1、int[] nums = new int[7]; 这一条语句分为3个步骤:
1)声明一个int数组变量,数组变量是数组对象的遥控器
2)创建大小为7的数组
3)将数组赋值给之前声明为int[]的变量nums
同理,Dog[] dogs = new Dogs[3] 也是这几个步骤,不过它声明的是Dog数组变量
数组一定是个对象,不管所声明的元素是否为基础数据类型。并且没有基础数据类型的数组,只有装载基础数据类型的数组。没有装载对象类型的数组,只有装载对象引用(遥控器)数据类型的数组
2、抽象类也有构造函数,虽然你不能直接对抽象类执行new操作,但是它的构造函数会在具体子类创建实例时执行
public abstract class Test {
public Test(){
System.out.println("抽象类Test的构造函数被调用");
}
public abstract void f();
}
public class TestMain extends Test{
public void f(){
System.out.println("子类实现了f方法");
}
public TestMain(){
}
public static void main(String[] args) {
TestMain tm = new TestMain();
}
}运行结果:抽象类Test的构造函数被调用
3、在java中的常量,是把变量同时标记为static和final的。java常量必须在声明或静态初始化程序中赋值
public class Test{
//第一种,在声明时赋值
public static final int ME = 1;
//第二种,在静态初始化函数中赋值
public static final int MEO;
static{
MEO = 5;
}
}4、将String转换成基本数据类型,例如:int x = Integer.parseInt("2"); double y = Double.parseDouble("11.2"); boolean a = new Boolean("true").booleanValue(); 需要留意一下boolean的转换
5、将基本数据类型转换成String,有好几种方式
//第一种,直接加引号
double m = 42.1678;
String doubleString = m + "";
//第二种,toString
String doubleString2 = Double.toString(m);
//第三种,格式化
String doubleString3 = String.format("The num is %,6.2f", m);6、将序列化对象写入文件
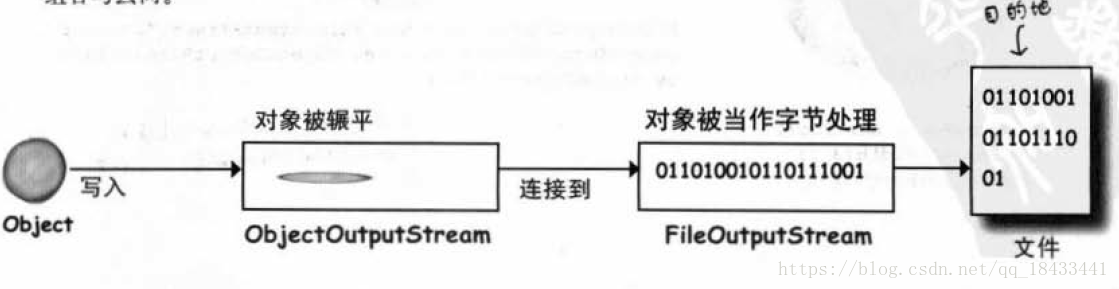
//创建FIleOutputStream对象
FileOutputStream fileStream = new FileOutputStream("myGame.ser");//如果文件不存在,它会自动创建出来
//创建ObjectOutputStream对象
ObjectOutputStream os = new ObjectOutputStream(fileStream);
//ObjectOutputStream 能让你写入对象,但是无法直接连接文件,所以需要参数的指引
os.writeObject(object_one);
os.writeObject(object_two);
os.close();对象序列化的原理:在堆上的对象有状态——实例变量的值。这些值让同一个类的不同实例有不同意义。 序列化的对象保存了实例变量的值,因此之后可以在堆上带回一模一样的实例
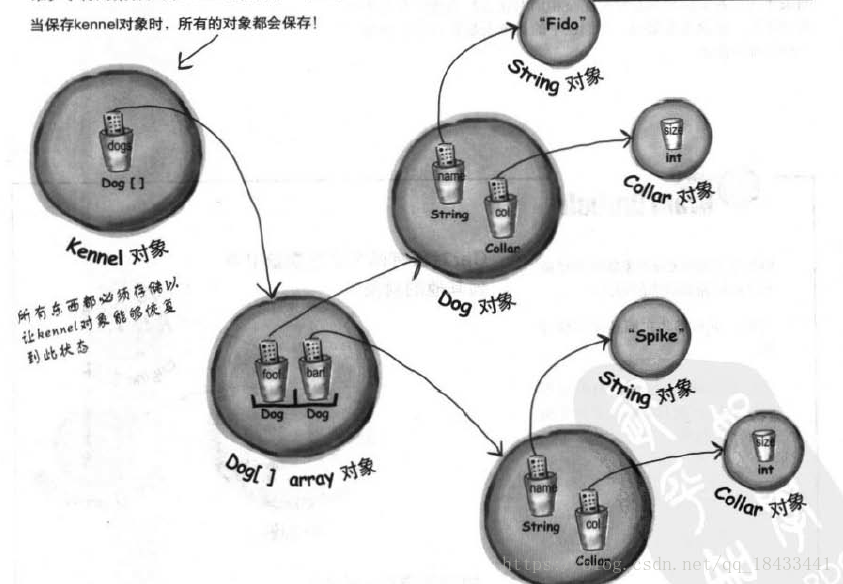
对象序列化时,基础数据类型的实例变量很好保存,那对象引用数据类型的实例变量怎么保存呢?
答:当对象被序列化时,被该对象引用的实例变量也会被序列化。且所有被引用的对象也会被序列化。 最棒的是,这些操作都是自动进行的。但是要求引用到的所有对象都是可序列化的,即实现Serializable。那如果我就是不想让一些实例变量序列化,该如何做呢?就在那个实例变量前面加上transient,这样程序就会跳过这个变量
tip:如果某类是可序列化的,则它的子类也自动地可序列化(接口的本意就是如此)
7、锁是对象的,不是方法的。如果对象有两个同步化的方法,就表示两个线程无法进入该对象的同一个方法,也表示两个线程无法进入该对象不同的方法。也就是说并没有其他线程已经进入的情况下,才能进入。(只有一把钥匙)
同步化的意义是某段工作要在不能分割的状态下进行
8、类也有锁,用来实现静态方法的同步化。所以如果有3个Dog对象在堆上,则总共有4个与Dog有关的锁,3个是实例的,1个是类的
9、为什么不同对象会有相同的hashcode的可能?
因为hashCode()所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越是糟糕的杂凑算法,越容易碰撞。
10、HashSet使用hashcode来达成存储速度较快的存储方法。它使用hashcode来寻找符合条件的元素,不必像ArrayList一样从头一个一个找。
当HashSet发现同样的hashcode有多个对象,它会使用equals()来判断是否有完全的符合。也就是说,hashcode是用来缩小寻找成本,但最后还是要用equals()才能认定是否真的找到相同的项目