。有些临界点既不是最小点也不是最大点,这些点被称为 鞍点(saddle point)。下面是各种临界点的例子:

使 f(x) 取得 绝对的最小值(相对所有其他值)的点是 全局最小点(global minimum)。函数可能只有一个全局最小点或存在多个全局最小点,还可能存在不是全局最优的局部极小点。在深度学习的背景下,我们要优化的函数可能含有许多不是最优的局部极小点,或者还有很多处于非常平坦的区域内的鞍点。尤其是当输入是多维的时候,所有这些都将使优化变得困难。因此,我们通常寻找使 f 非常小的点,但这在任何形式意义下并不一定是最小。下面是一个例子:

我们经常最小化具有多维输入的函数: \(f : \mathbb(R)^n →\mathbb(R)\)。为了使 ‘‘最小化’’ 的概念有意义,输出必须是 一维的 (也就是标量)。
针对具有多维输入的函数,我们需要用到 偏导数(partial derivative)的概念。 偏导数上面已经讲过,另一个概念是 梯度(gradient),对于f(x)来讲,如果所有的变量使用向量 x来表示的话,梯度就是包含所有偏导数的向量,记为 \(▽_xf(x)\),梯度的第i个元素时f关于 \(x_i\)的偏导数。在多维情况下, 临界点是梯度中所有元素都为零的点。
在 u(单位向量)方向的 方向导数(directional derivative)是函数 f 在 u 方向的斜率。换句话说,方向导数是函数 f(x+ αu) 关于 α 的导数(在 α = 0 时取得)。 使用链式法则,我们可以看到当 α = 0 时, \(\frac{∂f}{∂α}f(x+αu)=u^T▽_xf(x)\)。
为了最小化 f,我们希望找到使 f 下降得最快的方向。计算方向导数:

其中 θ 是 u 与梯度的夹角。将 \(∥u∥_2 = 1\) 代入,并忽略与 u 无关的项,就能简化得到 \(min cosθ\)。这在 u 与梯度方向相反时取得最小。换句话说,梯度向量指向上坡, 负梯度向量指向下坡。我们 在负梯度方向上移动可以减小 f,这被称为 最速下降法 (method of steepest descent) 或 梯度下降(gradient descent)。
最速下降建议新的点为:

其中 ϵ 为 学习率(learning rate),是一个确定步长大小的正标量。我们可以通过几种不同的方式选择 ϵ。普遍的方式是选择一个小常数。有时我们通过计算,选择使方向导数消失的步长。还有一种方法是根据几个 ϵ 计算 \(f(x−ϵ∇_xf(x))\),并选择其中能产生最小目标函数值的 ϵ,这种策略被称为 线搜索。
3.4、Jacobian矩阵(雅克比矩阵)
有时我们需要计算输入和输出都为向量的函数的所有偏导数。包含所有这样的偏导数的矩阵被称为 Jacobian矩阵。。具体来说,如果我们有一个函数: \(f : \mathbb{R}^m →\mathbb{R}^n\),f的雅克比矩阵 \(J∈\mathbb{R}^{n×m}\) 定义为: \[J_{i,j}=\frac{∂}{∂x_j}f(x)_i\]
也就是说,雅可比矩阵是函数的一阶偏导数以一定方式排列成的矩阵。举个例子,有\(\mathbb{R}^4\)的f函数:

则其雅克比矩阵为:

3.5、Hessian矩阵(海森矩阵)
当函数具有多维输入时(有很多变量),函数有很多二阶偏导数,我们可以将这些二阶偏导数合并成一个矩阵,称之为Hessian矩阵(海森矩阵)。Hessian 矩阵 \(H(f)(x)\) 定义为 :

展开就是:

海思矩阵等价于梯度的雅克比矩阵。
微分算子在任何二阶偏导连续的点处可交换,也就是它们的顺序可以互换:

这意味着 \(H_{i,j}=H_{j,i}\),因此 Hessian 矩阵在这些点上是对称的。在深度学习背景下, 我们遇到的大多数函数的 Hessian 几乎处处都是对称的。因为 Hessian 矩阵是实对称的,我们可以将其分解成一组实特征值和一组特征向量的正交基。在特定方向 d 上的 二阶导数可以写成 \(d^⊤Hd\)。当 d 是 H 的一个特征向量时,这个方向的 二阶导数就是对应的特征值。
3.5.1、最优步长
我们可以通过(方向)二阶导数预测一个梯度下降的步骤表现的有多好。我们在当前点\(x^{(0)}\)处作\(f(x)\)的近似二阶泰勒级数展开:

其中 \(g\)是梯度, \(H\)是 \(x^{(0)}\)点处的海思矩阵。如果我们使用学习率ε,那么新的点为 \(x^{(0)}-εg\),代入上面的公式可得:

当上式的最后一项太大时,梯度下降实际上是可能向上移动的。当 \(g^⊤Hg\)(二阶导数) 为零或负时,近似的泰勒级数表明增加 ϵ 将永远使 f 下降。在实践中,泰勒级数不会在 ϵ 大的时候也保持准确,因此在这种情况下我们必须采取更启发式的选择。当 \(g^⊤Hg\) 为正时,通过计算可得,使近似泰勒级数下降最多的最优步长为:

最坏的情况下, \(g\) 与 \(H\) 最大特征值 \(λ_{max}\) 对应的特征向量对齐,则最优步长是 \(1/λ_{max}\)。
3.5.2、二阶导数测试
我们可以根据二阶导数的正负情况来判断一个临界点是局部极大值点、局部极小值点或者鞍点,这就是所谓的二阶导数测试。当\(f'(x)=0\)时,说明x是一个临界点,若二阶导数\(f''(x)>0\),则说明\(f'(x)\)在x的右边是递增的,因为\(f'(x)=0\),所以x右边的导数均为正,所以\(f(x)\)在x右边单调递增,x左边的导数为负,所以\(f(x)\)在x左边递减,则x为局部极小值点;同理当二阶导数\(f''(x)<0\)时,x为\(f(x)\)的局部极大值点;当二阶导数\(f''(x)=0\)时,x可以是一个鞍点或平坦区域的一部分。
上面讨论的函数只有一个未知数,我们通过函数二阶导数的正负即可判断临界点的情况。当函数有多个参数时,我们需要检查该函数所有的二阶导数,也就是海思矩阵(Hessian矩阵)。一元函数二阶导数的正负对应海思矩阵特征值的正负。所以有:在临界点处(梯度\(▽_xf(x)\)=0),若海思矩阵的特征值全为正(正定的),则该临界点是局部极小值点;若海思矩阵的特征值全为负(负定的),则该临界点是局部极大值点;如果海思矩阵的特征值中至少有一个正的并且至少有一个负的,那么 x 是 f 某个横截面的局部极大点,却是另一个横截面的局部极小点,见下图:

最后,多维二阶导数测试可能像单变量版本那样是不确定的。当所有非零特征值是同号的且至少有一个特征值是 0 时,这个检测就是不确定的。这是因为单变量的二阶导数测试在零特征值对应的横截面上是不确定的。
3.6、牛顿法
多维情况下,单个点处每个方向上的二阶导数是不同的。Hessian 的条件数(在上文中,矩阵条件数定义为最大和最小特征值之比)衡量这些二阶导数的变化范围。当 Hessian 的条件数很差时,梯度下降法也会表现得很差。这是因为一个方向上的导数增加得很快,而在另一个方向上增加得很慢。梯度下降不知道导数的这种变化,所以它不知道应该优先探索导数长期为负的方向。病态条件也导致很难选择合适的步长。步长必须足够小,以免冲过最小而向具有较强正曲率的方向上升。这通常意味着步长太小,以致于在其他较小曲率的方向上进展不明显。我们可以使用牛顿法来解决这个问题。
先来看一下使用牛顿法求解一元函数的零点。首先我们选择一个接近\(f(x)\)零点的值\(x_0\),计算\(f(x_0)\)和\(f'(x_0)\),然后求出过点\((x_0, f(x_0))\)且斜率为\(f'(x_0)\)的直线与x轴的交点坐标,也就是求如下方程的解:

我们将新求得的点的x坐标命名为 $ x_1$,通常 \(x_1\)会比 \(x_{0}\)更接近方程 \(f(x)=0\)的解,因此我们现在可以利用 \(x_1\)开始下一轮迭代。迭代公式为:

不停的迭代,最后求得的x会越来越接近f(x)=0的解,如下图(图来自 维基百科)

推广到多维变量,牛顿法基于一个二阶泰勒展开来近似 \(x^{(0)}\) 附近的 \(f(x)\):

令 \(f'(x)=0\),我们可以得到这个函数的临界点:

当 f 是一个正定二次函数时,牛顿法只要应用一次上式就能直接跳到函数的最小点。如果 f 不是一个真正二次但能在局部近似为正定二次,牛顿法则需要多次迭代应用上式。迭代地更新近似函数和跳到近似函数的最小点可以比梯度下降更快地到达临界点。这在接近局部极小点时是一个特别有用的性质,但是在鞍点附近是有害的。当附近的临界点是最小点(Hessian 的所有特征值都是正的)时牛顿法才适用,而梯度下降不会被吸引到鞍点(除非梯度指向鞍点)。
仅使用梯度信息的优化算法被称为 一阶优化算法 (first-order optimization algorithms),如梯度下降。使用 Hessian 矩阵的优化算法被称为 二阶最优化算法 (second-order optimization algorithms),如牛顿法。
4、约束优化
有时候,在 \(x\) 的所有可能值下最大化或最小化一个函数 \(f(x)\) 不是我们所希望的。相反,我们可能希望在 \(x\) 的某些集合 \(\mathbb{s}\) 中找 \(f(x)\) 的最大值或最小值。这被称为约束优化(constrained optimization)。在约束优化术语中,集合 S 内的点 x 被称可行点(feasible point)。