postgres连接用户的cache内核
前言
pg客户端通过libpq连接到服务器后,postmaster进程会为此客户端创建一个postgres进程,来处理此客户端发送来的各种请求。客户端发来的任何请求,都需要postgres进程通过多次扫描系统表来获取此次请求所需的数据。为了加快处理请求的效率,在每个postgres进程初始化的时候,会创建一系列的cache来缓存catalog数据。下面就分析一下pg内部cache的内核实现(代码版本为10.4)。
第一节 cache种类
cache的相关代码在src/backend/utils/cache目录下
attribute cache代码:attoptcache.c
系统表cache代码:catcache.c
事件触发器cache代码:evtcache.c
消息机制代码:inval.c
计划cache代码:plancache.c
普通表描述符cache代码:relcache.c
系统表oid映射cache代码:relmapper.c
普通表oid映射cache代码:relfilenodemap.c
表空间cache代码:spccache.c
系统表cache代码:syscache.c
系统表检索函数:lsyscache.c
typecache代码:typcache.c
文本检索cache代码:ts_cache.c
此文主要对catcache和relcache进行说明。
第二节 catcache数据结构
1.syscache标识枚举
在syscache.h头文件中定义了枚举类型SysCacheIdentifier,在这里枚举了syscache的所有的元素.
每一个元素都称为一个catcache,下面会讲到。
enum SysCacheIdentifier
{
AGGFNOID = 0,
...
USERMAPPINGUSERSERVER
# define SysCacheSize (USERMAPPINGUSERSERVER + 1)
};2.cache描述符结构体
struct cachedesc
{
Oid reloid;
Oid indoid;
int nkeys;
int key[4];
int nbuckets;
};在1中每一个枚举值对应一个上述结构体
3.cacheinfo数组
static const struct cachedesc cacheinfo[] = {
{AggregateRelationId,
AggregateFnoidIndexId,
{
Anum_pg_aggregate_aggfnoid,
0,
0
},
16
},
…
{UserMappingRelationId, /* USERMAPPINGUSERSERVER */
UserMappingUserServerIndexId,
2,
{
Anum_pg_user_mapping_umuser,
Anum_pg_user_mapping_umserver,
0,
0
},
2
}
};1中每一个枚举在cacheinfo中都有一个自己的空间,枚举值就是数组下标
此数组对每一个syscache进行初步描述,有用户连接时就会通过这些描述初始化cache。
4.catcache结构体
typedef struct catcache
{
int id;
slist_node cc_next;
const char *cc_relname;
Oid cc_reloid;
Oid cc_indexoid;
bool cc_relisshared;
TupleDesc cc_tupdesc;
int cc_ntup;
int cc_nbuckets;
int cc_nkeys;
int cc_key[CATCACHE_MAXKEYS];
PGFunction cc_hashfunc[CATCACHE_MAXKEYS];
ScanKeyData cc_skey[CATCACHE_MAXKEYS];
bool cc_isname[CATCACHE_MAXKEYS];
dlist_head cc_lists;
dlist_head *cc_bucket;
# ifdef CATCACHE_STATS
long cc_searches;
long cc_hits;
long cc_neg_hits;
long cc_newloads;
long cc_invals;
long cc_lsearches;
long cc_lhits;
# endif
} CatCache;5. CatCTup结构体
typedef struct catctup
{
int ct_magic;
# define CT_MAGIC 0x57261502
CatCache *my_cache;
dlist_node cache_elem;
struct catclist *c_list;
int refcount;
bool dead;
bool negative;
uint32 hash_value;
HeapTupleData tuple;
} CatCTup;6.CatCList结构体
typedef struct catclist
{
int cl_magic;
# define CL_MAGIC 0x52765103
CatCache *my_cache;
dlist_node cache_elem;
int refcount;
bool dead;
bool ordered;
short nkeys;
uint32 hash_value;
HeapTupleData tuple;
int n_members;
CatCTup *members[FLEXIBLE_ARRAY_MEMBER];
} CatCList;7.CatCacheHeader结构体
typedef struct catcacheheader
{
slist_head ch_caches;
int ch_ntup;
} CatCacheHeader;8.catcache相关结构关系图(下称图1)
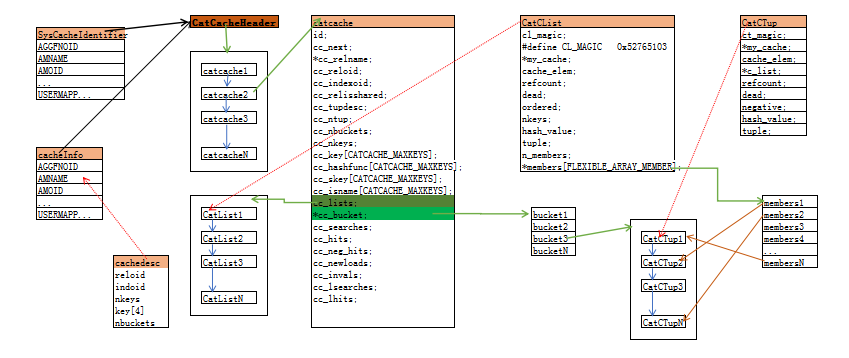
SysCacheIdentifier枚举了所有的catcache的类型,而cacheinfo则是穷举了每一个cache的结构。 CatCacheHeader是catcache链表的头,将每一个catcache初始化后,就将这个cacatche的结构链接到此链表。catcache结构体中描述了每一个cacatche的信息。缓存的系统表tuple数据就存储在cc_bucket中,在catche初始化时将cc_bucket初始化为一个hash桶数组。在每一个hash桶中存储着一个CatTup链表,每一个CatTup结构就对应着一个系统表的tuple。
在catcache结构中还有一个cc_lists链表,此链表是为了缓存一个多结果的系统表扫描。
比如使用表名作为条件扫描pg_class,可能返回多条记录。返回的记录还是存储在cc_bucket哈希桶
数组中,同时将在哈希桶中的位置存储在CatCList结构的members数组中。
第三节 relcache cache结构
此cache主要对数据库中的各种表的表结构进行缓存。
使用static HTAB *RelationIdCache;结构存储所有的relcache cache。
使用RelationData存储每一个relcache。
第四节 relcache初始化

RelationCacheInitialize()函数,创建RelationIdCache结构
RelationCacheInitializePhase2()函数,如果从globle/pg_internal.init文件加载cluster共享表relcache数据失败,则通过函数formrdesc加载必要relcache。
RelationCacheInitializePhase3()函数,如果从dbdir/pg_internal.init文件加载非共享表(包括索引、视图、序列等)relcache数据失败,则通过函数formrdesc加载必要relcache;调用InitCatalogCachePhase2()来循环一遍catcache,将所有的系统表的relcache添加到RelationIdCache中去。
第五节 relcache的行为
经过relcache的初始化后,所有系统表的relation结构都已经加载到relcache中去了。
普通表的relation表结构会在第一次打开这个表的时候,将普通表的relation结构加载到relcache中(举例:如下函数调用过程)。
relation_open()->RelationIdGetRelation()->RelationBuildDesc()->RelationCacheInsert()
已经加载到relcache中的数据一般会伴随着这个用户连接直到用户连接关闭。但是当一个表的结构发生了变化,需要同步这个变化到所有的保持连接的用户连接。如下是这个同步的实现过程描述:
假设当前有c1,c2这两个用户一直保持连接,c1对表t1做了表结构的修改,那么c1的postgres进程会通过RegisterRelcacheInvalidation(Oid dbId, Oid relId)函数注册t1表的relcache失效的消息message1。c2连接在c1改动后的第一个用户查询执行之前会先处理message1(参考函数LocalExecuteInvalidationMessage),最终使用RelationClearRelation函数完成c2的postgres进程的t1的relcache的更新。
第六节 catcache初始化
PostgresMain->InitPostgres->InitCatalogCache->InitCatCache
->RelationCacheInitializePhase3->InitCatalogCachePhase2在InitCatalogCache函数中循环调用InitCatCache(cacheinfo中的项作为初始化的参数)来初始化每一个catcache.
在InitCatCache中为每一个catcache申请CatCache结构体空间,并通过参数为结构体空间赋值。
每种catcache的hash桶的个数是一定的,此时会为hash桶(cc_bucket)申请空间。而cc_lists则会保持空值。
第七节 catcache的行为(保存和读取缓存数据)
经过catcache的初始化后,已经为所有的catcache初始化了用来缓存扫描数据的hash桶。下面就说明hash桶如何存取数据的。
1.对于返回结果单一的系统表的扫描任务最终落到SearchCatCache()函数身上:
首先,通过如下代码获取此检索条件的缓存结果所在的hash桶。
hashValue = CatalogCacheComputeHashValue(cache, cache->cc_nkeys, cur_skey);
hashIndex = HASH_INDEX(hashValue, cache->cc_nbuckets);
bucket = &cache->cc_bucket[hashIndex];依次检索此hash桶中的元组,是否满足条件如果满足则返回,如果没有满足条件则继续执行。
dlist_foreach(iter, bucket)
{
bool res;
ct = dlist_container(CatCTup, cache_elem, iter.cur);
if (ct->dead)
continue; /* ignore dead entries */
if (ct->hash_value != hashValue)
continue; /* quickly skip entry if wrong hash val */
/*
* see if the cached tuple matches our key.
*/
HeapKeyTest(&ct->tuple,
cache->cc_tupdesc,
cache->cc_nkeys,
cur_skey,
res);
if (!res)
continue;
dlist_move_head(bucket, &ct->cache_elem);
if (!ct->negative)
{
//在hash同种检索到了结果,将此元组返回
ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner);
ct->refcount++;
ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple);
CACHE3_elog(DEBUG2, "SearchCatCache(%s): found in bucket %d",
cache->cc_relname, hashIndex);
#ifdef CATCACHE_STATS
cache->cc_hits++;
#endif
return &ct->tuple;
}
else
{
//此时检索到的是一个negative entry,意味着此检索条件没有任何结果
CACHE3_elog(DEBUG2, "SearchCatCache(%s): found neg entry in bucket %d",
cache->cc_relname, hashIndex);
#ifdef CATCACHE_STATS
cache->cc_neg_hits++;
#endif
return NULL;
}
}在catcache中没有找到适合的结果,那么就去扫描表数据
relation = heap_open(cache->cc_reloid, AccessShareLock);
scandesc = systable_beginscan(relation,
cache->cc_indexoid,
IndexScanOK(cache, cur_skey),
NULL,
cache->cc_nkeys,
cur_skey);
ct = NULL;
while (HeapTupleIsValid(ntp = systable_getnext(scandesc)))
{
//通过此处将扫描到的元组,插入到cache->cc_bucket[hashIndex]哈希桶中
ct = CatalogCacheCreateEntry(cache, ntp,
hashValue, hashIndex,
false);
/* immediately set the refcount to 1 */
ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner);
ct->refcount++;
ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple);
break; /* assume only one match */
}
systable_endscan(scandesc);
heap_close(relation, AccessShareLock);
//如果没有扫描到任何结果,为此检索条件创建一个negative entry
if (ct == NULL)
{
if (IsBootstrapProcessingMode())
return NULL;
ntp = build_dummy_tuple(cache, cache->cc_nkeys, cur_skey);
ct = CatalogCacheCreateEntry(cache, ntp,
hashValue, hashIndex,
true);
heap_freetuple(ntp);
CACHE4_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples",
cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup);
CACHE3_elog(DEBUG2, "SearchCatCache(%s): put neg entry in bucket %d",
cache->cc_relname, hashIndex);
/*
* We are not returning the negative entry to the caller, so leave its
* refcount zero.
*/
return NULL;
}
CACHE4_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples",
cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup);
CACHE3_elog(DEBUG2, "SearchCatCache(%s): put in bucket %d",
cache->cc_relname, hashIndex);
#ifdef CATCACHE_STATS
cache->cc_newloads++;
#endif
return &ct->tuple;2.对于返回结果为多个的的系统表的扫描任务最终落到SearchCatCacheList()函数身上:
SearchCatCache函数是将检索到的元组直接放到hash桶中。
SearchCatCacheList函数也是将检索到的多个元组放到hash桶中,但是每个检索的组织形式是CatCList结构,他将他所需要的元组的hash桶地址放到CatCList.members[]数组成员中.
实现思路一致,这里不再赘述。
与relcache同样,当在一个用户连接发生了某个系统表的属性值的变化的时候,这个用户连接会通过RegisterCatalogInvalidation()函数注册一个消息,其他保持连接的用户连接在下一次执行查询时会先处理此消息,清楚自己进程对这个catcache的缓存。
结语
本文讲述了relcache和catcache的初始化和存取数据的过程。在这个过程中还有很多没有探究清楚的地方留待研究:
①其他cache的作用过程
②postgres进程间传递invalid消息的机制