一 .概述
在前面一节之中,我们看到了springboot是怎么实现自定义数据源的配置的,本节我们就进行Druid数据源的配置.

这是上面一节的配置信息,我们发现我们需要制定type属性,另外我们就可以利用DataSourceProperties对象进行数据源的配置了.
二 . 数据源的配置
首先我们需要先拉入一个Druid的数据源的jar文件.
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.10</version> </dependency>
本次我们使用最新的就好了,因为我自己也不记忆版本号,导致我们本地仓库现在爆炸了.呵呵.
然后,我们就需要对Druid进行配置,首先看一下application.yml文件进行配置.
在上面,我们看到了,我们需要制定一个type类型.
我们实现如下的配置:
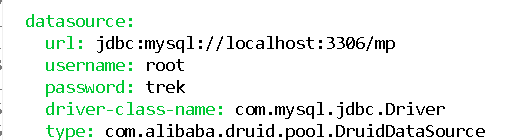
现在我们再次运行测试,发现我们的数据源已经配置好了.
二 .个性化属性的配置
我们知道Druid之中有很的自定义的属性,上面的这种配置只是一个简单的配置方式.
我们再次看看自动配置类:
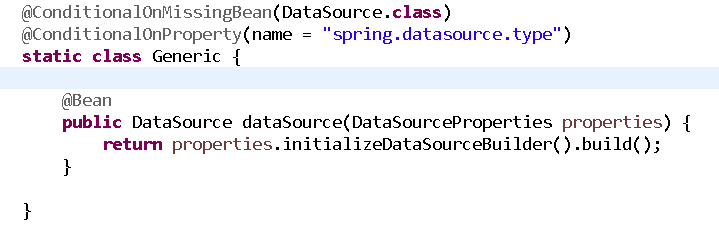
我们发现,如果容器之中没有数据源的情况下,springboot才会进行数据源的配置,那么我们直接自己配置一个数据源就好了.
现在我们对我们的Durid的配置文件进行修改.
datasource: url: jdbc:mysql://localhost:3306/mp username: root password: trek driver-class-name: com.mysql.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource # 下面为连接池的补充设置,应用到上面所有数据源中 # 初始化大小,最小,最大 initialSize: 5 minIdle: 5 maxActive: 20 # 配置获取连接等待超时的时间 maxWait: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 timeBetweenEvictionRunsMillis: 60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false # 打开PSCache,并且指定每个连接上PSCache的大小 poolPreparedStatements: true maxPoolPreparedStatementPerConnectionSize: 20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 filters: stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # 合并多个DruidDataSource的监控数据 useGlobalDataSourceStat: true
现在我们做一个配置类:
@Configuration public class DataSourceConfig { @Bean @ConfigurationProperties("spring.datasource") public DataSource druid() { return new DruidDataSource(); }
三. Druid的监控的配置
我们使用Druid的核心就是Druid可以帮助我们查看一个数据源的监控信息,下面我们来配置一下这些核心的过滤器.
@Bean public ServletRegistrationBean druidServlet() { ServletRegistrationBean servletBean = new ServletRegistrationBean( new com.alibaba.druid.support.http.StatViewServlet(), "/druid/*"); // 配置相关的属性 Map<String, String> initParameters = new HashMap<>(); // 放置各种的属性 initParameters.put("loginUsername", "admin"); initParameters.put("loginPassword", "123456"); servletBean.setInitParameters(initParameters); return servletBean; } /** * 配置Druid的filter信息 * @return */ @Bean public FilterRegistrationBean druidFilter() { FilterRegistrationBean filterBean = new FilterRegistrationBean(); filterBean.setFilter(new WebStatFilter()); //配置拦截所有的请求 filterBean.setUrlPatterns(Arrays.asList("/*")); Map<String, String> initParameters = new HashMap<>(); //排除所有不需要拦截的请求 initParameters.put("exclusions", "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*"); filterBean.setInitParameters(initParameters ); return filterBean; }
上面的配置之中,核心就是配置两个过滤器.一个就是配置监控视图的过滤器,一个就是配置Druid的拦截器的过滤器.
当我们访问druid的时候,我们就能看到Drudi的监控页面的内容了.