一. 项目背景
之前写过HTTP服务器,写HTTP服务器的初衷是为了理解在浏览器输入网址之后发生的事情,深刻理解网络知识。在写完HTTP服务器后,看了很多文章,就想着怎样把HTTP做出一个有趣的东西,在网上查过资料后,和同学商量后,根据自己的技能水平,决定做出一个天气推送服务器。
二. 项目功能及原理
功能
爱心天气推送服务器主要的功能是:客户通过浏览器输入网址访问服务器,服务器返回一个登录页面,用户通过用户名(电话)和邮箱注册或登录成功后,进入自己的主页面,在主页面中点击我的关系后,填写自己的好友信息或父母信息(姓名,电话,邮箱,所在城市),然后服务器根据所存储的信息,将天气推送给用户好友等。
原理
开发环境及技术:Linux,C/C++,vim编辑器,socket编程,shell脚本,epoll模型,CGI模型
项目描述:本项目实现了用户通过浏览器注册用户名和密码,登录自己的主页并添加自己好友的信息,然后服务器对添加的好友发送实时天气预报。主要分为四大模块:
1. HTTP服务器:该模块利用epoll模型处理客户端发送的请求,完成服务器页面响应,执行CGI程序并将结果返回给浏览器。
2. 数据库:该模块设置用户表,好友表和天气表完成信息存储。根据表中的信息完成用户登录和天气推送。
3. 获取天气:该模块利用Python爬虫爬取天气网获取全国实时天气,并将天气信息存储在数据库中。
4. 推送天气:该模块完成天气推送,利用shell脚本控制天气发送并设置实时发送,将天气发送到用户注册的邮箱中。
项目特点:
1. 完成对客户端GET和POST方法的请求处理,利用环境变量、管道进行父子进程间信息交换,完成CGI模式。
2. 利用epoll多路转接技术,完成对客户端请求连接的管理,提高服务器的性能。
3. 利用C/C++数据库应用程序接口,完成CGI程序和数据库操作,将客户端信息注册到数据库中。
三. 四大模块介绍
1. HTTP服务器
HTTP服务器的原理前面介绍过,可以参考HTTP基础知识
HTTP服务器
2. 数据库
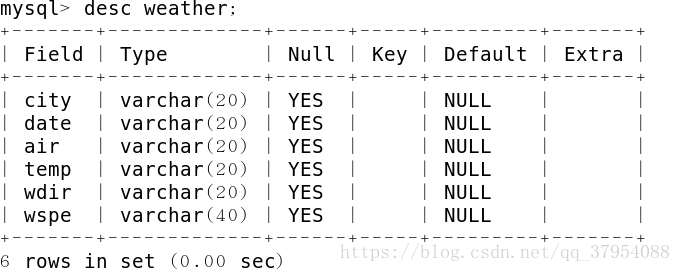
存储表结构
用户信息表(login table)
在用户信息表中存储的是用户的登录信息,其中将tel(电话) 作为主键,可以唯一确定用户和注册登录信息(主键是唯一的,不能为NULL值)。

好友信息表 (msg table)
好友信息表保存的是用户的好友信息,可以根据好友信息来推送天气,其中最重要的是city字段和value字段,根据city字段来确定应该爬取的是哪个城市的天气,根据value字段可以将天气发送至邮箱或者电话。

天气信息表 (weather table)
天气信息表中存储的是各城市的天气信息,包括城市,天气,日期,湿度等情况。根据好友信息表中的城市来匹配天气表中的城市,发送正确的天气情况。
数据库应用程序接口(API)
(1)要使用数据库,必须先对数据库进行初始化
MYSQL* mysql_init(MYSQL* mysql);
返回一个MySQL的句柄。(2)链接数据库
初始化完毕之后,必须先链接数据库,在进行后续操作。(mysql网络部分是基于TCP/IP的)
MYSQL* mysql_real_connect(MYSQL* mysql,
const char* host,
const char* user,
const char* passwd,
const char* db,
size_t port,
const char* unix_socket,
unsigned long clientflag);注:第一个参数 MYSQL是 C api中一个非常重要的变量(mysql_init的返回值),里面内存非常丰富,有port,dbname,charset等连接基本参数。它也包含了一个叫 st_mysql_methods的结构体变量,该变量里面保存着很多函数指针,这些函数指针将会在数据库连接成功以后的各种数据操作中被调用。
mysql_real_connect函数中各参数,基本都是顾名思意。其中port为数据库端口号为3306,unix_socket设置为NULL表示默认。
(3)下发命令
int mysql_query(MYSQL* mysql, const char* sentence);
第二个参数表示要执行的语句,如:select* from table;(4)获取结果集
如果是update,delete等操作,可以直接判断mysql_query的返回值,看是否执行成功即可;但是对于查询select ,我们需要将结果展示出来,就需要获取结果集。
MYSQL_RES* mysql_store_result(MYSQL* mysql);注:会调用MYSQL变量中的st_mysql_methods中的 read_rows 函数指针来获取查询的结果。同时该函数会返回MYSQL_RES 这样一个变量,该变量主要用于保存查询的结果。同时该函数malloc了一片内存空间来存储查询过来的数据,所以我们一定要记的 free(result),不然是肯定会造成内存泄漏的。 执行完mysql_store_result以后,其实数据都已经在MYSQL_RES 变量中了
(5)读取MYSQL_RES 中的数据
获取结果行数
my_ulonglong mysql_num_rows( MYSQL_RES* res);获取结结果列数
my_ulonglong mysql_num_fields(MYSQL_RES* res);获取结果列名
MYSQL_FIELD* mysql_fetch_fields(MYSQL_RES* res);int fields = mysql_num_fields(res);
MYSQL_FIELD *field = mysql_fetch_fields(res);
int i = 0;
for(; i < fields; i++){
cout<<field[i].name<<" ";
}
cout<<endl;获取结果内容
MYSQL_ROW mysql_fetch_row(MYSQL_RES* res);
它会返回一个MYSQL_ROW变量,MYSQL_ROW其实就是char **.就当成一个二维数组来使用。i = 0;
MYSQL_ROW line;
for(; i < nums; i++){
line = mysql_fetch_row(res);
int j = 0;
for(; j < fields; j++){
cout<<line[j]<<" ";
}
cout<<endl;
}(6)关闭链接
void mysql_close(MYSQL* sql);3. 获取天气信息
在HTTP服务器完成后,实现天气推送最重要的就是获取天气了,那么我们如何获取天气呢?可以用Python爬虫爬取15tianqi.com天气网获得。在Python中,又使用了scrapy框架进行天气爬取。
scrapy框架介绍
scrapy是一个用python编写的,轻量级的框架,它使用Twisted异步网络库处理网络通讯。
scrapy有8大组件,各组件如下:
(1) scrapy engine
负责scrapy的引擎,用来处理整个系统的数据流。
(2) Schedule
调度器,Schedule接受从引擎发送的请求,并压入等待队列中,在引擎再次请求的时候返回给引擎。
(3) Downloader
拿到请求以后,下载网页,并将下载的网页交给Spider处理。
(4) Spiders
Spiders是蜘蛛,主要负责解析网页内容,我们可以在spiders中定制网页解析要求。
(5) Item Pipeline
项目管道,主要用来存储数据并对数据加工处理。
(6) Downloader Middlewares
下载器中间件,在引擎和和下载器之间的钩子框架,主要处理引擎和下载器之间的请求和响应。
(7) Spiders Middlewares
蜘蛛中间件,位于蜘蛛和下载器之间的钩子框架,主要处理蜘蛛的输入请求和输出响应。
(8) Schedule Middleware
调度器中间件,位于调度器和下载器之间的钩子框架,负责引擎调度的请求和响应。
2. 创建项目和项目结构
创建一个工程
scrapy startproject 项目名
如:scrapy startproject weather项目结构

说明:
(1)在我们利用scrapy创建一个工程后,会自动生成这些目录和文件,目录和文件呈现如上图。
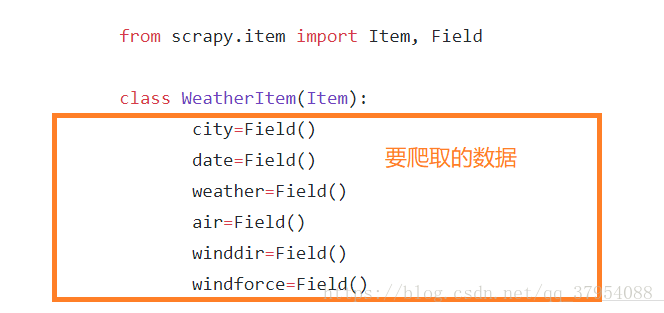
(2)我们在item.py中定制爬取要爬取的数据,包括城市,日期,winddir, air(空气质量) ,windforce(风速) 。
(3)我们在pipelines中地址保存数据的方式,保存在数据库中。python和数据库的连接接口为MySQLdb.Connection。

(4)在settings.py中设置爬虫选项,如果想让pipeline起效,则在settings.py里面设置ITEM_PIPLINES选项。 由于有些网页会禁止爬虫爬取,所以我们可以修改USER_AGENT这个选项将爬虫伪装成浏览器进行爬取。

(5)spider是蜘蛛目录,我们可以在这个目录中设置解析网页的要求。

4. 推送天气
准备工作已经完成(好友信息保存,天气信息保存),接下来就是发送天气了,那么天气应该怎么发送呢?我们可以利用shell脚本实时控制天气的发送,并将天气发送到好友邮箱中。
(1)从数据库的msg表中获取好友信息
利用C/C++数据库接口,获取好友的姓名(name),城市(city),邮箱(mail)。

(2)获取数据库中的天气信息
利用msg表中的好友所在的城市匹配weather表的城市。
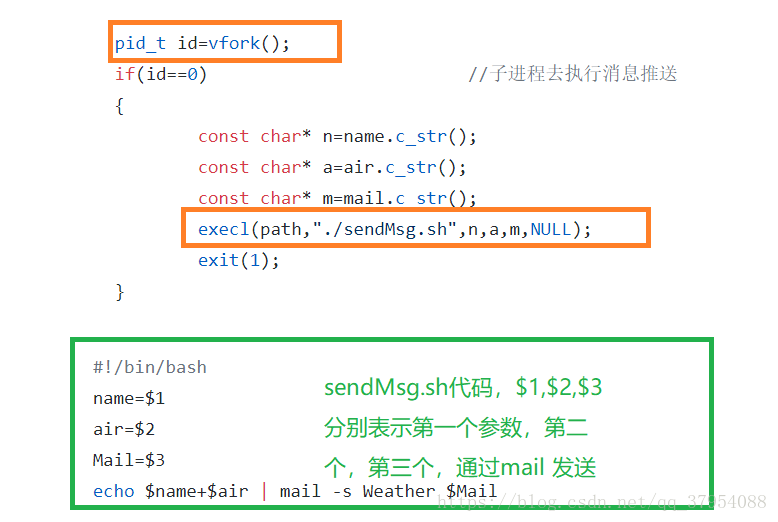
std::string data="select * from weather where city=";(3)发送天气消息
在主函数中创建子进程,利用子进程执行sendMsg.sh程序,发送消息。
整个项目的结构就是这样。