▶ 书上第四章,用一系列步骤优化曼德勃罗集的计算过程。
● 代码
1 // constants.h 2 const unsigned int WIDTH=16384; 3 const unsigned int HEIGHT=16384; 4 const unsigned int MAX_ITERS=50; 5 const unsigned int MAX_COLOR=255; 6 const double xmin=-1.7; 7 const double xmax=.5; 8 const double ymin=-1.2; 9 const double ymax=1.2; 10 const double dx = (xmax - xmin) / WIDTH; 11 const double dy = (ymax - ymin) / HEIGHT;
1 // mandelbrot.h 2 #pragma acc routine seq 3 unsigned char mandelbrot(int Px, int Py);
1 // mandelbrot.cpp 2 #include <cstdio> 3 #include <cstdlib> 4 #include <fstream> 5 #include "mandelbrot.h" 6 #include "constants.h" 7 8 using namespace std; 9 10 unsigned char mandelbrot(int Px, int Py) 11 { 12 const double x0 = xmin + Px * dx, y0 = ymin + Py * dy; 13 double x = 0.0, y = 0.0; 14 int i; 15 for(i=0; x * x + y * y < 4.0 && i < MAX_ITERS; i++) 16 { 17 double xtemp = x * x - y * y + x0; 18 y = 2 * x * y + y0; 19 x = xtemp; 20 } 21 return (double)MAX_COLOR * i / MAX_ITERS; 22 }
1 // main.cpp 2 #include <cstdio> 3 #include <cstdlib> 4 #include <fstream> 5 #include <cstring> 6 #include <omp.h> 7 #include <openacc.h> 8 9 #include "mandelbrot.h" 10 #include "constants.h" 11 12 using namespace std; 13 14 int main() 15 { 16 unsigned char *image = (unsigned char*)malloc(sizeof(unsigned int) * WIDTH * HEIGHT); 17 FILE *fp=fopen("image.pgm","wb"); 18 fprintf(fp,"P5\n\"#comment\"\n%d %d\n%d\n",WIDTH, HEIGHT, MAX_COLOR); 19 20 acc_init(acc_device_nvidia); 21 #pragma acc parallel num_gangs(1) 22 { 23 image[0] = 0; 24 } 25 double st = omp_get_wtime(); 26 #pragma acc parallel loop 27 for(int y = 0; y < HEIGHT; y++) 28 { 29 for(int x = 0; x < WIDTH; x++) 30 image[y * WIDTH + x] = mandelbrot(x, y); 31 } 32 double et = omp_get_wtime(); 33 printf("Time: %lf seconds.\n", (et-st)); 34 fwrite(image,sizeof(unsigned char),WIDTH * HEIGHT, fp); 35 fclose(fp); 36 free(image); 37 return 0; 38 }
● 输出结果
// Ubuntu: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp$ pgc++ -std=c++11 -acc -mp -fast -Minfo -c mandelbrot.cpp mandelbrot(int, int): 9, Generating acc routine seq Generating Tesla code 10, FMA (fused multiply-add) instruction(s) generated 15, Loop not vectorized/parallelized: potential early exits 16, FMA (fused multiply-add) instruction(s) generated cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp$ pgc++ -std=c++11 -acc -mp -fast -Minfo main.cpp mandelbrot.o -o acc1.exe main.cpp: main: 24, Accelerator kernel generated Generating Tesla code Generating implicit copyout(image[0]) 27, Accelerator kernel generated Generating Tesla code 30, #pragma acc loop gang /* blockIdx.x */ 31, #pragma acc loop vector(128) /* threadIdx.x */ 27, Generating implicit copy(image[:268435456]) 31, Loop is parallelizable Loop not vectorized/parallelized: contains call cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp$ ./acc1.exe Time: 0.646578 seconds.
● 优化 03,变化仅在 main.cpp 中
1 // main.cpp 2 #include <cstdio> 3 #include <cstdlib> 4 #include <fstream> 5 #include <cstring> 6 #include <omp.h> 7 #include <openacc.h> 8 #include "mandelbrot.h" 9 #include "constants.h" 10 11 using namespace std; 12 13 int main() 14 { 15 const int num_blocks = 16, block_size = HEIGHT / num_blocks * WIDTH; 16 unsigned char *image=(unsigned char*)malloc(sizeof(unsigned int) * WIDTH * HEIGHT); 17 FILE *fp=fopen("image.pgm","wb"); 18 fprintf(fp,"P5\n\"#comment\"\n%d %d\n%d\n",WIDTH, HEIGHT, MAX_COLOR); 19 20 acc_init(acc_device_nvidia); 21 #pragma acc parallel num_gangs(1) 22 { 23 image[0] = 0; 24 } 25 double st = omp_get_wtime(); 26 #pragma acc data create(image[WIDTH*HEIGHT]) 27 { 28 for(int block = 0; block < num_blocks; block++) 29 { 30 const int start = block * (HEIGHT/num_blocks), end = start + (HEIGHT/num_blocks); 31 #pragma acc parallel loop async(block) 32 for(int y=start;y<end;y++) 33 { 34 for(int x=0;x<WIDTH;x++) 35 image[y*WIDTH+x]=mandelbrot(x,y); 36 } 37 #pragma acc update self(image[block*block_size:block_size]) async(block) 38 } 39 } 40 #pragma acc wait 41 42 double et = omp_get_wtime(); 43 printf("Time: %lf seconds.\n", (et-st)); 44 fwrite(image,sizeof(unsigned char), WIDTH * HEIGHT, fp); 45 fclose(fp); 46 free(image); 47 return 0; 48 }
● 输出结果
// Ubuntu: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task3$ pgc++ -std=c++11 -acc -mp -fast -Minfo -c mandelbrot.cpp mandelbrot(int, int): 11, Generating acc routine seq Generating Tesla code 12, FMA (fused multiply-add) instruction(s) generated 15, Loop not vectorized/parallelized: potential early exits 17, FMA (fused multiply-add) instruction(s) generated cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task3$ pgc++ -std=c++11 -acc -mp -fast -Minfo main.cpp mandelbrot.o -o acc2.exe main.cpp: main: 22, Accelerator kernel generated Generating Tesla code Generating implicit copyout(image[0]) 27, Generating create(image[:268435456]) 30, Accelerator kernel generated Generating Tesla code 32, #pragma acc loop gang /* blockIdx.x */ 34, #pragma acc loop vector(128) /* threadIdx.x */ 34, Loop is parallelizable Loop not vectorized/parallelized: contains call 38, Generating update self(image[block*16777216:16777216]) cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task3$ ./acc2.exe Time: 0.577263 seconds.
● 优化 05,添加异步计算
1 // main.cpp 2 #include <cstdio> 3 #include <cstdlib> 4 #include <fstream> 5 #include <cstring> 6 #include <omp.h> 7 #include <openacc.h> 8 #include "mandelbrot.h" 9 #include "constants.h" 10 11 using namespace std; 12 13 int main() 14 { 15 const int num_blocks=64, block_size = HEIGHT / num_blocks * WIDTH; 16 unsigned char *image=(unsigned char*)malloc(sizeof(unsigned int) * WIDTH * HEIGHT); 17 FILE *fp = fopen("image.pgm", "wb"); 18 fprintf(fp,"P5\n\"#comment\"\n%d %d\n%d\n",WIDTH, HEIGHT, MAX_COLOR); 19 20 const int num_gpus = acc_get_num_devices(acc_device_nvidia); 21 22 #pragma omp parallel num_threads(num_gpus) 23 { 24 acc_init(acc_device_nvidia); 25 acc_set_device_num(omp_get_thread_num(),acc_device_nvidia); 26 } 27 printf("Found %d NVIDIA GPUs.\n", num_gpus); 28 29 double st = omp_get_wtime(); 30 #pragma omp parallel num_threads(num_gpus) 31 { 32 int queue = 1; 33 int my_gpu = omp_get_thread_num(); 34 acc_set_device_num(my_gpu,acc_device_nvidia); 35 printf("Thread %d is using GPU %d\n", my_gpu, acc_get_device_num(acc_device_nvidia)); 36 #pragma acc data create(image[WIDTH*HEIGHT]) 37 { 38 #pragma omp for schedule(static, 1) 39 for(int block = 0; block < num_blocks; block++) 40 { 41 const int start = block * (HEIGHT/num_blocks), end = start + (HEIGHT/num_blocks); 42 #pragma acc parallel loop async(queue) 43 for(int y=start;y<end;y++) 44 { 45 for(int x=0;x<WIDTH;x++) 46 image[y*WIDTH+x]=mandelbrot(x,y); 47 } 48 49 #pragma acc update self(image[block*block_size:block_size]) async(queue) 50 queue = (queue + 1) % 2; 51 } 52 } 53 #pragma acc wait 54 } 55 56 double et = omp_get_wtime(); 57 printf("Time: %lf seconds.\n", (et-st)); 58 fwrite(image,sizeof(unsigned char), WIDTH * HEIGHT, fp); 59 fclose(fp); 60 free(image); 61 return 0; 62 }
● 输出结果
// Ubuntu: cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task5.multithread$ pgc++ -std=c++11 -acc -mp -fast -Minfo -c mandelbrot.cpp mandelbrot(int, int): 11, Generating acc routine seq Generating Tesla code 12, FMA (fused multiply-add) instruction(s) generated 15, Loop not vectorized/parallelized: potential early exits 17, FMA (fused multiply-add) instruction(s) generated cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task5.multithread$ pgc++ -std=c++11 -acc -mp -fast -Minfo main.cpp mandelbrot.o -o acc3.exe main.cpp: main: 23, Parallel region activated 26, Parallel region terminated 31, Parallel region activated 37, Generating create(image[:268435456]) 39, Parallel loop activated with static cyclic schedule 41, Accelerator kernel generated Generating Tesla code 43, #pragma acc loop gang /* blockIdx.x */ 45, #pragma acc loop vector(128) /* threadIdx.x */ 45, Loop is parallelizable Loop not vectorized/parallelized: contains call 50, Generating update self(image[block*4194304:4194304]) 51, Barrier 54, Parallel region terminated cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task5.multithread$ ./acc3.exe Found 1 NVIDIA GPUs. Thread 0 is using GPU 0 Time: 0.497450 seconds.
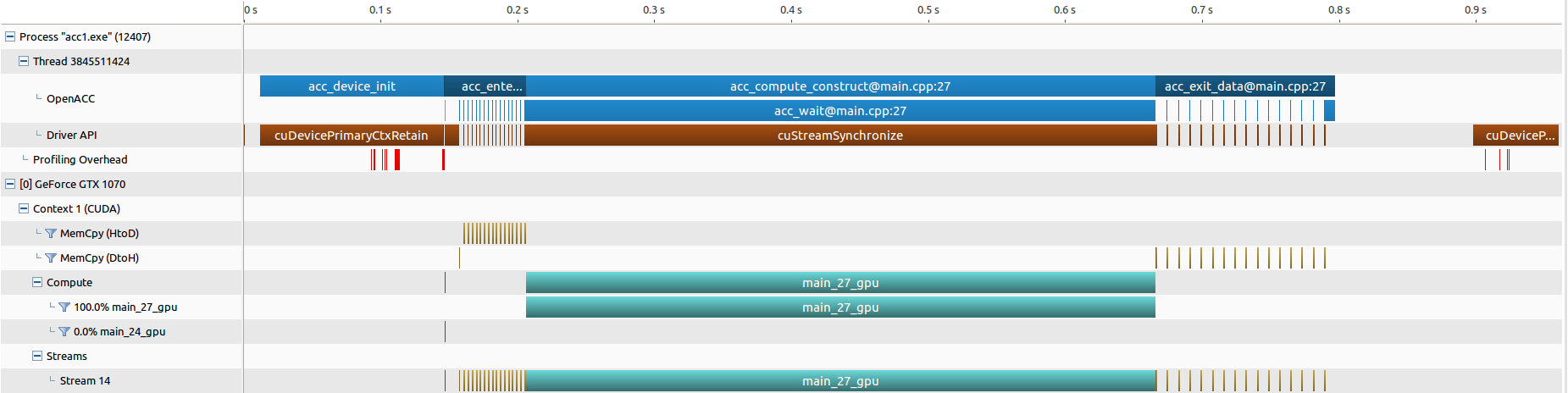
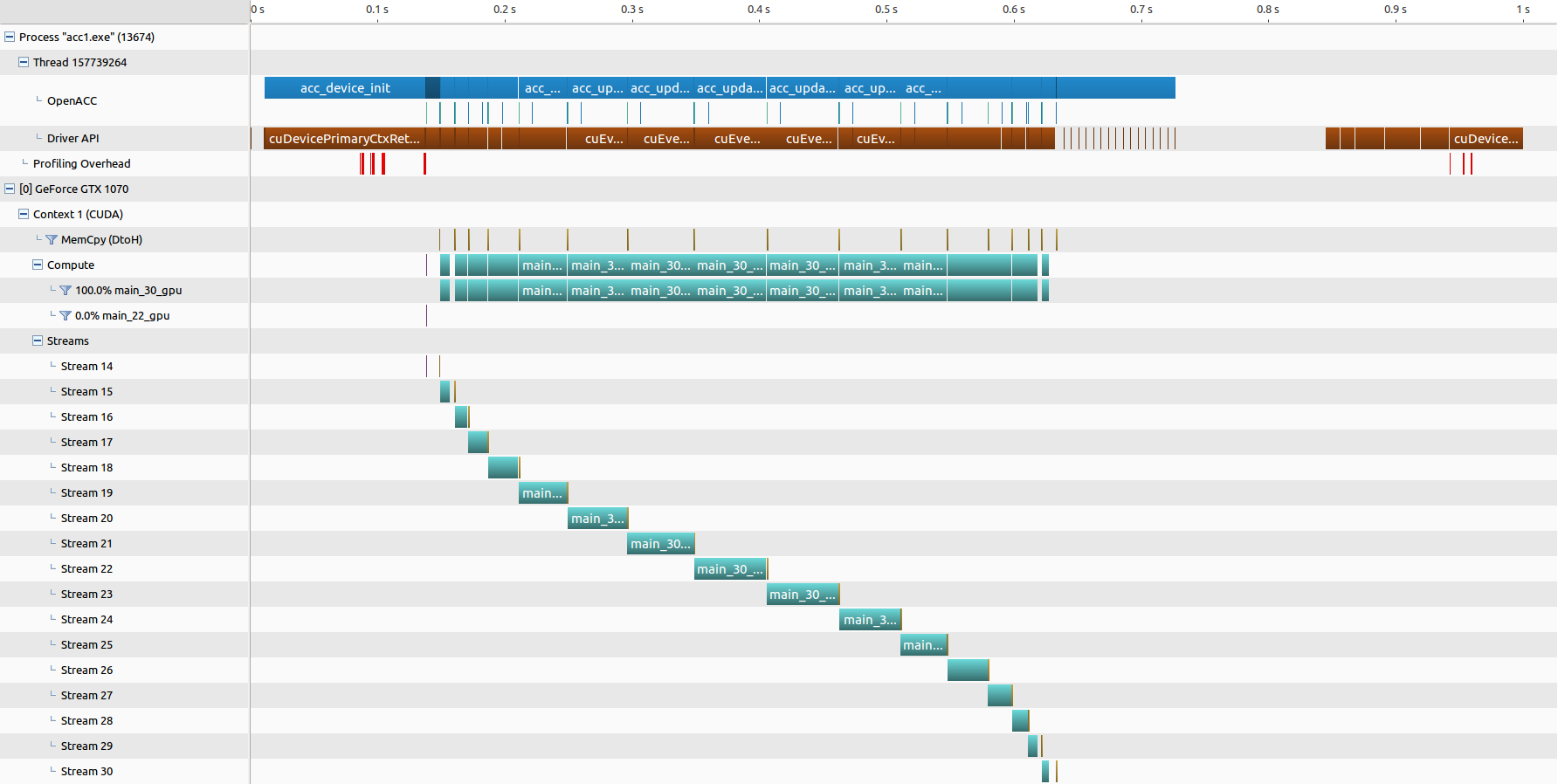
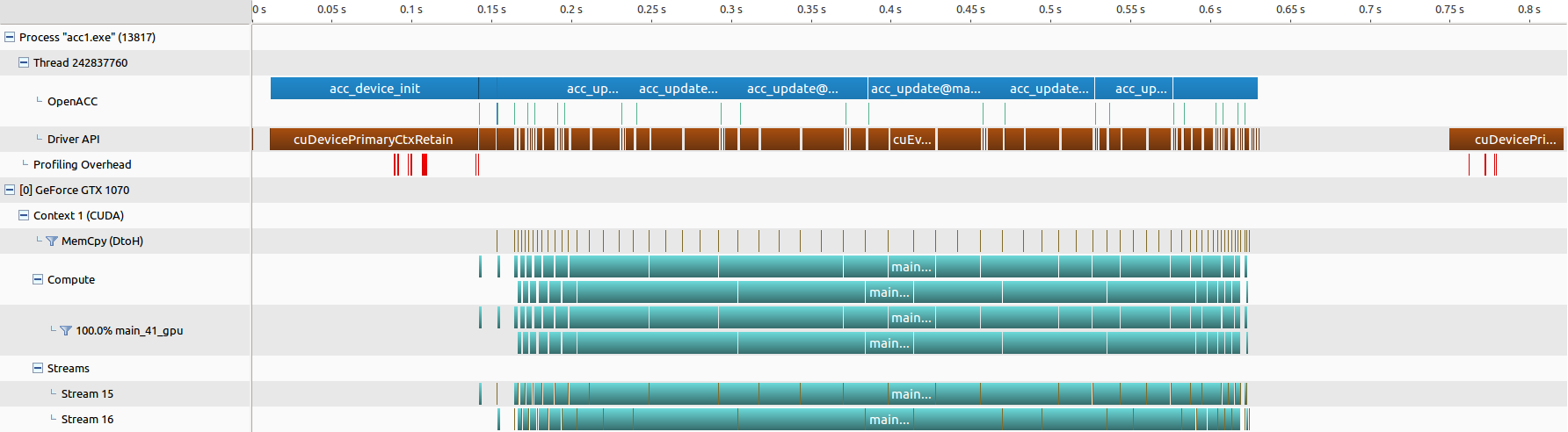
● nvprof 的结果汇总,三张图分别为 “并行和数据优化”,“优化 03(分块分流)” 和 “优化 05(分块调度)”