用redis实现消息队列(实时消费+ack机制)
java queue 消息队列 redis
消息队列
首先做简单的引入。
MQ主要是用来:
解耦应用、
异步化消息
流量削峰填谷
目前使用的较多的有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ等。
网上的资源对各种情况都有详细的解释,在此不做过多赘述。
本文仅介绍如何使用Redis实现轻量级MQ的过程。
为什么要用Redis实现轻量级MQ?
在业务的实现过程中,就算没有大量的流量,解耦和异步化几乎也是处处可用,此时MQ就显得尤为重要。但与此同时MQ也是一个蛮重的组件,例如我们如果用RabbitMQ就必须为它搭建一个服务器,同时如果要考虑可用性,就要为服务端建立一个集群,而且在生产如果有问题也需要查找功能。在中小型业务的开发过程中,可能业务的其他整个实现都没这个重。过重的组件服务会成倍增加工作量。
所幸的是,Redis提供的list数据结构非常适合做消息队列。
但是如何实现即时消费?如何实现ack机制?这些是实现的关键所在。
如何实现即时消费?
网上所流传的方法是使用Redis中list的操作BLPOP或BRPOP,即列表的阻塞式(blocking)弹出。
让我们来看看阻塞式弹出的使用方式:
BRPOP key [key …] timeout
此命令的说明是:

1、当给定列表内没有任何元素可供弹出的时候,连接将被 BRPOP 命令阻塞,直到等待超时或发现可弹出元素为止。
2、当给定多个key参数时,按参数 key 的先后顺序依次检查各个列表,弹出第一个非空列表的尾部元素。
另外,BRPOP 除了弹出元素的位置和 BLPOP 不同之外,其他表现一致。
以此来看,列表的阻塞式弹出有两个特点:
1、如果list中没有任务的时候,该连接将会被阻塞
2、连接的阻塞有一个超时时间,当超时时间设置为0时,即可无限等待,直到弹出消息
由此看来,此方式是可行的,但此为传统的观察者模式,业务简单则可使用,如A的任务只由B去执行。但如果A和Z的任务,B和C都能执行,那使用这种方式就相形见肘。这个时候就应该使用订阅/发布模式,使业务系统更加清晰。
好在Redis也支持Pub/Sub(发布/订阅)。在消息A入队list的同时发布(PUBLISH)消息B到频道channel,此时已经订阅channel的worker就接收到了消息B,知道了list中有消息A进入,即可循环lpop或rpop来消费list中的消息。流程如下:
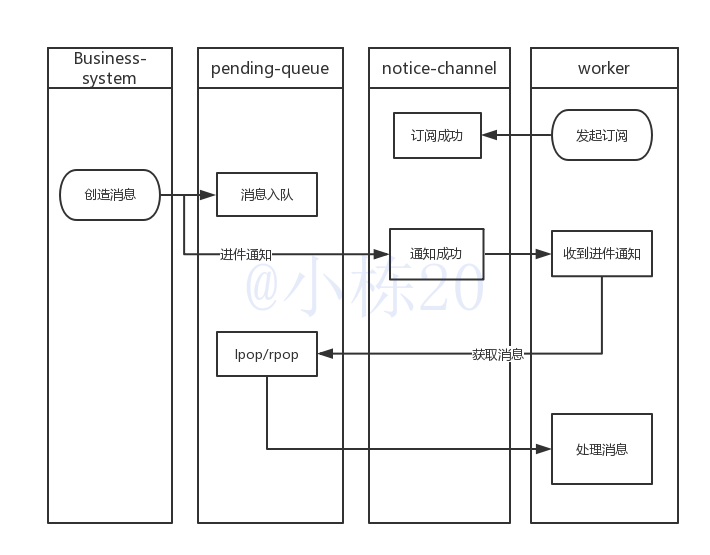
其中的worker可以是单独的线程,也可以是独立的服务,其充当了Consumer和业务处理者角色。下面做实例说明。
即时消费实例
示例场景为:worker要做同步文件功能,等到有文件生成时立马同步。
首先开启一个线程代表worker,来订阅频道channel:
@Service
public class SubscribeService {
@Resource
private RedisService redisService;
@Resource
private SynListener synListener;//订阅者
@PostConstruct
public void subscribe() {
new Thread(new Runnable() {
@Override
public void run() {
LogCvt.info("服务已订阅频道:{}", channel);
redisService.subscribe(synListener, channel);
}
}).start();
}
}
代码中的SynListener即为所声明的订阅者,channel为订阅的频道名称,具体的订阅逻辑如下:
@Service
public class SynListener extends JedisPubSub {
@Resource
private DispatchMessageHandler dispatchMessageHandler;
@Override
public void onMessage(String channel, String message) {
LogCvt.info("channel:{},receives message:{}",channel,message);
try {
//处理业务(同步文件)
dispatchMessageHandler.synFile();
} catch (Exception e) {
LogCvt.error(e.getMessage(),e);
}
}
}
处理业务的时候,就去list中去消费消息:
@Service
public class DispatchMessageHandler {
@Resource
private RedisService redisService;
@Resource
private MessageHandler messageHandler;
public void synFile(){
while(true){
try {
String message = redisService.lpop(RedisKeyUtil.syn_file_queue_key());
if (null == message){
break;
}
Thread.currentThread().setName(Tools.uuid());
// 队列数据处理
messageHandler.synfile(message);
} catch (Exception e) {
LogCvt.error(e.getMessage(),e);
}
}
}
}
这样我们就达到了消息的实时消费的目的。
如何实现ack机制?
ack,即消息确认机制(Acknowledge)。
首先来看RabbitMQ的ack机制:
Publisher把消息通知给Consumer,如果Consumer已处理完任务,那么它将向Broker发送ACK消息,告知某条消息已被成功处理,可以从队列中移除。如果Consumer没有发送回ACK消息,那么Broker会认为消息处理失败,会将此消息及后续消息分发给其他Consumer进行处理(redeliver flag置为true)。
这种确认机制和TCP/IP协议确立连接类似。不同的是,TCP/IP确立连接需要经过三次握手,而RabbitMQ只需要一次ACK。
值的注意的是,RabbitMQ当且仅当检测到ACK消息未发出且Consumer的连接终止时才会将消息重新分发给其他Consumer,因此不需要担心消息处理时间过长而被重新分发的情况。
那么在我们用Redis实现消息队列的ack机制的时候该怎么做呢?
需要注意两点:
work处理失败后,要回滚消息到原始pending队列
假如worker挂掉,也要回滚消息到原始pending队列
上面第一点可以在业务中完成,即失败后执行回滚消息。
实现方案
(该方案主要解决worker挂掉的情况)
维护两个队列:pending队列和doing表(hash表)。
workers定义为ThreadPool。
由pending队列出队后,workers分配一个线程(单个worker)去处理消息——给目标消息append一个当前时间戳和当前线程名称,将其写入doing表,然后该worker去消费消息,完成后自行在doing表擦除信息。
启用一个定时任务,每隔一段时间去扫描doing队列,检查每隔元素的时间戳,如果超时,则由worker的ThreadPoolExecutor去检查线程是否存在,如果存在则取消当前任务执行,并把事务rollback。最后把该任务从doing队列中pop出,再重新push进pending队列。
在worker的某线程中,如果处理业务失败,则主动回滚,并把任务从doing队列中移除,重新push进pending队列。
总结
Redis作为消息队列是有很大局限性的。因为其主要特性及用途决定它只能实现轻量级的消息队列。写在最后:没有绝对好的技术,只有对业务最友好的技术,谨此献给所有developer。
转自https://segmentfault.com/a/1190000012244418#articleHeader0