一、上采样理论
FCN全卷积网络:
将网络的全连接层 变成 卷积层之后,整个网络变成了只有卷积层和池化层的网络,于是网络就称之为全卷积网络。
全卷积网络一般是用来对图像进行语义分割的,于是就需要对图像上的各个像素进行分类,这就需要一个上采样将最后得到的输出上采样到原图的大小。上采样的过程也类似于一个卷积的过程,只不过在卷积之前将输入特征插值到一个更大的特征图然后进行卷积。下面举例子说明这个过程。
- 上采样利用的是
conv2d_transpose()函数,这个函数输入的有几个关键的参数,(value , filter , output_shape , strides , padding..)
value 是输入的特征图:
将这个特征图进行上采样,格式是[n,h,w,c],n是你这一个batch的图片数量,
h和w是特征图的宽和高,c是特征图的数量;
filter是卷积核的大小:
四维的[h,w,in_channel,out_channel],h和w是卷积核的大小,
in_channel是输入特征图的数量,out_channel是输出特征图的数量。
output_shape: 是要上采样得到的特征图的大小,格式与value一致。
strides是步长: 四维格式,分别对应value四个维度的步长。 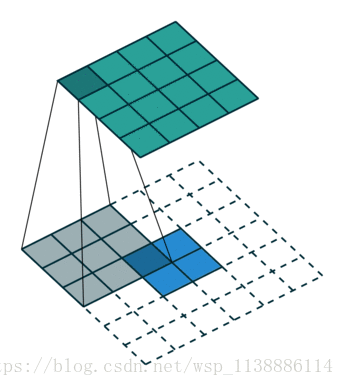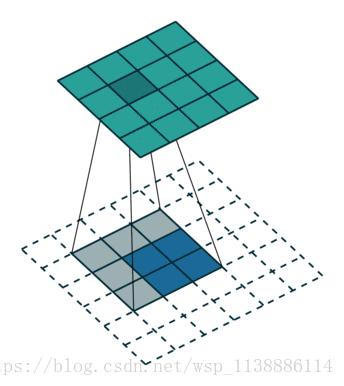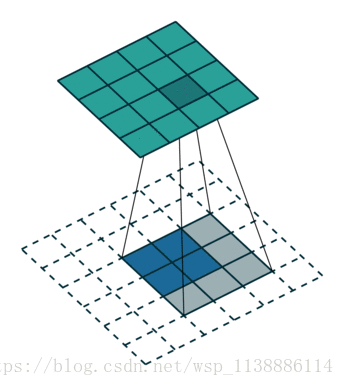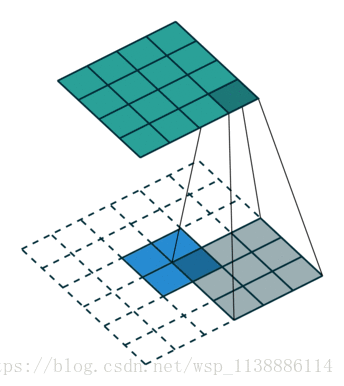
1.1 bilinear
双线性插值是目前在语义分割中用的比较多的一种方式:
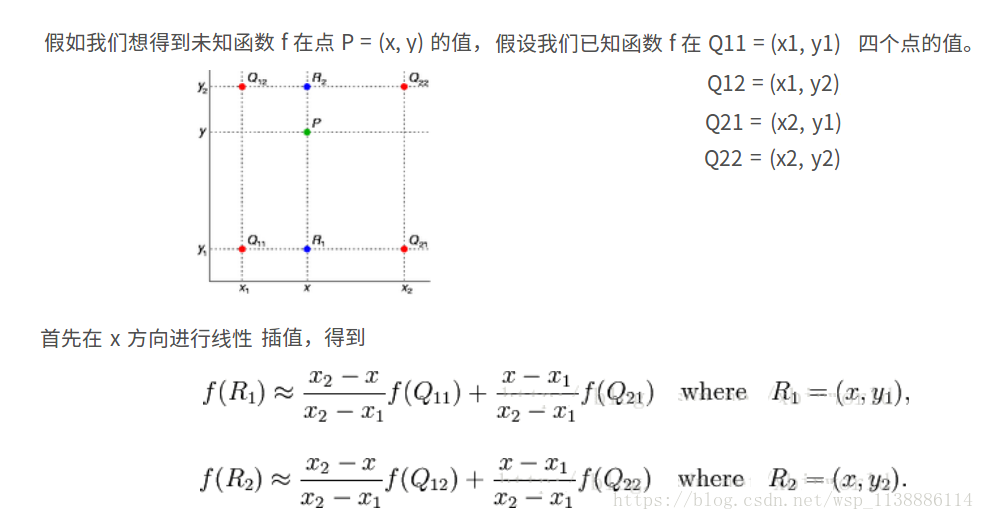
具体的实现方式,可以直接参考fcn.berkerlyvision.org中的surgery.py如下:
def upsample_filt(size):
"""
Make a 2D bilinear kernel suitable for upsampling of the given (h, w) size.
"""
factor = (size + 1) // 2
if size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:size, :size]
return (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)1.2 Deconvolution(反卷积)
Deconvolution是目前争议比较多的方法,由于实现上采用转置卷积核的方法,所以有人说应该叫(transposed convolution),但是思想上是为了还原原有特征图,类似消除原有卷积的某种效果,所以叫反卷积(deconvolution)。
卷积计算通常的两种实现方式是:在caffe中使用im2col的方法,在其他的地方使用toeplitz matrix(托普利兹矩阵)进行实现。
为了更容易地实现deconvolution,直接使deconv的前向传播模拟conv的反向传播,当然,这里只是为了保证尺寸大小互逆,并不能保证值的还原。
例子
- (1) 关于第一节中bilinear的在caffe中使用deconvolution进行实现,上节的bilinear论述过程中使用固定值计算的方法,本节从deconv可视化计算的角度进行理解,https://github.com/vdumoulin/conv_arithmetic
63个元素 [16x16中的(0,0)元素] 31个元素 [16x16中的(0,1)元素] 31个元素
其中,中括号中的元素可见
对以上过程进行卷积运算,注意这里stride 使用1, 最终输出大小为(63+32x15+64-64)/1 + 1 = 544
这里可以脑补一下计算过程,相当于第一节中的手算叠加 - (2) 对bilinear使用转置运算进行实现,先将64x64的卷积核转化为toeplitz matrix,然后转置,得到544x544,256的矩阵,然后将score_fr转化为1, 256的矩阵,两者矩阵乘法,得到544x544的最终结果,具体过程脑补吧
1.3 unpooling
也就是反池化,不需要学习,用的不是太多,参考论文Visualizing and Understanding Convolutional Networks,还有SegNet和DeconvNet
简单原理:在池化过程中,记录下max-pooling在对应kernel中的坐标,在反池化过程中,将一个元素根据kernel进行放大,根据之前的坐标将元素填写进去,其他位置补0
实现代码可以看SegNet的实现
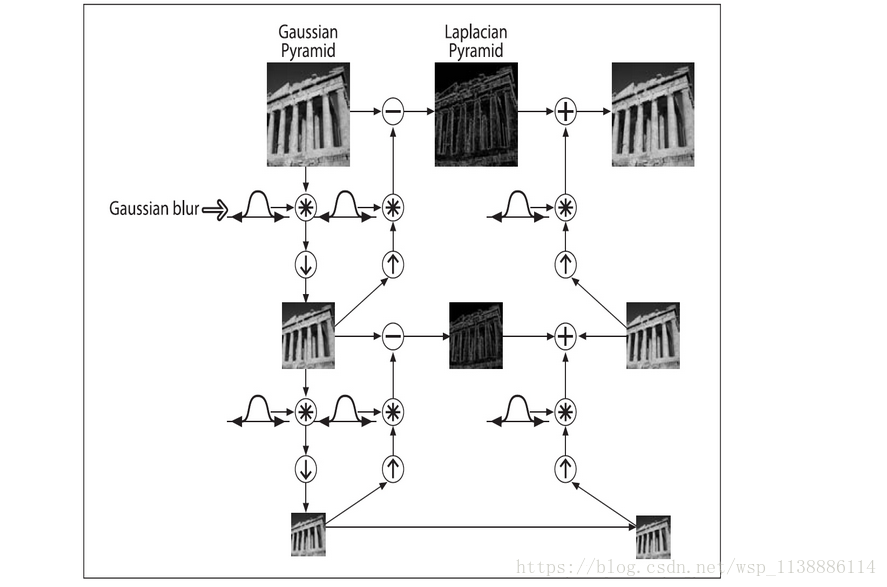
二、OpenCV金字塔:高斯金字塔、拉普拉斯金字塔与图片缩放
使用OpenCV函数 pyrUp 和 pyrDown 对图像进行向上和向下采样,以及了解了专门用于缩放图像尺寸的resize函数的用法。
OpenCV (图像处理模块结构)
| -------imgproc
| |-------Image Filtering
| | |---------pyrUp、pyrDown
| |
| |-------Geometric Image Transformations
| | |--------resize
高斯金字塔(Gaussianpyramid): 用来向下采样,主要的图像金字塔
拉普拉斯金字塔(Laplacianpyramid): 用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原。
- 高斯金字塔:
-
第
层生成第
层(第
层表示为
),我们先要用高斯核对
进行卷积,然后删除所有偶数行和偶数列。
当然的是,新得到图像面积会变为源图像的四分之一。按上述过程对输入图像 执行操作就可产生出整个金字塔。
显然:结果图像只有原图的四分之一;向下取样(卷积)会逐渐丢失图像的信息。 - 拉普拉斯金字塔
-
拉普拉斯金字塔第i层的数学定义:
表示第 i 层的图像。而 操作是将源图像中位置为 的像素映射到目标图像的 位置,即在进行向上取样。 表示卷积, 为5x5的高斯内核。
- 对图像向上采样:pyrUp函数
-
如果想放大图像,则需要通过向上取样操作得到,具体做法如下:
(1)将图像在每个方向扩大为原来的俩倍,新增的行和列以0填充
(2)使用先前同样的内核(乘以4)与放大后的图像卷积,获得新增像素的近似值 - 对图像向下采样:pyrDown函数
-
PryUp和PryDown不是互逆的,即PryUp不是降采样的逆操作。
这种情况下,图像首先在每个维度上扩大为原来的两倍,新增的行(偶数行)以0填充。
然后给指定的滤波器进行卷积(实际上是一个在每个维度都扩大为原来两倍的过滤器)去估计“丢失”像素的近似值。