8.10 shell特殊符号cut命令
8.11 sort_wc_uniq命令
8.12 tee_tr_split命令
8.13 shell特殊符号下
8.14扩展
8.15 课堂笔记
8.10 shell特殊符号cut命令
特殊符号
\ #脱义字符,将特殊字符或通配符还原成一般字符
[root@localhost ~]#
a=1
[root@localhost ~]#
b=2
[root@localhost ~]#
echo $a
1
[root@localhost ~]#
echo $b
2
[root@localhost ~]#
c=$a$b
[root@localhost ~]#
echo $a$b
12
[root@localhost ~]#
echo '$a$b'
$a$b
[root@localhost ~]#
echo \$a\$b
$a$b
| #将管道符前面内容的输出结果让后面命令执行
[root@localhost ~]#
cat 1.txt |wc -l
1
几个跟管道符有关的命令
注意###cat、head、sort、uniq、grep不会对文件内容进行更改####
cut分割,-d 分隔符 -f 指定段号(例: 1; 1,2; 1-3) -c 指定第几个字符(如果使用-c时,不能同时使用-d,-f)
例:
cat /etc/passwd |head -2 |cut -d ":" -f 1-3
# |head -2 表示截取etc/passwd开头前两段内容
[root@localhost ~]#
cat /etc/passwd |head -2 |cut -d ":" -f 1-3
root:x:0
bin:x:1
[root@localhost ~]#
cat /etc/passwd |head -2 |cut -d ":" -f 1,2
root:x
bin:x
[root@localhost ~]#
cat /etc/passwd |head -2 |cut -d ":" -f 1-3 -c 1
cut: 只能指定列表中的一种类型
Try 'cut --help' for more information.
[root@localhost ~]#
cat /etc/passwd |head -2 |cut -c 1
r
b
8.11 sort_wc_uniq命令
#sort默认按照ASCII排序
#sort之前要先source 文件,防止里面有一些命令对文件赵成影响(例如里面有rm命令,会删除)
1、sort排序,
-n 以数字排序(字母会认为是0,排在最前面)(默认从小到大)
[root@localhost ~]#
sort -n 3.txt
>
;
ahsflhg;a
1.txt
2.txt
1234
2345
2345
24324234
-r 反序 (从大到小)
[root@localhost ~]#
sort -n -r 3.txt
24324234
2345
2345
1234
2.txt
1.txt
ahsflhg;a
;
>
-t分隔符
-k(按照第几列进行排序)
[root@localhost ~]#
cat 2.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost ~]#
sort -t ":" -k 1 2.txt
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
2、wc -l 统计行数 -m 统计字符数 -w 统计词
[root@localhost ~]#
wc -l 2.txt
5 2.txt
[root@localhost ~]#
wc -m 2.txt
183 2.txt
3、uniq 去重, -c 统计行数
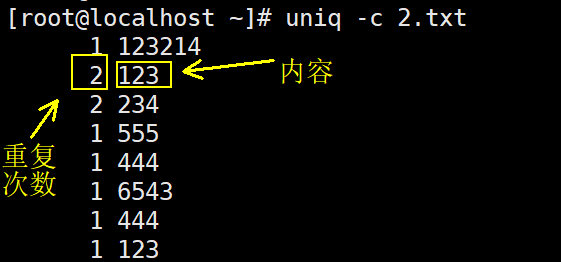
8.12 tee_tr_split命令
1、tee和>类似,重定向的同时还在屏幕显示
例:
sort 2.txt |uniq -c |tee 1.txt #排序2.txt的结果进行去重uniq,然后结果tee到1.txt,会显示到屏幕上
[root@localhost ~]#
sort 2.txt |uniq -c |tee 1.txt
3 123
1 123214
2 234
2 444
1 555
1 6543
2、tr 替换字符,tr 'a' 'b',大小写替换tr'[a-z]' '[A-Z]'
[root@localhost ~]# cat 2.txt |tr '2' 'a'
1a3a14
1a3
1a3
a34
a34
555
444
6543
444
1a3
3、split 切割,-b 大小(默认单位字节 ),-l 行数
#对大文件进行切割,均分为指定大小或者行数的小文件
例:
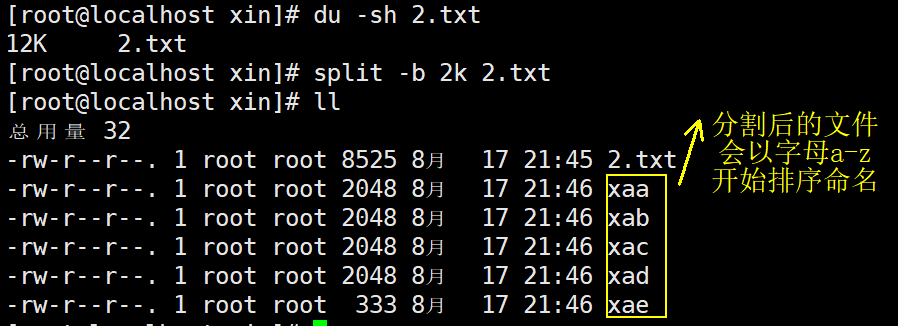
[root@localhost xin]#
split -l 500 2.txt
[root@localhost xin]#
ll
总用量 28
-rw-r--r--. 1 root root 8525 8月 17 21:45 2.txt
-rw-r--r--. 1 root root 2618 8月 17 21:50 xaa
-rw-r--r--. 1 root root 2055 8月 17 21:50 xab
-rw-r--r--. 1 root root 2056 8月 17 21:50 xac
-rw-r--r--. 1 root root 1796 8月 17 21:50 xad
切割后文件命名可以自定义,在文件后面加上自定义命名即可
split -l 500 2.txt abc
[root@localhost xin]#
split -l 500 2.txt abc
[root@localhost xin]#
ll
总用量 28
-rw-r--r--. 1 root root 8525 8月 17 21:45 2.txt
-rw-r--r--. 1 root root 2618 8月 17 21:52
abcaa
-rw-r--r--. 1 root root 2055 8月 17 21:52
abcab
-rw-r--r--. 1 root root 2056 8月 17 21:52
abcac
-rw-r--r--. 1 root root 1796 8月 17 21:52
abcad
8.13 shell特殊符号下
$变量前缀,!$组合,正则里面表示行尾
~用户家目录,正则表达式表示匹配符
;多条命令写到一行,用分号分割
[root@localhost ~]# ls 1.txt; wc -l 3.txt
1.txt
16 3.txt
&放到命令后面,会把命令丢到后台运行
[root@localhost ~]# sleep 100 &
[1] 1471
[root@localhost ~]# jobs
[1]+ 运行中 sleep 100 &
[ ]指定字符中的一个,[0-9],[a-zA-Z],[abc]
[root@localhost ~]# ls [1-9].txt
1.txt 3.txt
[root@localhost ~]# ls [a-z].txt
a.txt b.txt c.txt
|| 和&&,用于命令之间
ll是表示或者,第一条命令执行成功,第二条命令便不执行;若第一条命令执行失败,第二条命令便会执行
[root@localhost ~]#
ls 1.txt || ls 5.txt
1.txt
[root@localhost ~]#
ls 5.txt || wc -l 1.txt
ls: 无法访问5.txt: 没有那个文件或目录
6 1.txt
&&表示且,只有第一条命令执行成功才会执行第二条命令
[root@localhost ~]#
ls 1.txt && ls 5.txt
1.txt
ls: 无法访问5.txt: 没有那个文件或目录
[root@localhost ~]#
ls 5.txt && wc -l 1.txt
ls: 无法访问5.txt: 没有那个文件或目录
8.14扩展
1、关于PROMPT_COMMAND环境变量的含义
![]() http://www.linuxnote.org/prompt_command-environment-variables.html
http://www.linuxnote.org/prompt_command-environment-variables.html
2、source exec 区别
![]() http://alsww.blog.51cto.com/2001924/1113112
http://alsww.blog.51cto.com/2001924/1113112
3、Linux特殊符号大全
![]() http://ask.apelearn.com/question/7720
http://ask.apelearn.com/question/7720
4、sort并未按ASCII排序
![]() http://blog.csdn.net/zenghui08/article/details/7938975
http://blog.csdn.net/zenghui08/article/details/7938975
8.15课堂笔记
一、grep (#重点)
egrep是grep的升级版,即grep -E == egrep,
当你需要过滤时含有特殊符号,要用egrep才能成功过滤
-v #加-v表示取反
例:
grep "[a-zA-Z]" 1.txt #将1.txt内有字母的行都过滤出来
grep -v "[a-zA-Z]" 1.txt #将1.txt内除字母外其他行过滤出来
[root@localhost ~]#
cat 1.txt
a 3 12aaa3
s 1 123aq214
d 2 23q4
f 2 4a44
1 5a55
1 65
[root@localhost ~]#
grep "[a-zA-Z]" 1.txt
a 3 12aaa3
s 1 123aq214
d 2 23q4
f 2 4a44
1 5a55
[root@localhost ~]#
grep -v "[a-zA-Z]" 1.txt
1 65
egrep "^$ |^#" 1.txt #将1.txt的空行(^$)、注释行(^#)过滤出来
egrep -v "^$ |^#" 1.txt #将1.txt的除非空行、非注释行外其他行过滤出来
[root@localhost ~]#
egrep "^$|^#" 1.txt
####
##
###
##3
[root@localhost ~]#
egrep -v "^$|^#" 1.txt
3 123
1 123214
2 234
2 444
1 555
1 65
33 3#3
333###4###
二、shell变量
ps:" _ "下划线是特殊字符,如果要加入变量名,输出只会将下划线后面接着的变量显示出来;下划线前面的变量会显示不出来
例:for i in `seq 1 10`;do echo "lv_$i";done
#通过for循环echo显示lv级别,
[root@localhost ~]#
for i in `seq 1 10`;do echo "lv_$i";done
lv_1
lv_2
lv_3
lv_4
lv_5
lv_6
lv_7
lv_8
lv_9
lv_10
将lv定义为变量lvname的值,然后执行命令显示不出来
[root@localhost ~]#
lvname=lv;for i in `seq 1 10`;do echo "$lvname_$i";done
1
2
3
4
5
6
7
8
9
10
将"_"下划线换成"-"横杠,变量lvname就能显示出来
[root@localhost ~]#
lvname=lv;for i in `seq 1 10`;do echo "$lvname-$i";done
lv-1
lv-2
lv-3
lv-4
lv-5
lv-6
lv-7
lv-8
lv-9
lv-10
三、source 命令
source 环境变量配置文件
# 修改环境变量配置文件后,必须注销重新登录才能生效,使用source 命令可以不用重新登录

[root@localhost ~]#
vim admin
[root@localhost ~]#
source admin
[root@localhost ~]#
echo $name2
lisi
四、环境变量配置文件设置
PS1=[\u@\h \W]$ (
面试中可能会问到,平时不用掌握)
PS1的常用参数以及含义:
\d :代表日期,格式为weekday month date,例如:"Mon Aug 1"
\H :完整的主机名称
\h :仅取主机名中的第一个名字
\t :显示时间为24小时格式,如:HH:MM:SS
\T :显示时间为12小时格式
\A :显示时间为24小时格式:HH:MM
\u :当前用户的账号名称
\v :BASH的版本信息
\w :完整的工作目录名称
\W :利用basename取得工作目录名称,只显示最后一个目录名
\# :下达的第几个命令
\$ :提示字符,如果是root用户,提示符为 # ,普通用户则为 $
五、特殊字符
"\" 表示脱义字符,将特殊字符的语意去掉
[root@localhost ~]#
grep "[" 1.txt #"["中括号为特殊字符,双引号识别不了,所以报错
grep: 无效的常规表达式
[root@localhost ~]#
grep "\[" 1.txt #用\号脱义,就可以成功
[1234]
[124
#"*"号查找前面的字符出现0次或者0次以上,所以就算该行没有出现"[",也会显示出来
[root@localhost ~]#
grep "\[*" 1.txt
12412jkahksflg123
214asd
asf
234dsa
asd24345
[1234]
2344]
[124
#"+"号表示前面字符至少出现一次才会过滤出来,这里+是特殊字符,所以用到egrep
[root@localhost ~]#
egrep "\[+" 1.txt
[1234]
[124
六、与管道符相关的命令
1、cut分割 -d分隔符 -f 段号 -c 段中第几个字符
例:
cut -d ":" /etc/passwd -f 1,3 #文件要放在中间
2、sort -n(以数字排序(默认大到小)) -r(反序) -k(按照第几列的值排序)
例:
sort -t " " -k 2 1.txt #将1.txt的内容以空格为分隔符,按照第二列的值从小到大排序
3、wc -l (统计行数) -m(统计字符数) -w(统计单词) -c(统计字节数)
4、uniq -c(统计出现行数)
5、tr 替换字符 #只能针对字符串,不能单独使用
例:
echo "xiaogao" | tr "x" "X"
6、split 切割 -b 大小(默认单位字节) -l (行数)
#将文件以指定的大小或者以指定行数切割均分文件
例:
split -b
六、|| (或者) &&(且)
|| (或者 ) :如果第一条命令执行正确,第二条命令则不执行。如果第一条命令执行错误,则执行第二条命令。
&&(且) :如果第一条命令执行成功了才执行第二条命令,如果第一条命令错误,第二条命令则不执行。
ps:
1、| 与 || 的区别
|和||的区别同理,都可以作为逻辑或运算符;
|还可以作为按位或的运算符,运算规则与按位与同理;
||同样有类似短路的功能,即第一个条件若为true,则不计算后面的表达式。
2、&与&&的区别
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。
&&还具有短路的功能,即如果第一个表达式为false,则不再计算第二个表达式。
&还可以用作按位与的运算符,两个表达式的值按二进制位展开,对应的位(bit)按值进行“与”运算,结果保留在该位上
(1)短路功能测试:
public class AndTest {
public static void main(String[] args) {
String str=null;
if (str!=null&str.equals("")) {
System.out.println("true");
}
}
}
当为&,会报错 java.lang.NullPointerException,即空指针错误;
当为&&,则不会报错
(2)按位与:
运算规则:0&0=0; 0&1=0; 1&0=0; 1&1=1;
即:两位同时为“1”,结果才为“1”,否则为0
例如:3&5 即 0000 0011 & 0000 0101 = 0000 0001 ;因此,3&5的值得1。
public class AndTest {
public static void main(String[] args) {
int a=3&5;
System.out.println("a="+a);
}
}
结果a=1.