Phoenix(SQL On HBase)安装和使用报告
http://www.cnblogs.com/kekukekro/p/6339587.html#wiz_toc_29
二、安装Phoenix
2.1 兼容问题?
2.2 编译CDH版本的Phoenix
2.3 安装Phoenix到CDH环境中
三、Phoenix的使用
3.1 phoenix的4种调用方式
3.1.1 批处理方式
3.1.2 命令行方式
3.1.3 GUI方式
3.1.4 JDBC调用
3.2 Phoenix的数据操作操作
3.2.1 支持的数据类型
3.2.2 插入数据
3.2.3 删除数据
3.2.4 更新数据
3.2.5 查询数据
3.3 Phoenix的Schema操作
3.3.1 什么?没有DataBase?
3.3.2 创建表
3.3.2.1 SALT_BUCKETS(加盐?)
3.3.2.2 Pre-split(预分区)
3.3.2.3 使用多列族
3.3.2.4 使用压缩
3.3.3 删除表
3.3.4 创建视图
3.3.5 删除视图
3.3.6 创建二级索引
3.3.7 删除索引
3.3.8 如何与现有的HBase表关联
3.3.8.1 创建关联表
3.3.8.2 创建关联视图
3.3.8.3 总结
3.4 使用Spark操作Phoenix
3.4.1 添加phoenix-spark的仓库依赖
3.4.2 在Spark运行环境中添加Phoenix依赖
3.5.1 使用Data Source API加载Phoenix数据
3.5.2 使用Configuration类创建DataFrame
3.5.3 使用Zookeeper URL创建RDD
3.5.4 保存到Phoenix
3.5.3 使用Spark保存Phoenix数据的列有什么要求?
3.5.4 通过Phoenix取数据和直接通过代码取数据性能差别有多大
一、为什么使用Phoenix
Phoenix是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
Phoenix是构建在HBase之上的SQL引擎。你也许会存在“Phoenix是否会降低HBase的效率?”或者“Phoenix效率是否很低?”这样的疑虑,事实上并不会,Phoenix通过以下方式实现了比你自己手写的方式相同或者可能是更好的性能(更不用说可以少写了很多代码):
- 编译你的SQL查询为原生HBase的scan语句
- 检测scan语句最佳的开始和结束的key
- 精心编排你的scan语句让他们并行执行
- 让计算去接近数据通过
- 推送你的WHERE子句的谓词到服务端过滤器处理
- 执行聚合查询通过服务端钩子(称为协同处理器)
除此之外,Phoenix还做了一些有趣的增强功能来更多地优化性能:
- 实现了二级索引来提升非主键字段查询的性能
- 统计相关数据来提高并行化水平,并帮助选择最佳优化方案
- 跳过扫描过滤器来优化IN,LIKE,OR查询
- 优化主键的来均匀分布写压力
以下是Phoenix对(吊)比(打)Hive、Impala的测试:
Phoenix VS Hive
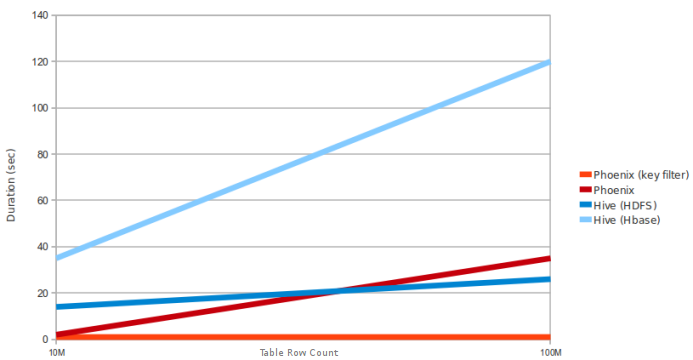
Query: select count(1) from table over 10M and 100M rows. Data is 5 narrow columns. Number of Region Servers: 4 (HBase heap: 10GB, Processor: 6 cores @ 3.3GHz Xeon)Phoenix vs Impala
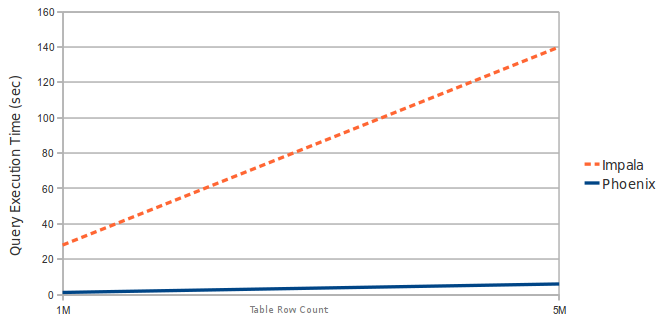
Query: select count(1) from table over 1M and 5M rows. Data is 3 narrow columns. Number of Region Server: 1 (Virtual Machine, HBase heap: 2GB, Processor: 2 cores @ 3.3GHz Xeon)
目前有哪些公司在使用Phoenix?

二、安装Phoenix
2.1 兼容问题?
首先,通过命令hbase version可以查看到 
我们的HBase版本是1.2.0的。
接下来我们到 http://archive.apache.org/dist/phoenix 下载对应版本的安装包。这里我们选择apache-phoenix-4.8.1-HBase-1.2-bin.tar.gz 这个版本。
我们将下载的Phoenix压缩包上传到Master节点(任意一个都行)中,然后解压 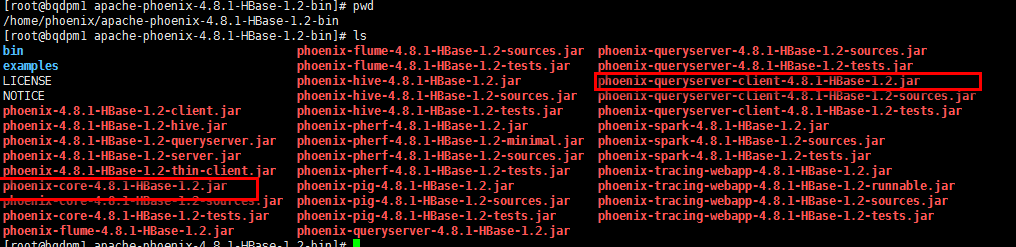
我们可以看到里面包含了很多组件的jar包,我们只需要将phoenix-core-4.8.1-HBase-1.2.jar和phoenix-4.8.1-HBase-1.2-client.jar拷贝到HBase的lib目录下,然后将HBase的配置文件hbase-site.xml文件拷贝到Phoenix解压的目录下的bin目录。然后重启HBase
输入bin/sqlline.py bqdpm1,bqdpm2,bqdps1:2181。结果报错 
很明显,这里提示包冲突了。我们回想一下,下载的phoenix的包原本是从apache的官方下载的,里面打包的是apache的hadoop和hbase,也就是说并不支持cdh。那应该怎么办呢?
2.2 编译CDH版本的Phoenix
由于Phoenix工程里面使用的依赖都是Apache原版的jar包,因此我们需要修改为CDH的依赖。可以参考编译phoenix用于CDH平台
修改了依赖过后还需要修改部分代码才行,这样就比较麻烦了。好在我们有万能的github,已经有大神帮我们做好了修改,可以直接拿下来用。链接:phoenix-for-cloudera。虽然工程上写着是CDH4.8,但是实际上4.7也能用。
将工程克隆下来或者直接批量下载下来,解压后可以看到如下目录 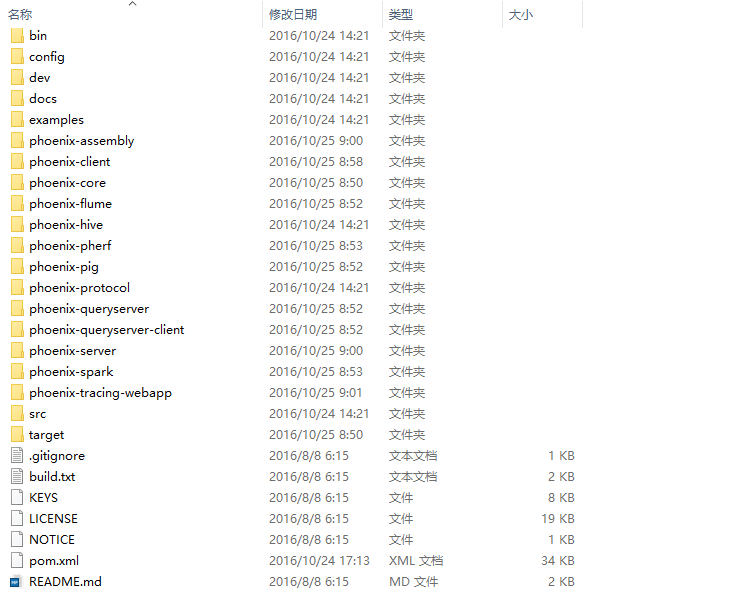
很明显,这是一个maven工程。在确定电脑安装了maven之后,使用命令mvn clean package -DskipTests -Dcdh.flume.version=1.4.0。这里的flume版本需要指定为我们需要的Flume版本,CDH4.7中使用的是1.4。接下来就是漫长的等待。。。 
最终,编译的jar包和工程的文件将会打包到phoenix-assembly/target中 
2.3 安装Phoenix到CDH环境中
将打包好的phoenix-4.8.0-cdh5.8.0.tar.gz文件上传到CDH环境中,然后解压可以看到如下文件: 
然后将phoenix-4.8.0-cdh5.8.0-server.jar文件拷贝到各个节点的HBase依赖路径下,即/opt/cloudera/parcels/CDH/lib/hbase/lib/
再将hbase的配置文件hbase-site.xml拷贝到bin目录下即可。
然后进入bin目录,执行./sqlline.py bqdpm1,bqdpm2,bqdps1:2181
看到如下信息说明成功 
如果出现下面问题 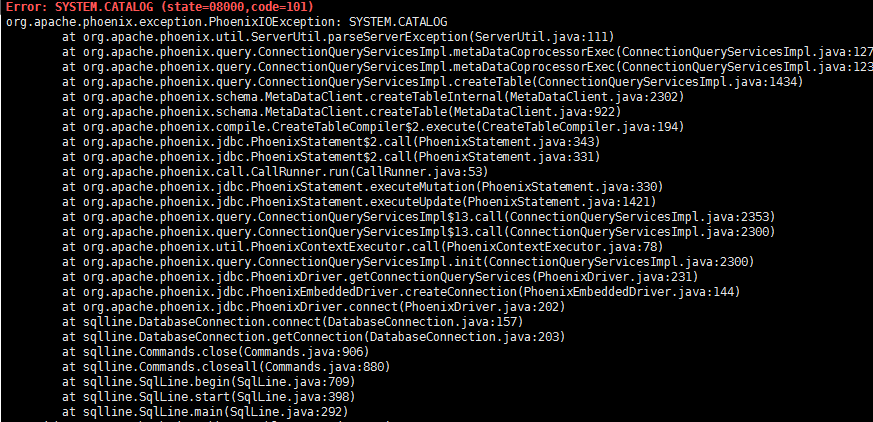
则需要检查hdfs的权限控制是否关闭了。然后执行hbase clean --cleanZk
最后重启HBase即可
三、Phoenix的使用
3.1 phoenix的4种调用方式
3.1.1 批处理方式
首先创建us_population.sql文件,里面的创建一个名为us_population的表
CREATE TABLE IF NOT EXISTS us_population (state CHAR(2) NOT NULL,city VARCHAR NOT NULL,population BIGINTCONSTRAINT my_pk PRIMARY KEY (state, city));
接下来新建一个数据文件us_population.csv
NY,New York,8143197CA,Los Angeles,3844829IL,Chicago,2842518TX,Houston,2016582PA,Philadelphia,1463281AZ,Phoenix,1461575TX,San Antonio,1256509CA,San Diego,1255540TX,Dallas,1213825CA,San Jose,912332
最后创建一个查询sql文件us_population_queries.sql
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"FROM us_populationGROUP BY stateORDER BY sum(population) DESC;
执行../bin/psql.py bqdpm1,bqdpm2,bqdps1:2181 us_population.sql us_population.csv us_population_queries.sql 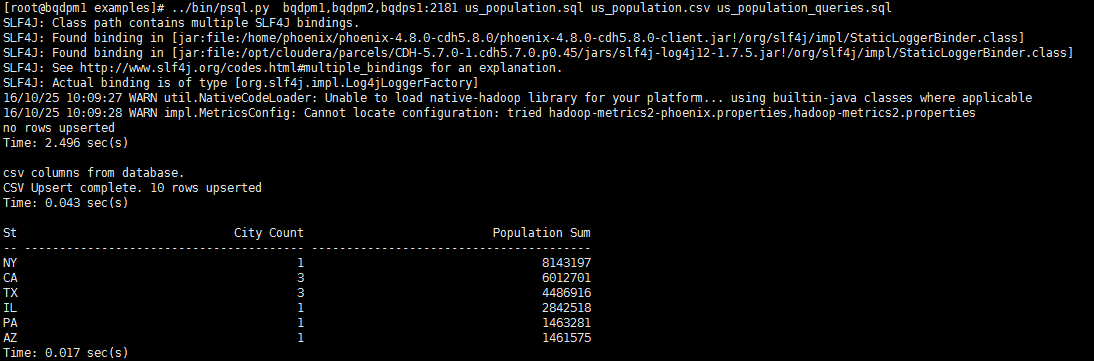
这里的命令中的us_population.sql和us_population.csv必须同名
其实,创建了表之后我们单独运行../bin/psql.py bqdpm1,bqdpm2,bqdps1:2181 us_population_queries.sql也是可以的
通过Phoenix建的表都会自动转成大写,如果需要使用小写的表,请使用
create table "tablename"
安装了Phoenix之后就会存在四张系统表
在Phoenix中创建的表同时会在HBase中创建一张表与之对应 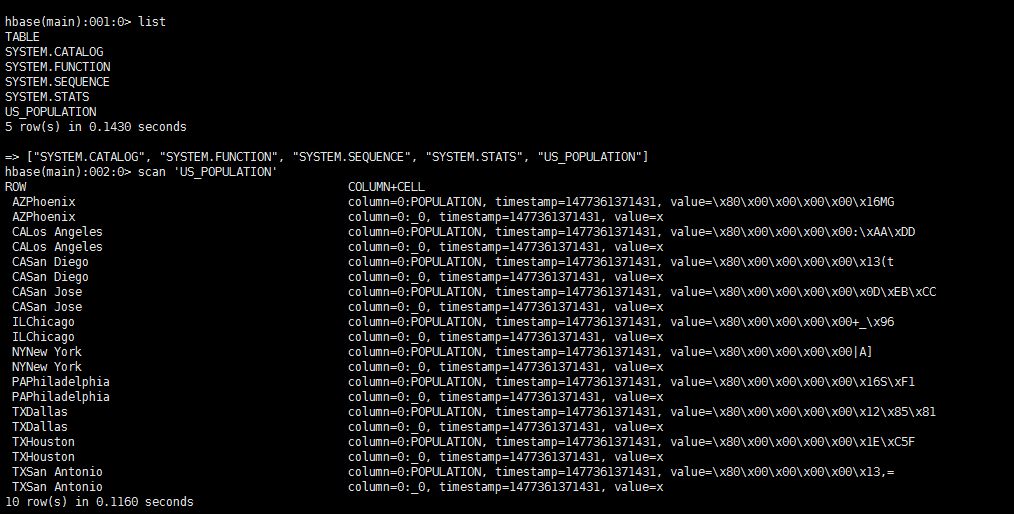
3.1.2 命令行方式
使用./sqlline.py bqdpm1,bqdpm2,bqdps1:2181登录到Phoenix的shell中,可以使用正常的SQL语句进行操作,
可以使用
!table查看表信息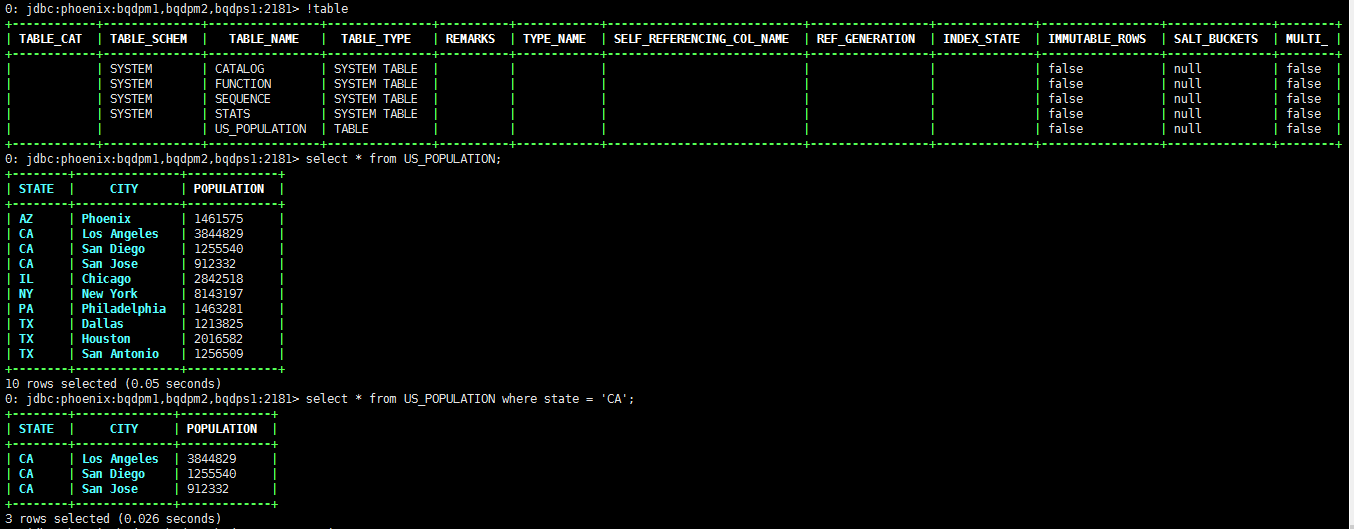
使用
!describe tablename可以查看表字段信息
使用
!history可以查看执行的历史SQL使用
!dbinfo可以查看Phoenix所有的属性配置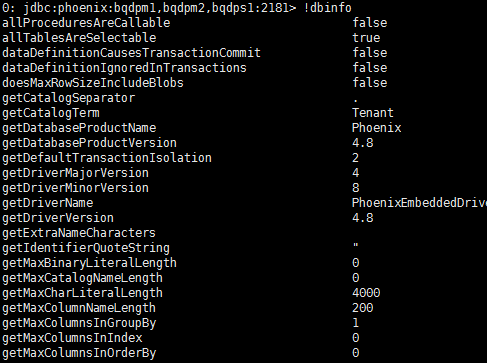
除了上面这些以外之外还有很多其他操作,可以用过help查看
0: jdbc:phoenix:bqdpm1,bqdpm2,bqdps1:2181> help!all Execute the specified SQL against all the current connections!autocommit Set autocommit mode on or off!batch Start or execute a batch of statements!brief Set verbose mode off!call Execute a callable statement!close Close the current connection to the database!closeall Close all current open connections!columns List all the columns for the specified table!commit Commit the current transaction (if autocommit is off)!connect Open a new connection to the database.!dbinfo Give metadata information about the database!describe Describe a table!dropall Drop all tables in the current database!exportedkeys List all the exported keys for the specified table!go Select the current connection!help Print a summary of command usage!history Display the command history!importedkeys List all the imported keys for the specified table!indexes List all the indexes for the specified table!isolation Set the transaction isolation for this connection!list List the current connections!manual Display the SQLLine manual!metadata Obtain metadata information!nativesql Show the native SQL for the specified statement!outputformat Set the output format for displaying results(table,vertical,csv,tsv,xmlattrs,xmlelements)!primarykeys List all the primary keys for the specified table!procedures List all the procedures!properties Connect to the database specified in the properties file(s)!quit Exits the program!reconnect Reconnect to the database!record Record all output to the specified file!rehash Fetch table and column names for command completion!rollback Roll back the current transaction (if autocommit is off)!run Run a script from the specified file!save Save the current variabes and aliases!scan Scan for installed JDBC drivers!script Start saving a script to a file!set Set a sqlline variable!sql Execute a SQL command!tables List all the tables in the database!typeinfo Display the type map for the current connection!verbose Set verbose mode on
3.1.3 GUI方式
首先需要保证电脑安装了SQuirrel.
然后点击Driver的增加按钮,填上名字和Phoenix的jdbc地址示例如jdbc:phoenix:zookeeper quorum server,然后指定外部驱动为本地的phoenix-4.8.0-cdh5.8.0-client.jar的org.apache.phoenix.jdbc.PhoenixDriver 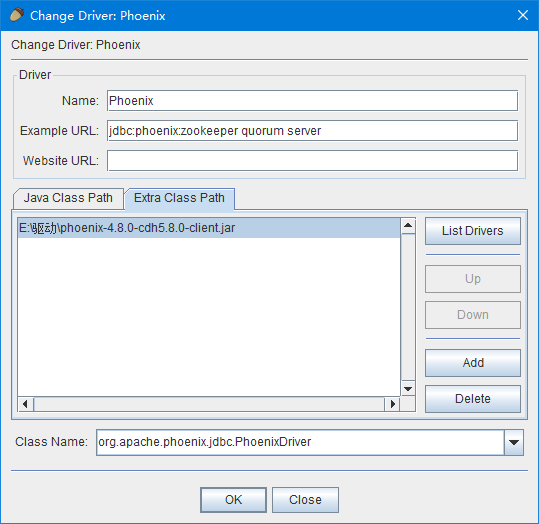
然后添加连接,选择驱动为刚才我们添加的Phoenix驱动,然后URL写上具体的zookeeper集群,比如jdbc: phoenix:bqdpm1,bqdpm2,bqdps1点击OK 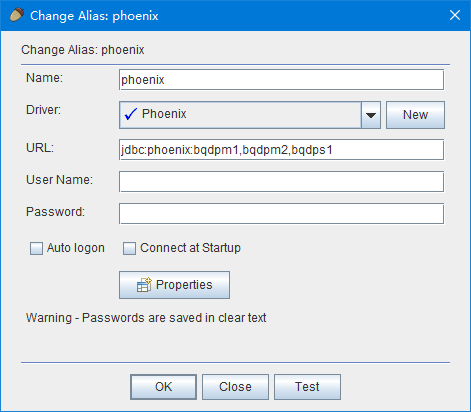
连接好了过后就可以执行SQL语句了 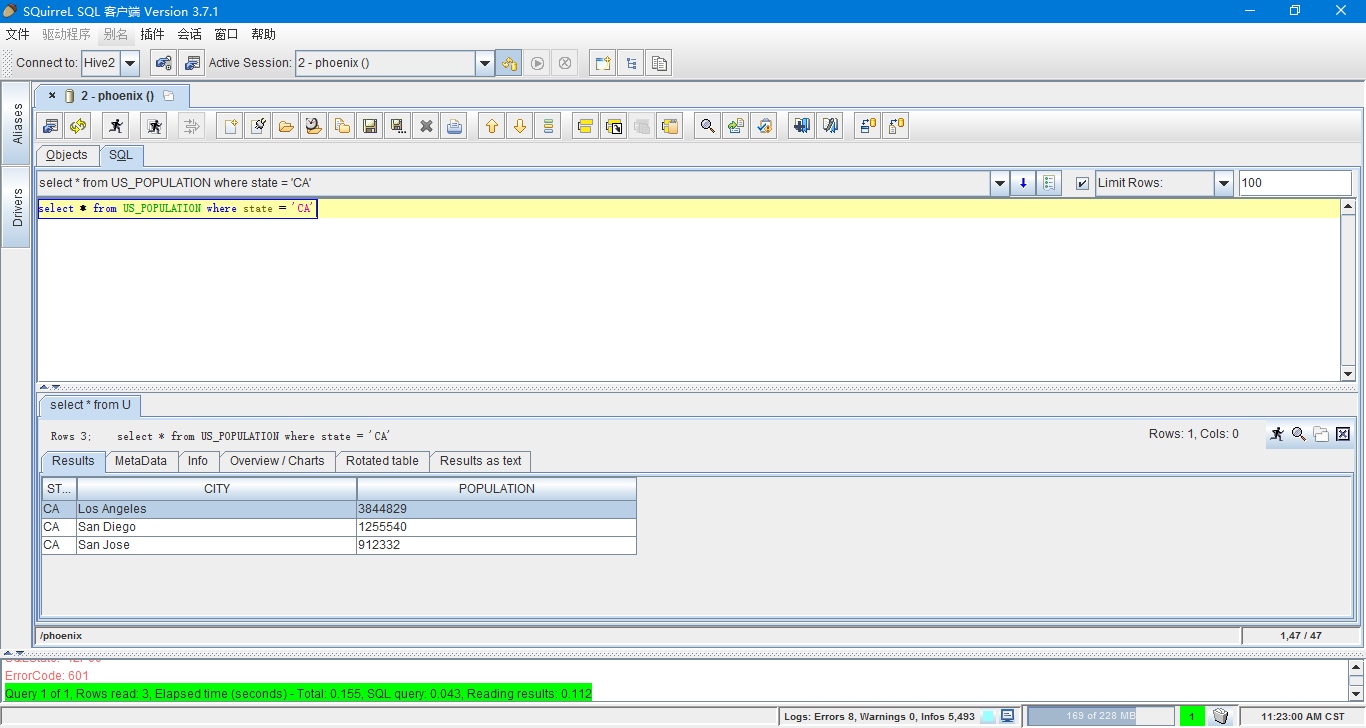
3.1.4 JDBC调用
这里我们就直接使用之前写好的一个工程来进行测试吧。
首先添加数据库链接的conf设置
phoenix {jdbcClass = org.apache.phoenix.jdbc.PhoenixDriverurl = "jdbc:phoenix:bqdpm1,bqdpm2,bqdps1"user = ""password = ""}
然后讲驱动jar文件引入工程,由于我们用的CDH版本的client,所以maven的中央仓库搜不到,因此我们只好手动添加。当然,后续会传到nexus私服 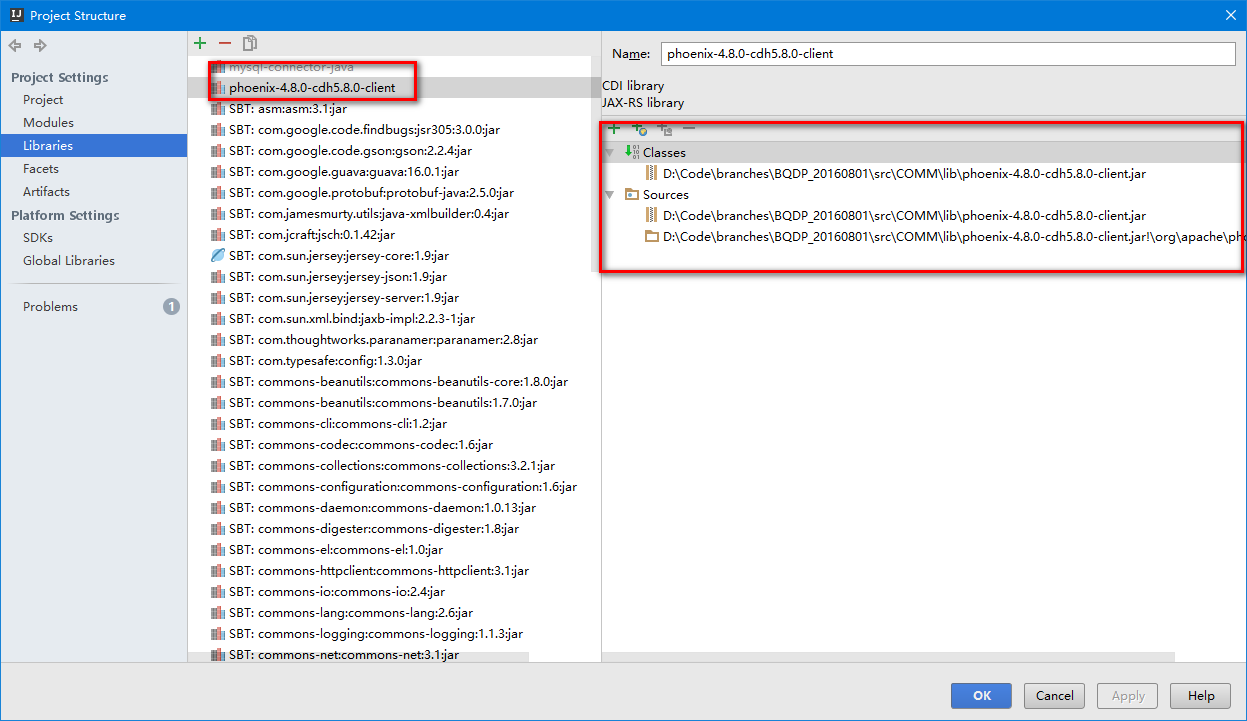
接下来写一个查询sql运行,达到结果 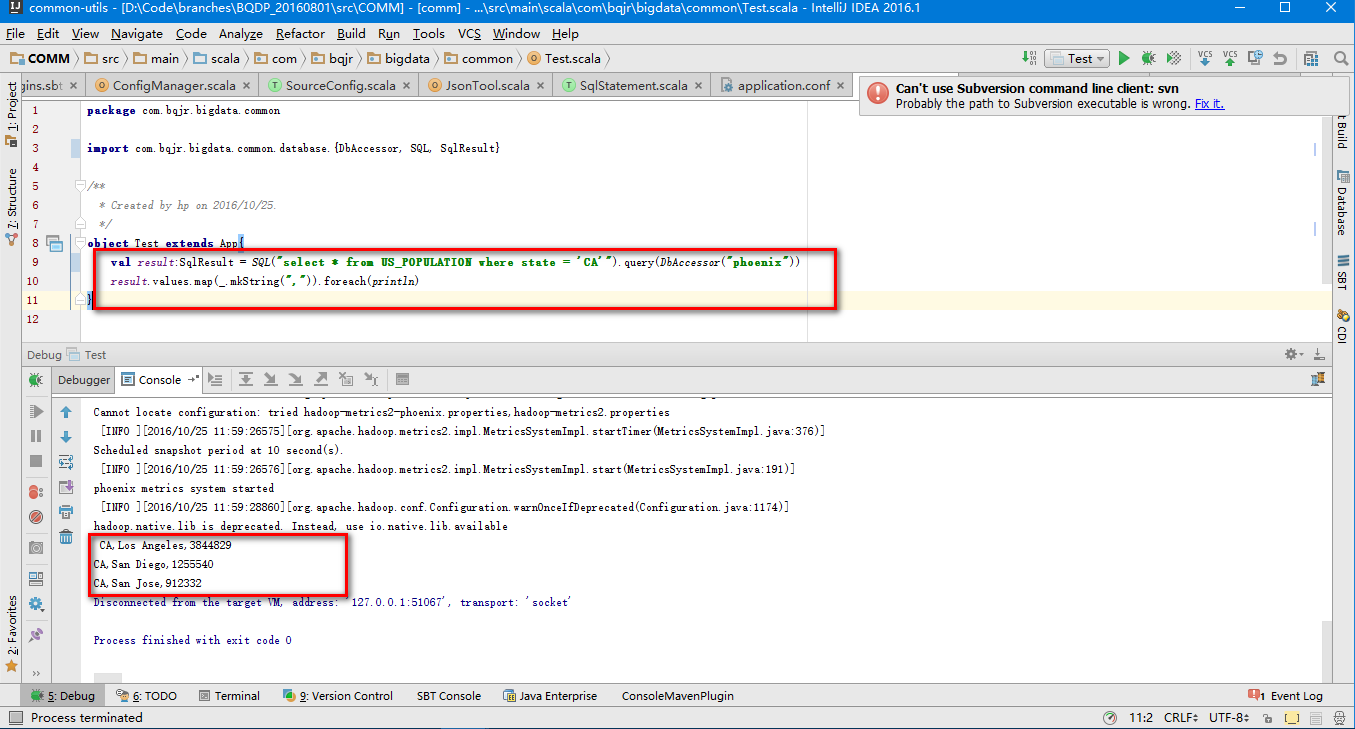
Phoenix不建议使用连接池进行操作,详见:https://phoenix.apache.org/faq.html#Is_there_a_way_to_bulk_load_in_Phoenix
3.2 Phoenix的数据操作操作
在页面 http://phoenix.apache.org/language/index.html 中给出了所有的操作说明。
3.2.1 支持的数据类型
| 数据类型 | Java Map | 占用大小 | 范围 (byte) |
|---|---|---|---|
| INTEGER | java.lang.Integer | 4 | -2147483648 to 2147483647 |
| UNSIGNED_INT | java.lang.Integer | 4 | 0 to 2147483647 |
| BIGINT | java.lang.Long | 8 | -9223372036854775807 to 9223372036854775807 |
| UNSIGNED_LONG | java.lang.Long | 8 | 0 to 9223372036854775807 |
| TINYINT | java.lang.Byte | 1 | -128 to 127 |
| UNSIGNED_TINYINT | java.lang.Byte | 1 | 0 to 127 |
| SMALLINT | java.lang.Short | 2 | -32768 to 32767 |
| UNSIGNED_SMALLINT | java.lang.Short | 2 | 0 to 32767 |
| FLOAT | java.lang.Float | 4 | -3.402823466 E + 38 to 3.402823466 E + 38 |
| UNSIGNED_FLOAT | java.lang.Float | 4 | 0 to 3.402823466 E + 38 |
| DOUBLE | java.lang.Double | 8 | -1.7976931348623158 E + 308 to 1.7976931348623158 E + 308 |
| UNSIGNED_DOUBLE | java.lang.Double | 8 | 0 to 1.7976931348623158 E + 308 |
| DECIMAL | java.math.BigDecimal | DECIMAL(p,s) | |
| BOOLEAN | java.lang.Boolean | 1 | TRUE and FALSE |
| TIME | java.sql.Time | 8 | yyyy-MM-dd hh:mm:ss |
| DATE | java.sql.Date | 8 | yyyy-MM-dd hh:mm:ss, |
| TIMESTAMP | java.sql.Timestamp | 12 | yyyy-MM-dd hh:mm:ss[.nnnnnnnnn] |
| UNSIGNED_TIME | java.sql.Time | 8 | yyyy-MM-dd hh:mm:ss |
| UNSIGNED_DATE | java.sql.Date | 8 | yyyy-MM-dd hh:mm:ss |
| UNSIGNED_TIMESTAMP | java.sql.Timestamp | 12 | |
| VARCHAR | java.lang.String | VARCHAR(n) | |
| CHAR | java.lang.String | CHAR (n) | |
| BINARY | byte[] | BINARY(n) | |
| VARBINARY | byte[] | VARBINARY | |
| ARRAY | java.sql.Array | VARCHAR ARRAY |
请移步http://phoenix.apache.org/language/datatypes.html 测试
但是实际使用中,我们如果使用INTEGER等数值类型,必须将4个字节补全,不能直接在HBase中建写入直接的数值,因此我建议如果要关联已有的HBase表,最好直接使用VARCHAR类型
3.2.2 插入数据
在Phoenix中是没有Insert语句的,取而代之的是Upsert语句。Upsert有两种用法,分别是:UPSERT INTO和UPSERT SELECT
- UPSERT INTO
类似于insert into的语句,旨在单条插入外部数据
UPSERT INTO US_POPULATION VALUES('AK','Juneau',30711);UPSERT INTO US_POPULATION (STATE,CITY,POPULATION) VALUES('AK','Anchorage',260283);
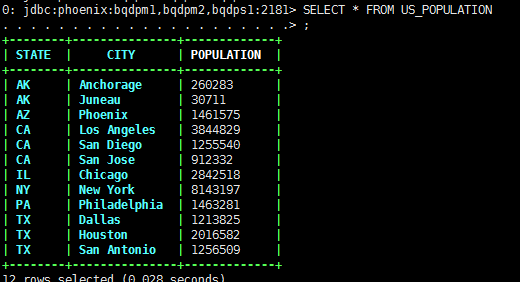
- UPSERT SELECT
类似于Hive中的insert select语句,旨在批量插入其他表的数据。
源表: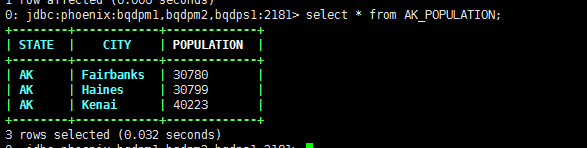
目标表: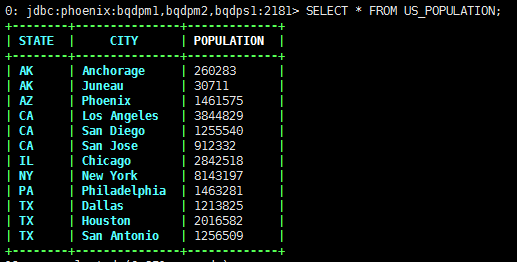
执行插入语句
UPSERT INTO US_POPULATION (STATE,CITY,POPULATION) SELECT STATE,CITY,POPULATION FROM AK_POPULATION WHERE POPULATION < 40000;
可以看到,Phoenix将源表中人口数少于4万的两个城市信息插入到了目标表中 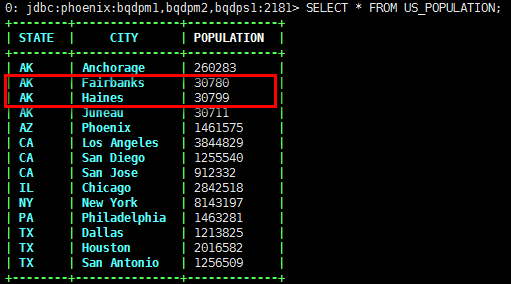
上面的sql语句中写明了插入的字段,如果本身这两张表完全相同,或者某些字段相同,可以直接这样写
UPSERT INTO US_POPULATION SELECT STATE,CITY,POPULATION FROM AK_POPULATION WHERE POPULATION > 40000;--或者UPSERT INTO US_POPULATION SELECT * FROM AK_POPULATION WHERE POPULATION > 40000;
注意:在phoenix中插入语句并不会像传统数据库一样存在重复数据。因为Phoenix是构建在HBase之上的,也就是必须存在一个主键。而US_POPULATION这张表的主键是由(state, city)共同决定的,因此只要这两个值相同的数据插入进去都是覆盖操作。下面这张图片就是US_POPULATION对应的HBase的主键字段 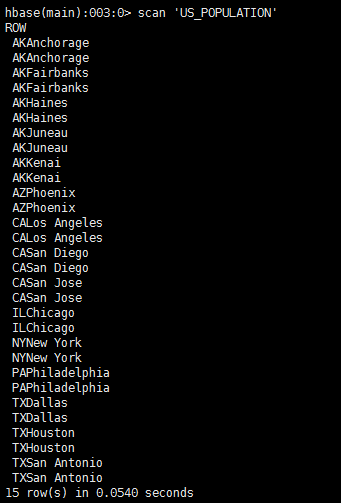
3.2.3 删除数据
删除数据和其他数据库相似
DELETE FROM US_POPULATION;DELETE FROM US_POPULATION WHERE CITY = 'Kenai';
可以看到 CITY = 'Kenai'的这条记录已经被删除了 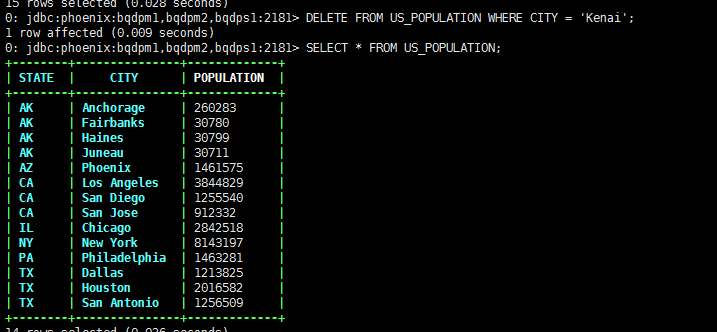
3.2.4 更新数据
由于HBase的主键设计,相同rowkey的内容可以直接覆盖,这就变相的更新了数据。所以Phoenix的更新操作仍旧是 3.2.1 的那两种
比如我想将US_POPULATION中CITY = 'Juneau'的人口数修改为40711
UPSERT INTO US_POPULATION (STATE,CITY,POPULATION) VALUES('AK','Juneau',40711);
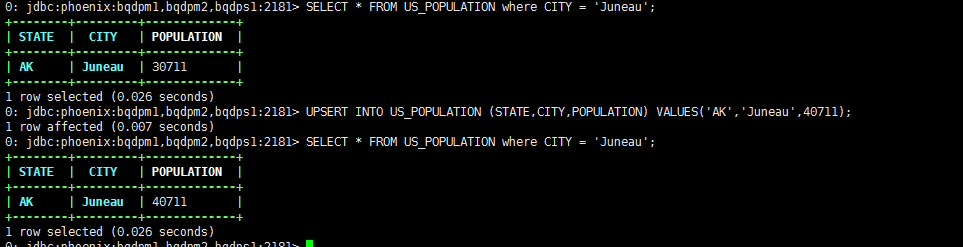
这里我们将全部字段都写出来了的,如果我只想操作一列,我能简化吗?
答案是可以,不过有个条件,就是必须包含生成HBase的rowkey的所有字段。否则会报以下错误: 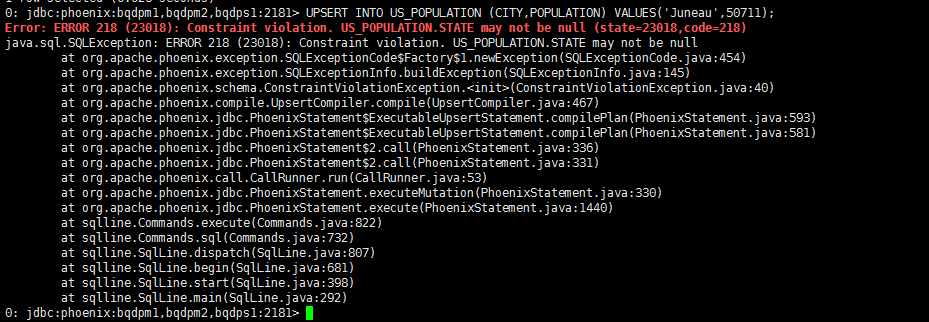
这里提示state不能为空,也就是组成rowkey的state和city字段缺一不可。其实很好理解,毕竟HBase所有的操作都是围绕着rowkey进行的。
3.2.5 查询数据
Phoenix作为SQL On HBase引擎必不可少的就是SQL查询语句了,他能兼容大部分的SQL查询语句,比如UNION ALL GROUP BY ORDER BY LIMIT
下面是一些简单的sql例子
SELECT * FROM TEST LIMIT 1000;SELECT * FROM TEST LIMIT 1000 OFFSET 100;SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0UNION ALL SELECT reviewer_name FROM CUSTOMER_REVIEW WHERE score >= 8.0
3.3 Phoenix的Schema操作
3.3.1 什么?没有DataBase?
在Phoenix中是没有Database的概念的,所有的表都在同一个命名空间。当然,Phoenix4.8开始支持多个命名空间了,在http://phoenix.apache.org/namspace_mapping.html 这个网页说明了如何将Schema映射到命名空间中。
<property><name>phoenix.schema.isNamespaceMappingEnabled</name><value>true</value></property>
这里一定要注意:如果设置为true,创建的带有schema的表将映射到一个namespace,这个需要客户端和服务端同时设置。一旦设置为true,就不能回滚了。旧的客户端将无法再正常工作。所以建议大家都查看官方文档,确定后再进行设置。
3.3.2 创建表
在官网上我们看到Phoenix创建表的定义是这样的: 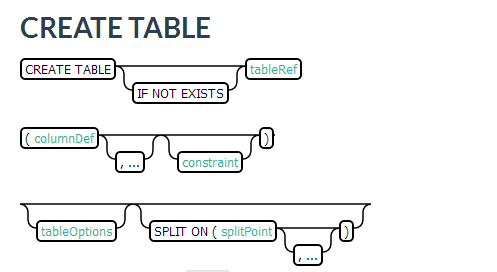
从这里我们可以猜测Phoenix建表的时候可以定义表的属性(包括了HBase的一些属性)以及预分区操作。
我们进入到tableOption下面可以看到SALT_BUCKETS, DISABLE_WAL, IMMUTABLE_ROWS, MULTI_TENANT, DEFAULT_COLUMN_FAMILY, STORE_NULLS, TRANSACTIONAL, and UPDATE_CACHE_FREQUENCY这些属性,下面我们就一一解答。
3.3.2.1 SALT_BUCKETS(加盐?)
Salting能够通过预分区(pre-splitting)数据到多个region中来显著提升读写性能。
Salting 翻译成中文是加盐的意思,本质是在hbase中,rowkey的byte数组的第一个字节位置设定一个系统生成的byte值,这个byte值是由主键生成rowkey的byte数组做一个哈希算法,计算得来的。Salting之后可以把数据分布到不同的region上,这样有利于phoenix并发的读写操作。关于SaltedTable的说明在 http://phoenix.apache.org/salted.html
CREATE TABLE TEST (HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR) SALT_BUCKETS=16;
SALT_BUCKETS的值范围在(1 ~ 256)
接下来就开始划重点了:
salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,也就避免了读写操作都集中在同一个region上。
简而言之,如果我们用Phoenix创建了一个saltedtable,那么向该表中写入数据时,原始的rowkey的前面会被自动地加上一个byte(不同的rowkey会被分配不同的byte),使得连续的rowkeys也能被均匀地分布到多个regions。
为了印证这一说法,我往TEST中添加几分数据看看
UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.1','S1');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.2','S2');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.3','S3');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.4','S4');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.5','S5');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.6','S6');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.7','S7');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.8','S8');UPSERT INTO TEST (HOST,DESCRIPTION) values ('192.168.0.9','S9');
此时的HBase中的数据为 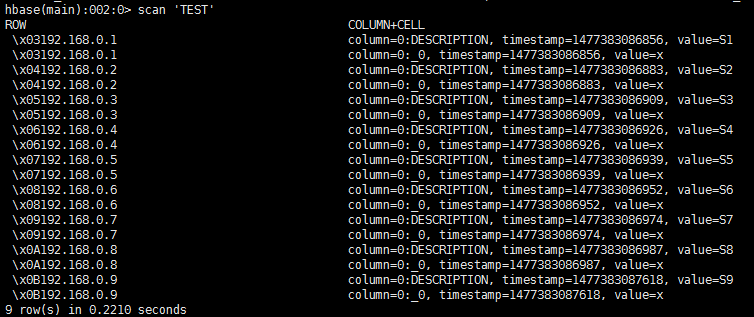
可以看到,在每条rowkey前面加了一个Byte,这里显示为了16进制。也正是因为添加了一个Byte,所以SALT_BUCKETS的值范围在必须再1 ~ 256之间。而添加的这个Byte是根据什么来分的我就不得而知了,所以最好不要使用HBase的API插入数据。
因此,在使用SALT_BUCKETS的时候需要注意以下两点:
创建salted table后,应该使用Phoenix SQL来读写数据,而不要混合使用Phoenix SQL和HBase API
如果通过Phoenix创建了一个salted table,那么只有通过Phoenix SQL插入数据才能使得被插入的原始rowkey前面被自动加上一个byte,通过HBase shell插入数据无法prefix原始的rowkey
3.3.2.2 Pre-split(预分区)
Salting能够自动的设置表预分区,但是你得去控制表是如何分区的,所以在建phoenix表时,可以精确的指定要根据什么值来做预分区,比如:
CREATE TABLE TEST (HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR) SPLIT ON ('CS','EU','NA');
3.3.2.3 使用多列族
列族包含相关的数据都在独立的文件中,在Phoenix设置多个列族可以提高查询性能。例如:
CREATE TABLE TEST (MYKEY VARCHAR NOT NULL PRIMARY KEY, A.COL1 VARCHAR,A.COL2 VARCHAR, B.COL3 VARCHAR);
插入下面的数据
UPSERT INTO TEST values ('key1','A1','B1','C1');UPSERT INTO TEST values ('key2','A2','B2','C2');UPSERT INTO TEST values ('key3','A3','B3','C3');UPSERT INTO TEST values ('key4','A4','B4','C4');UPSERT INTO TEST values ('key5','A5','B5','C5');UPSERT INTO TEST values ('key6','A6','B6','C6');UPSERT INTO TEST values ('key7','A7','B7','C7');UPSERT INTO TEST values ('key8','A8','B8','C8');UPSERT INTO TEST values ('key9','A9','B9','C9');
这样就有两个列族了 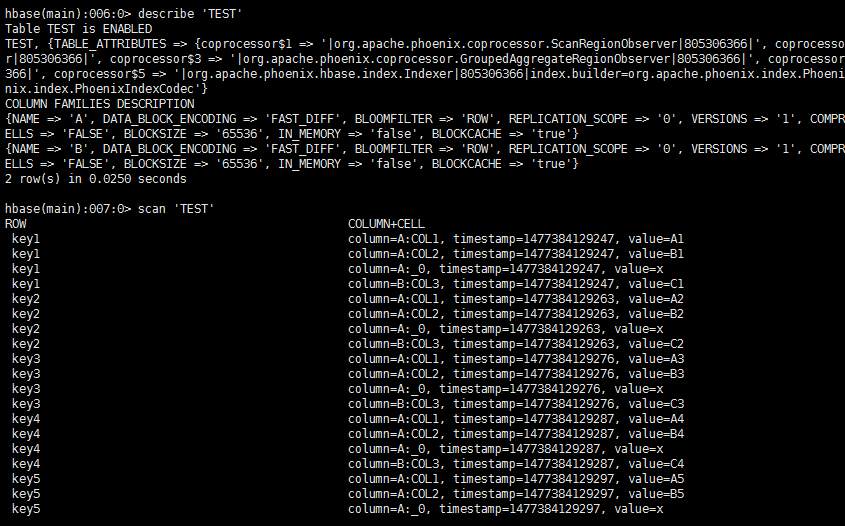
3.3.2.4 使用压缩
在数据量大的表上使用压缩算法来提高性能。
例如:
CREATE TABLE TEST (HOST VARCHAR NOT NULL PRIMARY KEY, DESCRIPTION VARCHAR) COMPRESSION='Snappy';

3.3.3 删除表
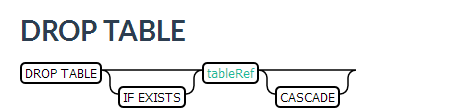
删除表和其他的数据库类似。不同的是可以加上CASCADE关键字,用于删除表的同时删除基于该表的所有视图。
DROP TABLE my_schema.my_table;DROP TABLE IF EXISTS my_table;DROP TABLE my_schema.my_table CASCADE;
3.3.4 创建视图
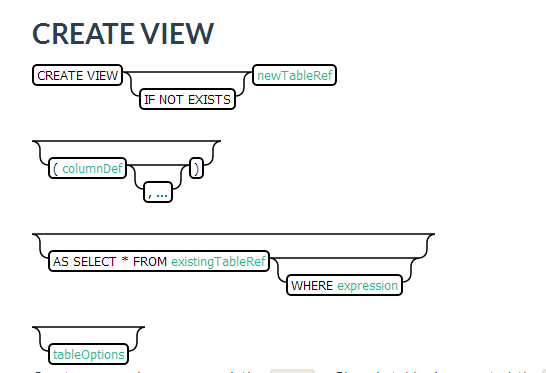
CREATE VIEW "my_hbase_table"( k VARCHAR primary key, "v" UNSIGNED_LONG) default_column_family='a';CREATE VIEW my_view ( new_col SMALLINT )AS SELECT * FROM my_table WHERE k = 100;CREATE VIEW my_view_on_viewAS SELECT * FROM my_view WHERE new_col > 70;
例子:
CREATE VIEW TEST_VIEW AS SELECT * FROM TEST where DESCRIPTION in ('S1','S2','S3')
结果: 
除此之外,我们还能在视图上创建视图 
Phoenix中的视图其实是不完美的
比如我执行
CREATE VIEW TEST_VIEW ( HOST VARCHAR) AS SELECT HOST FROM TEST where DESCRIPTION in ('S1','S2','S3');
就会报错 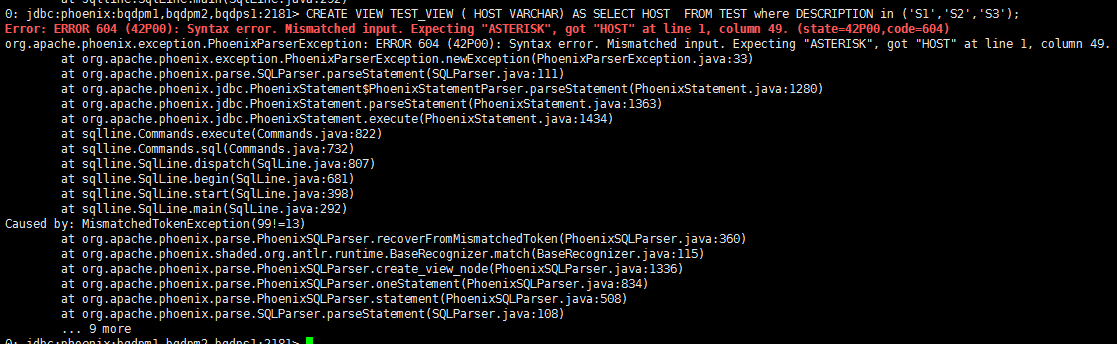
提示我必须带‘*’ ,所以它的视图是没办法只获取一部分数据的数据的,即使使用子查询也不行。
3.3.5 删除视图
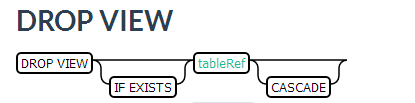
DROP VIEW my_viewDROP VIEW IF EXISTS my_schema.my_viewDROP VIEW IF EXISTS my_schema.my_view CASCADE
3.3.6 创建二级索引
参考:Phoenix二级索引
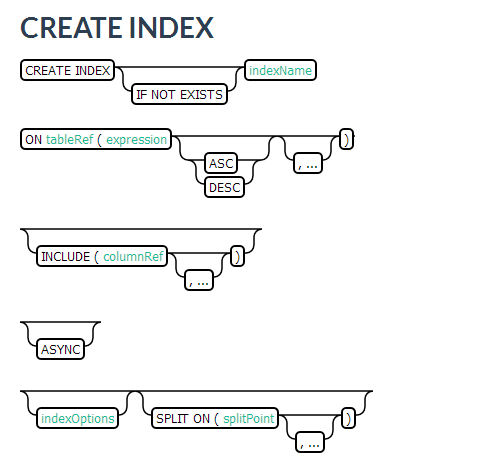
从Phoenix 2.1版本开始,Phoenix支持可变和不可变(数据插入后不再更新)数据建立二级索引。Phoenix 2.0版本仅支持在不可变数据建立二级索引。
CREATE INDEX my_idx ON sales.opportunity(last_updated_date DESC)CREATE INDEX my_idx ON log.event(created_date DESC) INCLUDE (name, payload) SALT_BUCKETS=10CREATE INDEX IF NOT EXISTS my_comp_idx ON server_metrics ( gc_time DESC, created_date DESC )DATA_BLOCK_ENCODING='NONE',VERSIONS=?,MAX_FILESIZE=2000000 split on (?, ?, ?)CREATE INDEX my_idx ON sales.opportunity(UPPER(contact_name))
假如我对TEST的HOST,DESCRIPTION创建索引,具体sql如下:
CREATE INDEX TEST_INDEX ON TEST (HOST) INCLUDE (DESCRIPTION);
结果报错 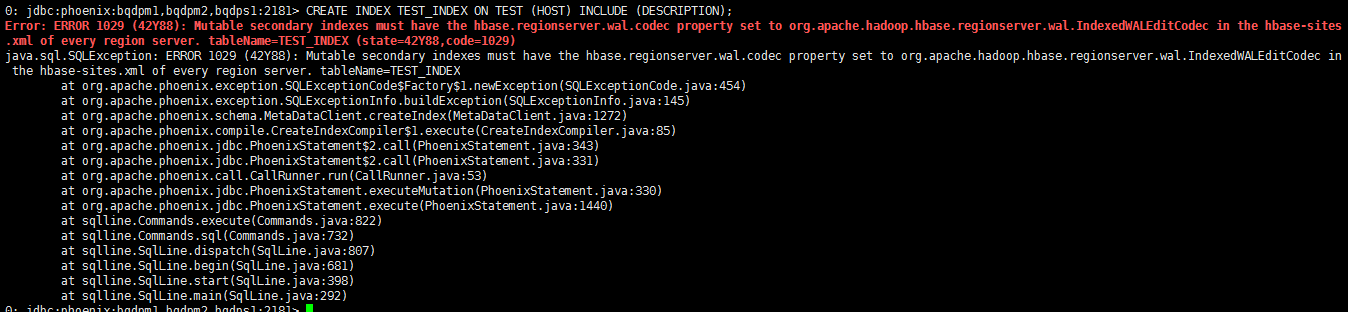
我们需要在每个region的hbase-site.xml中添加
<property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property>
开启可变索引需要在HMaster和RegionServer上加入特殊的选项,并且需要重启集群。配置方式如下:
- HMaster hbase-site.xml
<!-- Phoenix订制的索引负载均衡器 --><property><name>hbase.master.loadbalancer.class</name><value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value></property><!-- Phoenix订制的索引观察者 --><property><name>hbase.coprocessor.master.classes</name><value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value></property>
RegionServer hbase-site.xml
<!-- Enables custom WAL edits to be written, ensuring proper writing/replay of the index updates. This codec supports the usual host of WALEdit options, most notably WALEdit compression. --><property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property><!-- Prevent deadlocks from occurring during index maintenance for global indexes (HBase 0.98.4+ and Phoenix 4.3.1+ only) by ensuring index updates are processed with a higher priority than data updates. It also prevents deadlocks by ensuring metadata rpc calls are processed with a higher priority than data rpc calls --><property><name>hbase.region.server.rpc.scheduler.factory.class</name><value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><property><name>hbase.rpc.controllerfactory.class</name><value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property>
你可以在hbase-site.xml里配置以下参数
index.builder.threads.max
o 为主表更新操作建立索引的最大线程数
o Default: 10index.builder.threads.keepalivetime
o 上面线程的超时时间
o Default: 60index.writer.threads.max
o 将索引写到索引表的最大线程数
o Default: 10index.writer.threads.keepalivetime
o 上面线程的超时时间
o Default: 60hbase.htable.threads.max
o 同时最多有这么多线程往索引表写入数据
o Default: 2,147,483,647hbase.htable.threads.keepalivetime
o 上面线程的超时时间
o Default: 60index.tablefactory.cache.size
o 缓存10个往索引表写数据的线程
o Default: 10
CDH可以直接在CM中配置 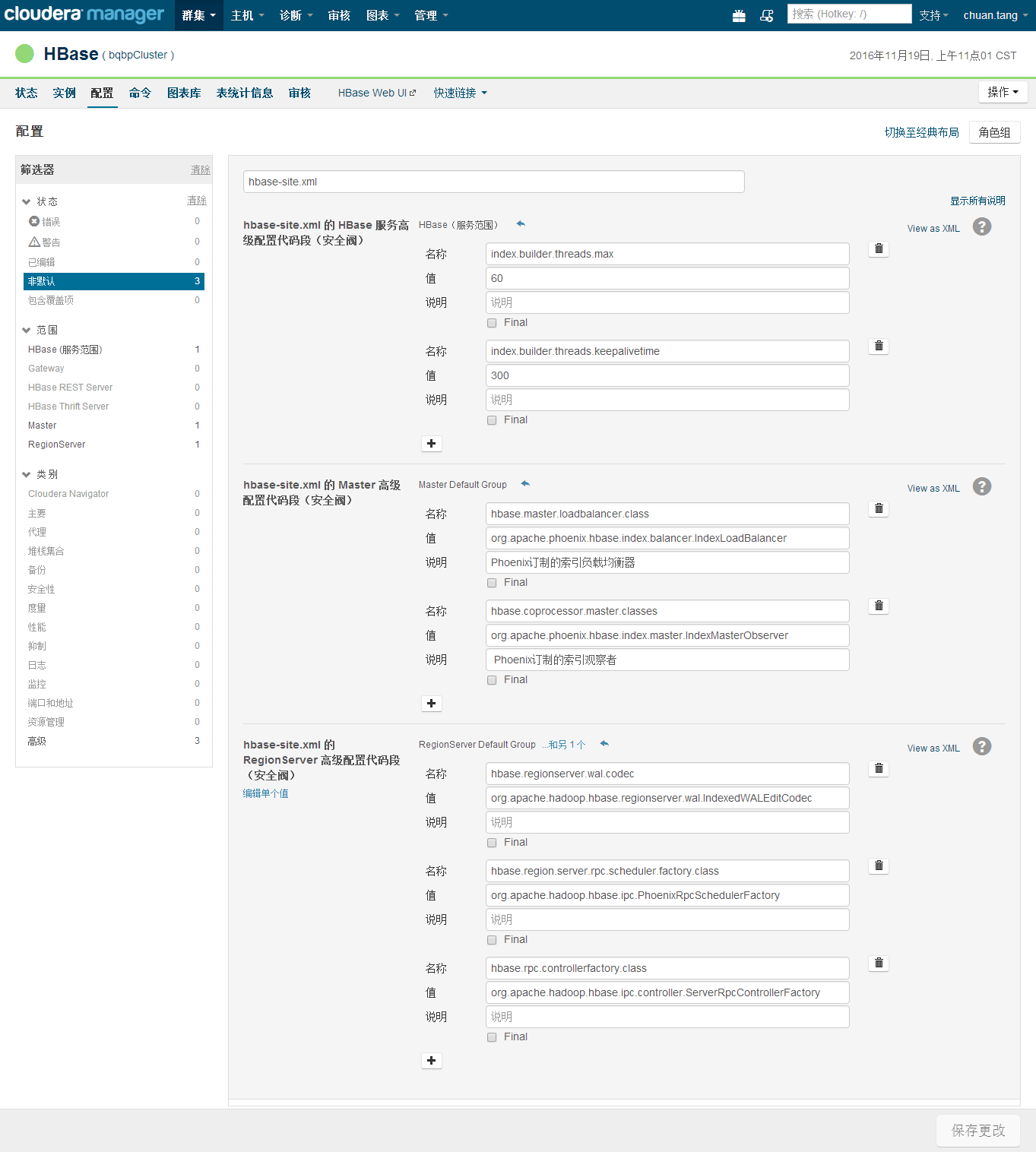
重启HBase之后即可 
3.3.7 删除索引

DROP INDEX my_idx ON sales.opportunityDROP INDEX IF EXISTS my_idx ON server_metrics
例如:
DROP INDEX IF EXISTS XDGL_ACCT_FEE_INDEX ON XDGL_ACCT_FEE
3.3.8 如何与现有的HBase表关联
前面我们提到了创建表和创建视图,但是我们都没有对现有的HBase表关联进行举例,因为这一场景其实是用的最多的,所以提出来单独讲。
使用Phoenix和HBase关联有两种方式:创建关联表和创建关联视图。
首先创建一张HBase表
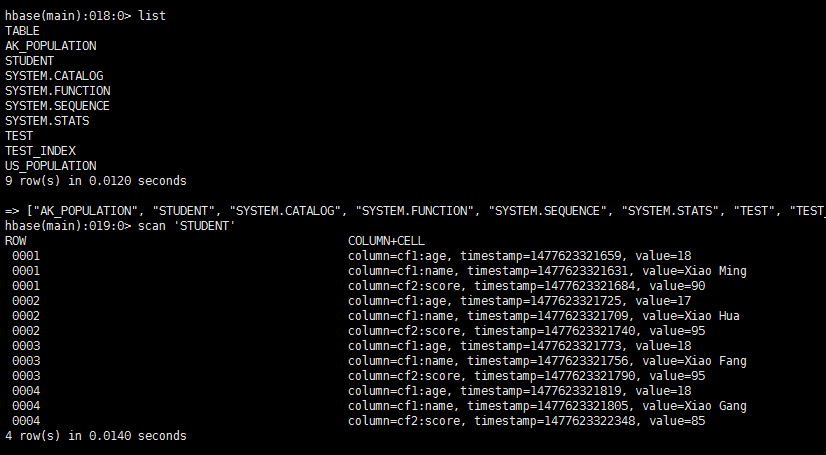
#创建STUDENT,包含cf1和cf2两个列族create 'STUDENT' ,'cf1','cf2'#往student里面添加数据。cf1包含了name和age信息,cf2包含了成绩信息put 'STUDENT','0001','cf1:name','Xiao Ming'put 'STUDENT','0001','cf1:age','18'put 'STUDENT','0001','cf2:score','90'put 'STUDENT','0002','cf1:name','Xiao Hua'put 'STUDENT','0002','cf1:age','17'put 'STUDENT','0002','cf2:score','95'put 'STUDENT','0003','cf1:name','Xiao Fang'put 'STUDENT','0003','cf1:age','18'put 'STUDENT','0003','cf2:score','95'put 'STUDENT','0004','cf1:name','Xiao Gang'put 'STUDENT','0004','cf1:age','18'put 'STUDENT','0004','cf2:score','85'
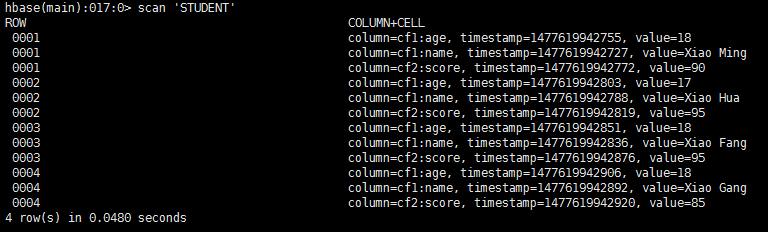
接下来对两种模式进行介绍:
3.3.8.1 创建关联表
--创建的Phoenix表名必须和HBase表名一致CREATE TABLE STUDENT (--这句话直接写就可以了,这样的话,HBase中的RowKey转换成phoenix中的主键,列名就叫自取。--rowkey自动会和primary key进行对应。id VARCHAR NOT NULL PRIMARY KEY ,--将名为cf1的列族下,字段名为name的字段,写在这里。"cf1"."name" VARCHAR ,--下面就以此类推"cf1"."age" VARCHAR ,"cf2"."score" VARCHAR)
此时可以在Phoenix上进行增删改查 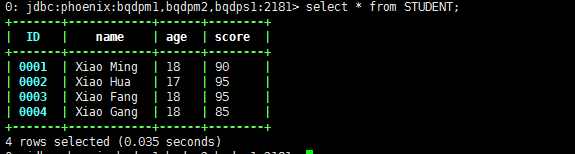
如果在Phoenix上删除数据 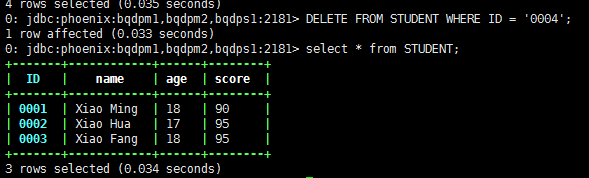
对应的HBase也会删除数据 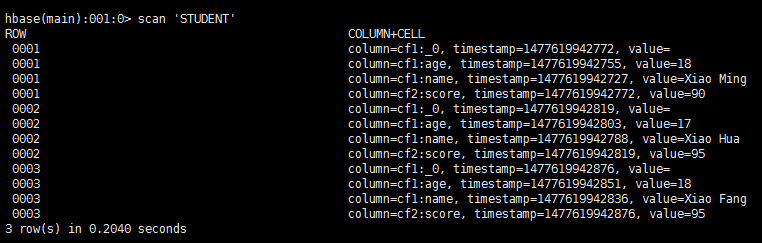
同理,增加和修改也会修改HBase的数据
删除数据会修改HBase的数据,如果我整个表删除掉会怎么样呢?
在Phoenix上执行
DROP TABLE IF EXISTS STUDENT
此时在HBase中已经看不到我们创建的Student表了 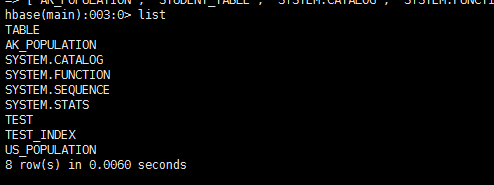
因此,Phoenix删除了表,会将HBase的表也删掉。这点非常重要。
3.3.8.2 创建关联视图
创建关联视图和创建关联表基本一样,只是将CREATE TABLE替换成了CREATE VIEW
--创建的Phoenix表名必须和HBase表名一致CREATE VIEW STUDENT (--这句话直接写就可以了,这样的话,HBase中的RowKey转换成phoenix中的主键,列名就叫自取。--rowkey自动会和primary key进行对应。id VARCHAR NOT NULL PRIMARY KEY ,--将名为cf1的列族下,字段名为name的字段,写在这里。"cf1"."name" VARCHAR ,--下面就以此类推"cf1"."age" VARCHAR ,"cf2"."score" VARCHAR)
此时我们对STUDENT视图进行插入、更新或者删除数据操作会报表是只读的错误 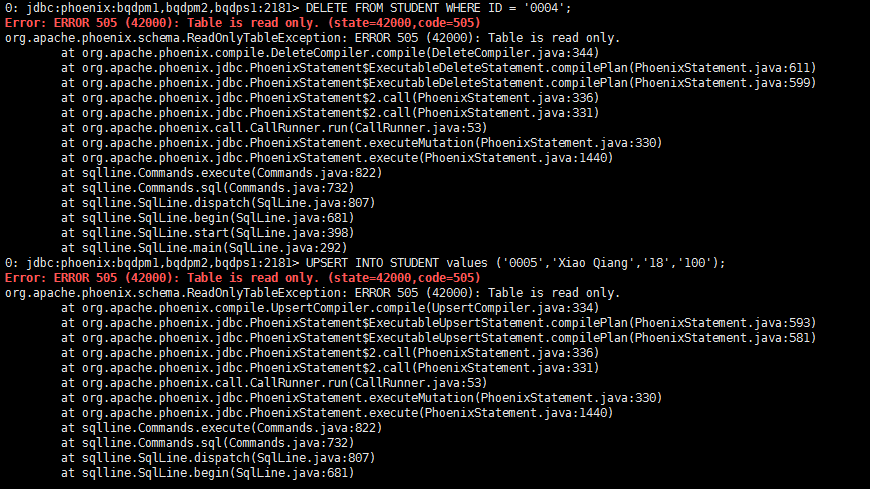
不仅如此,我们删除student这个view,对HBase的数据不会有任何影响 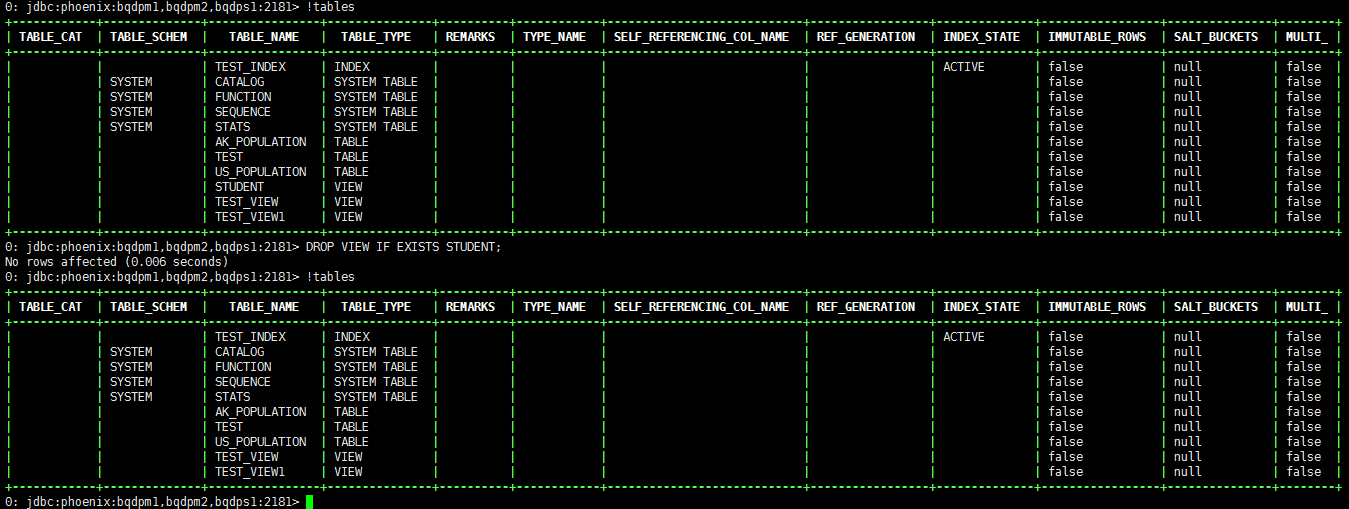
那么如何往关联的视图中插入数据呢?
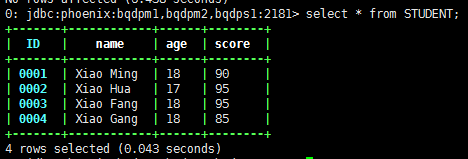
只能通过HBase来操作了。往HBase中插入一条新的数据
put 'STUDENT','0005','cf1:name','Xiao Qiang'put 'STUDENT','0005','cf1:age','18'put 'STUDENT','0005','cf2:score','100'
此时在Phoenix中的数据也会随之增加 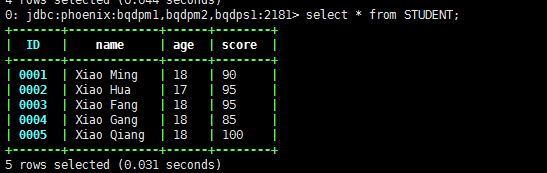
3.3.8.3 总结
- 创建HBase的关联表:
- Phoenix的表名必须和HBase相同
- 主键必须不为空
- 在Phoenix上的所有操作都会影响HBase的数据
- 删除了Phoenix上的表就等于删除了HBase的表
适用于经常在Phoenix上进行增删改的操作
创建HBase的关联视图:
- Phoenix的表名必须与HBase相同
- 主键不能为空
- Phoenix上无法对HBase的数据进行修改,只能做查询用
- 删除Phoenix的视图不会对HBase有任何影响
- 适用于HBase数据读写分离,Phoenix只做分析查询使用
3.4 使用Spark操作Phoenix
3.4.1 添加phoenix-spark的仓库依赖
首先登录nexus私服的账户,添加新的Jar文件。 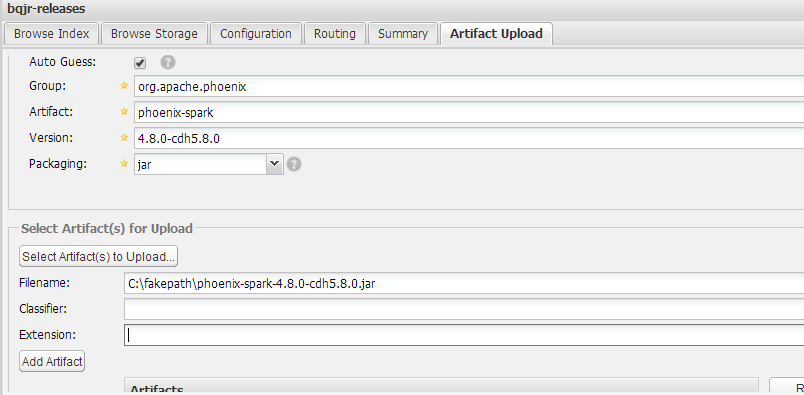
最后我们可以在nexus上看到我们的jar包了。我们可以根据maven的xml里面添加依赖 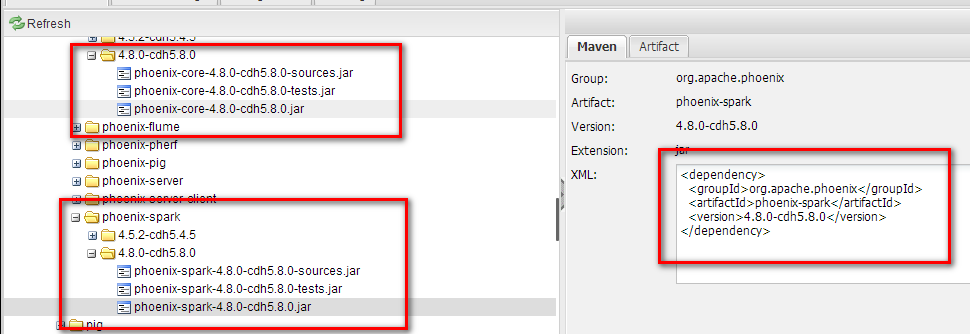
然后在sbt工程中将其添加进去 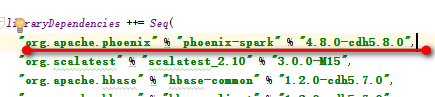
3.4.2 在Spark运行环境中添加Phoenix依赖
通过Spark操作Phoenix必须要通过phoenix-spark-4.8.0-cdh5.8.0.jar这个包,如果每次使用Phoenix都自己指定一次这个文件路径会比较麻烦,因此最好将这个文件添加到HBase的lib下,然后在spark-env.sh中指定一下。如果是CDH的环境可以直接在CM上的spark->配置->高级->spark-conf/spark-env.sh 的 Spark 客户端高级配置代码段(安全阀)中添加如下代码
#添加Phoenix依赖for file in $(find /opt/cloudera/parcels/CDH/lib/hbase/lib/ |grep phoenix)doSPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:$file"doneexport SPARK_DIST_CLASSPATH
这样每次启动spark任务都会将phoenix的jar包添加到classpath了
3.5.1 使用Data Source API加载Phoenix数据
通过DataFr的DataSource API可以加载Phoenix的数据
import org.apache.spark.SparkContextimport org.apache.spark.sql.SQLContextimport org.apache.phoenix.spark._val sparkConf = new SparkConf()val sc = new SparkContext(sparkConf)val sqlContext = new SQLContext(sc)val df = sqlContext.read.options(Map("table" -> "STUDENT", "zkUrl" -> "bqdpm1,bqdpm2,bqdps1:2181")).format("org.apache.phoenix.spark").loaddf.show
结果输出 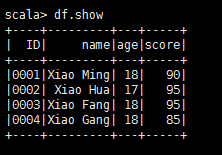
3.5.2 使用Configuration类创建DataFrame
除了上述的方法,Phoenix-spark为我们提供了一个专用的API,其定义如下:
def phoenixTableAsDataFrame(table: String, columns: Seq[String],predicate: Option[String] = None, zkUrl: Option[String] = None,conf: Configuration = new Configuration): DataFrame = {// Create the PhoenixRDD and convert it to a DataFramenew PhoenixRDD(sqlContext.sparkContext, table, columns, predicate, zkUrl, conf).toDataFrame(sqlContext)}
下面是一个实际的例子
import org.apache.hadoop.conf.Configurationimport org.apache.spark.SparkContextimport org.apache.spark.sql.SQLContextimport org.apache.phoenix.spark._val sparkConf = new SparkConf()val sc = new SparkContext(sparkConf)val sqlContext = new SQLContext(sc)val configuration = new Configuration()configuration.set("hbase.zookeeper.quorum","bqdpm1,bqdpm2,bqdps1")val df = sqlContext.phoenixTableAsDataFrame("STUDENT",Array("ID","name","age"),conf = configuration)df.show
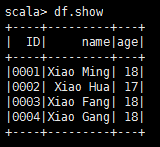
3.5.3 使用Zookeeper URL创建RDD
当然,我们也可以建立RDD
def phoenixTableAsRDD(table: String, columns: Seq[String], predicate: Option[String] = None,zkUrl: Option[String] = None, conf: Configuration = new Configuration()): RDD[Map[String, AnyRef]] = {// Create a PhoenixRDD, but only return the serializable 'result' mapnew PhoenixRDD(sc, table, columns, predicate, zkUrl, conf).map(_.result)}
实际例子如下
import org.apache.hadoop.conf.Configurationimport org.apache.spark.SparkContextimport org.apache.phoenix.spark._val sparkConf = new SparkConf()val sc = new SparkContext(sparkConf)val rdd = sc.phoenixTableAsRDD("STUDENT",Array("ID","name","age"),zkUrl = Some("bqdpm1,bqdpm2,bqdps1:2181"))rdd.countrdd.collect()

3.5.4 保存到Phoenix
可以将Spark中的数据,无论是RDD还是DataFrame都可以将数据保存到Phoenix中
- 保存RDD到Phoenix
下面是将RDD保存到Phoenix的方法
import org.apache.hadoop.conf.Configurationimport org.apache.spark.SparkContextimport org.apache.phoenix.spark._val sparkConf = new SparkConf()val sc = new SparkContext(sparkConf)val dataSet = List(("0005","Zhang San","20","70"),("0006","Li Si","20","82"),("0005","Wang Wu","19","90"))sc.parallelize(dataSet).saveToPhoenix("STUDENT",Seq("ID","name","age","score"),zkUrl = Some("bqdpm1,bqdpm2,bqdps1:2181"))
结果输出 
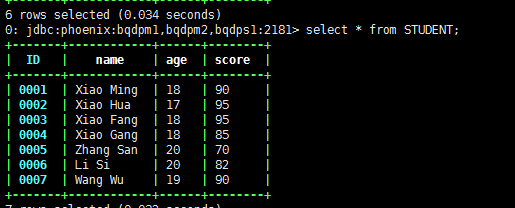
假设我们将
sc.parallelize(dataSet).saveToPhoenix("STUDENT",Seq("ID","name","age","score"),zkUrl = Some("bqdpm1,bqdpm2,bqdps1:2181"))
改成
sc.parallelize(dataSet).saveToPhoenix("STUDENT",Seq("ID","NAME","AGE","SCORE"),//或者 Seq("ID","Name","Age","Score")zkUrl = Some("bqdpm1,bqdpm2,bqdps1:2181"))
结果会报错 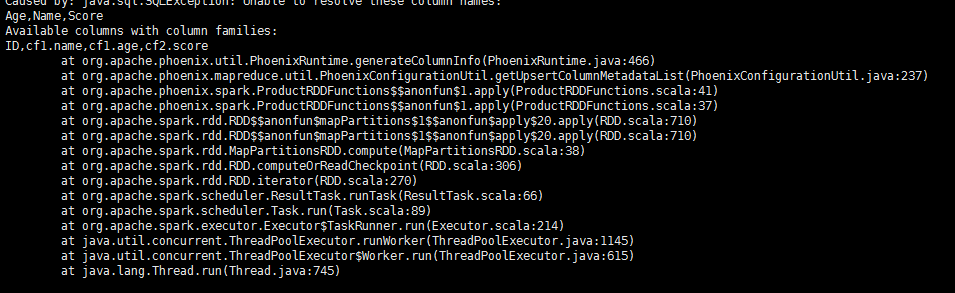
提示我们列对应不上。由此可见 通过Spark操作Phoenix是需要区分大小写的。这点非常重要,后面我们还会提到。
- 保存DataFrame到Phoenix
官网给出了个例子将DataFrame保存到Phoenix中,以下是我的测试代码
case class Student(ID:String,Name:String,Age:String,Score:String)val dataSet = List(Student("0008","Ma Liu","18","95"),Student("0009","Zhao Qi","19","80"),Student("0010","Liu Ba","19","100"))val df = sqlContext.createDataFrame(dataSet)df.write.format("org.apache.phoenix.spark").mode( SaveMode.Overwrite).options(Map("table" -> "STUDENT", "zkUrl" -> "bqdpm1,bqdpm2,bqdps1:2181")).save()
运行接错报错,提示列对不上?难道不支持将数据写到多个列族? (请看下节) 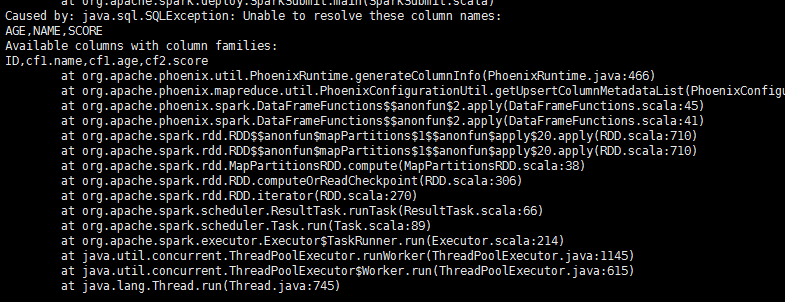
然后我重新使用官网的例子来验证。
首先在Phoenix上创建一张OUTPUT_TABLE的表
CREATE TABLE OUTPUT_TABLE (id BIGINT NOT NULL PRIMARY KEY, col1 VARCHAR, col2 INTEGER);
然后将DataFrame保存到Phoenix中
case class Student(ID:Long,col1:String,col2:Int)val dataSet = List(Student(1,"Ma Liu",18),Student(2,"Zhao Qi",19),Student(3,"Liu Ba",19))val df = sqlContext.createDataFrame(dataSet)df.write.format("org.apache.phoenix.spark").mode( SaveMode.Overwrite).options(Map("table" -> "OUTPUT_TABLE", "zkUrl" -> "bqdpm1,bqdpm2,bqdps1:2181")).save()
结果成功了 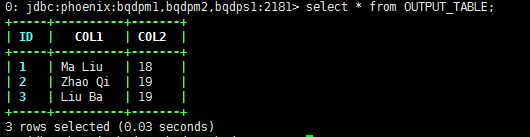
我们将case class Student(ID:Long,col1:String,col2:Int)换成case class Student(ID:Long,Col1:String,Col2:Int)
再次执行,也是成功的
3.5.3 使用Spark保存Phoenix数据的列有什么要求?
在前面我们尝试使用RDD和DataFrame保存数据到Phoenix,发现两者在列的支持上是有一些不同的。
我尝试从源码的角度来分析
- RDD
在调用
sc.parallelize(dataSet).saveToPhoenix("STUDENT",Seq("ID","NAME","AGE","SCORE"),//或者 Seq("ID","Name","Age","Score")zkUrl = Some("bqdpm1,bqdpm2,bqdps1:2181"))
的时候,Phoenix的API将Column原原本本作为输出的Column名 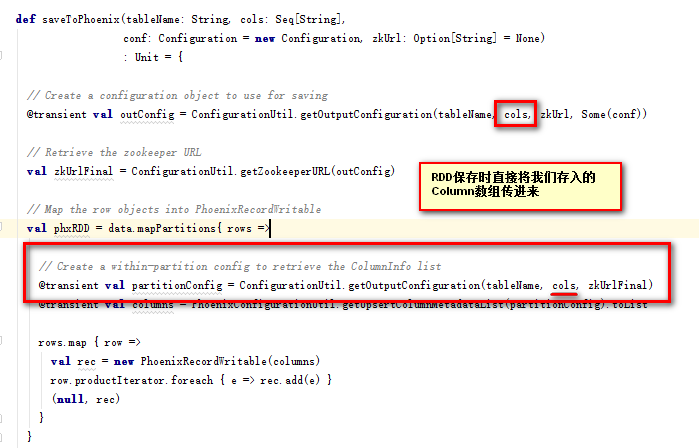
所以使用RDD的saveToPhoenix函数时必须严格按照Phoenix的Column名的大小写来输入
- DataFrame
在使用DataFrame保存的时候,我们用了
df.write.format("org.apache.phoenix.spark").mode( SaveMode.Overwrite).options(Map("table" -> "STUDENT1", "zkUrl" -> "bqdpm1,bqdpm2,bqdps1:2181")).save()
也就是说借助了org.apache.phoenix.spark里面的隐式函数
implicit def toDataFrameFunctions(data: DataFrame): DataFrameFunctions = {new DataFrameFunctions(data)}
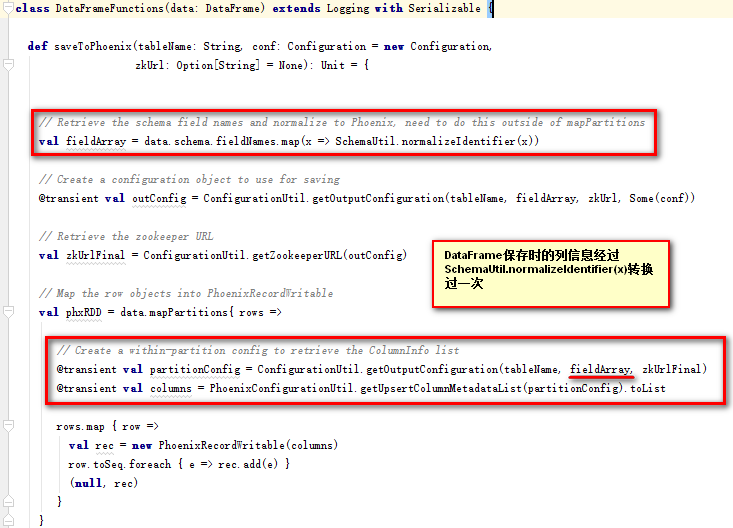
而这个SchemaUtil.normalizeIdentifier(x)仅仅只是将字符串里面的引号去掉,然后转成大写
public static String normalizeIdentifier(String name) {if (name == null) {return name;}if (isCaseSensitive(name)) {// Don't upper case if in quotesreturn name.substring(1, name.length()-1);}return name.toUpperCase();}
也就是说不管我们的DataFrame的列是什么格式,最终都会转成大写。
然后Phoenix里面的列可能不是大写的,所以就可能出现列名是对的,但是大小写对应不上的尴尬局面,并非Phoenix不能写入大写数据。
为了验证这一个猜想,我们再次建立了一张通过Phoenix关联HBase已有的表Student1
create 'STUDENT1' ,'cf1','cf2'put 'STUDENT1','0001','cf1:NAME','Xiao Ming'put 'STUDENT1','0001','cf1:AGE','18'put 'STUDENT1','0001','cf2:SCORE','90'
CREATE TABLE STUDENT1 (ID VARCHAR NOT NULL PRIMARY KEY ,"cf1"."NAME" VARCHAR ,"cf1"."AGE" VARCHAR ,"cf2"."SCORE" VARCHAR)
再次执行
case class Student(ID:Long,col1:String,col2:Int)val dataSet = List(Student(1,"Ma Liu",18),Student(2,"Zhao Qi",19),Student(3,"Liu Ba",19))val df = sqlContext.createDataFrame(dataSet)df.write.format("org.apache.phoenix.spark").mode( SaveMode.Overwrite).options(Map("table" -> "OUTPUT_TABLE", "zkUrl" -> "bqdpm1,bqdpm2,bqdps1:2181")).save()
这次也没用报错了 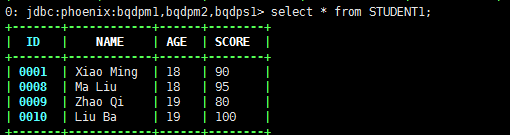
结论:
在使用RDD保存数据到Phoenix的时候,要严格按照Phoenix列名的大小写来输入
使用DataFrame保存的时候,对数据源的列名大小写无要求。但是必须保证Phoenix的表列名必须是大写的
HBase建表的时候,我们建议您对表名和列都使用大写
使用Phoenix创建表的时候,除非是已经存在了HBase的表,否则无需要建表的时候对列带引号,这样sql中即使是小写的列也会保存为大写,比如:
--创建的Phoenix表名必须和HBase表名一致CREATE TABLE STUDENT3 (--这句话直接写就可以了,这样的话,HBase中的RowKey转换成phoenix中的主键,列名就叫自取。--rowkey自动会和primary key进行对应。ID VARCHAR NOT NULL PRIMARY KEY ,--将名为cf1的列族下,字段名为name的字段,写在这里。cf1.name VARCHAR ,--下面就以此类推cf1.age VARCHAR ,cf2.score VARCHAR)

3.5.4 通过Phoenix取数据和直接通过代码取数据性能差别有多大
下图是通过Phoenix取数据的每面请求条数 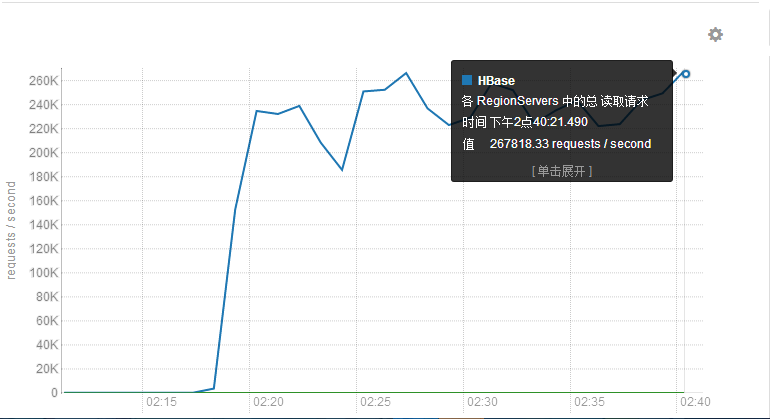
同样的逻辑,最开始使用Scan的时候只有50000 requests/secend,两者性能差别非常大。
以前从HBase需要4个小时才能拿完的数据,现在只需要一个小时了.