Solr(全文搜索功能)
Solr是什么?
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr是一个全文检索服务器,只需要进行配置就可以实现全文检索服务。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
关于Solr与Lucene区别可以参考:http://www.lucenetutorial.com/lucene-vs-solr.html
Solr的安装
需要把solr服务器安装到linux环境
第一步:Linux环境下安装JDK及Tomcat
第二步:下载Solr压缩包并上传到Linux上(我这里用的是solr-4.9.1.tgz),并解压,改名为solr(tar -zxvf solr-4.9.1.tgz )(mv solr-4.9.1 solr)
下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/4.9.1下载地址实在不好找最后找到如下的http://archive.apache.org/dist/lucene/solr/
第三步:将/usr/local/jae/solr/dis目录下的solr-4.9.1.war包部署到tomcat下,并改名为solr.war(cp solr-4.9.1.war /usr/local/jae/tomcat/webapps/solr.war)
第四步:启动tomcat,使war包自动解压,然后关闭tomcat,删除solr.war
1. cd /usr/local/jae/tomcat/bin
2. ./startup.sh
3. IP地址:8080测试tomcat是否启动成功
4. ./shutdown.sh
5. cd ../webapps
6. rm -f solr.war第五步:把/usr/local/jae/solr/example/lib/ext目录下所有的jar包复制到solr工程中
1. cd /usr/local/jae/solr/example/lib/ext
2. cp * /usr/local/jae/tomcat/webapps/solr/WEB-INF/lib/第六步:创建一个solrhome(存放solr服务器所有配置文件的目录)
1. cd /usr/local/jae/solr/example(这里的solr目录就是一个标准的solrhome目录)
2. cp -r solr /usr/local/jae/solrhome第七步:告诉solr服务器solrhome的位置,需要修改solr工程的web.xml文件。
vim /usr/local/jae/tomcat/webapps/solr/WEB-INF/web.xml
配置JNDI,去掉env-entry处的注释并将env-entry-value改为你solrhome目录的位置
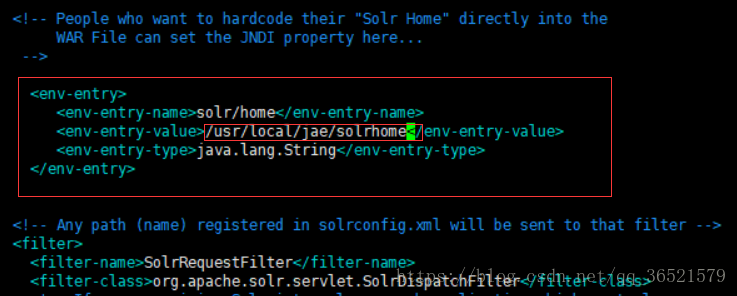
第八步:启动tomcat,浏览器访问IP地址:8080/solr 看到solr界面
使用solr
配置业务字段
- 在solr中默认没有中文分析器,需要手工配置。配置一个FieldType,在FieldType中指定中文分析器。
- Solr中的字段必须是先定义后使用。
(1)中文分析器的配置
- 使用IK-Analyzer。把分析器的文件夹上传到服务器
- 将IK Analyzer 2012FF_hf1.zip文件上传到Linux服务器的/usr/local/jae,然后执行unzip IK Analyzer 2012FF_hf1.zip命令解压zip包到当前目录,将 IK Analyzer 2012FF_hf1重命名为IK( mv IK\ Analyzer\ 2012FF_hf1/ IK)
- cd IK
- 需要把分析器的jar包添加到solr工程中
cp IKAnalyzer2012FF_u1.jar /usr/local/jae/tomcat/webapps/solr/WEB-INF/lib/ - 需要把IKAnalyzer需要的扩展词典及停用词词典、配置文件复制到solr工程的classpath。
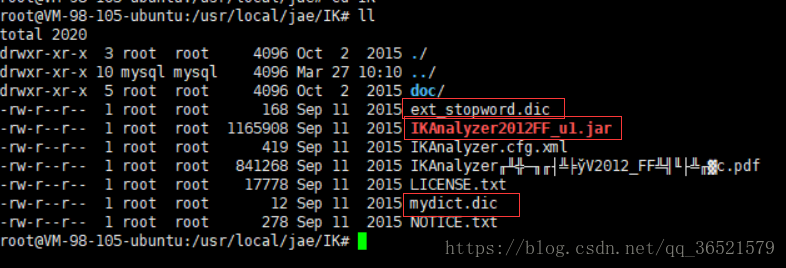
1. cd /usr/local/jae/tomcat/webapps/solr/WEB-INF/
2.mkdir classes
3. cd /usr/local/jae/IK
4.cp ext_stopword.dic IKAnalyzer.cfg.xml mydict.dic /usr/local/jae/tomcat/webapps/solr/WEB-INF/classes注意:扩展词典及停用词词典的字符集必须是utf-8。不能使用windows记事本编辑。
- 配置fieldType。需要在solrhome/collection1/conf/schema.xml中配置。
(vim /usr/local/jae/solrhome/collection1/conf/schema.xml)
在最后面加上
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>技巧:使用vi、vim跳转到文档开头gg。跳转到文档末尾:G
(2)业务字段配置
我们的商品表
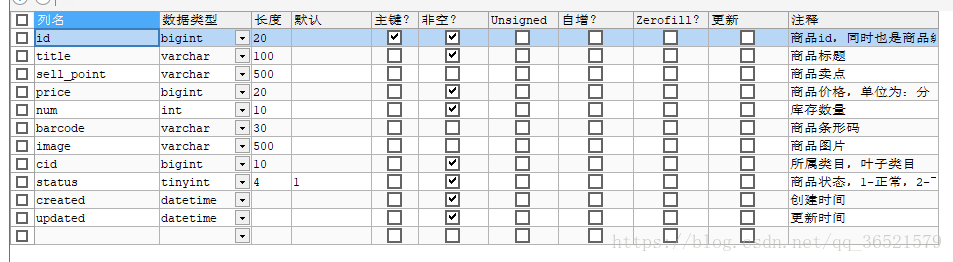
参考京东的搜索功能,业务字段判断的标准大概有两
1. 在搜索时是否需要在此字段上进行搜索。例如:商品名称,商品卖点,商品描述
2. 后续的业务是否需要用到此字段。例如:商品id
最后得出需要用到的字段:
商品id,商品名称,商品卖点,商品描述,商品价格和商品图片(用于搜索后展示),商品分类名称(搜索时可能根据类别来搜索)
solr中的业务字段:
1. id->商品id
其他的对应字段创建solr的字段。
继续在(vim /usr/local/jae/solrhome/collection1/conf/schema.xml)最后面添加代码
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="long" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" />
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>stored=”true”就存储,存储则用于展示,若不展示则不存储,节约存储空间
item_keywords是复制域,为solr提供的搜索优化(在多个域上搜索速度不如在一个域域上快,复制域将多个域合为一个域)
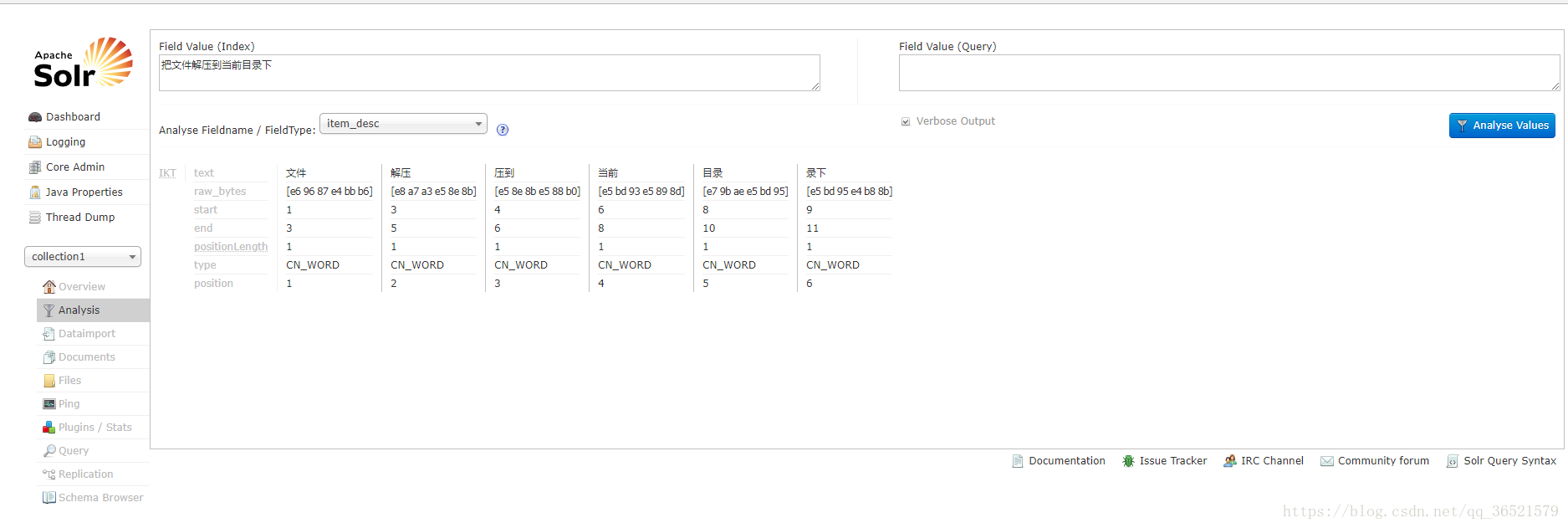
分析成功