一、Series类型
1.数据创建
Series 是一个带有 名称 、索引的一维数组,在 Series 中包含的数据类型可以是整数、浮点、字符串、Python对象等
Pandas 常用的数据结构有两种:Series 和 DataFrame。这些数据结构构建在 Numpy 数组之上,效率很高。
age = pd.Series(data=[23,34,35,12,23]) #创建series数组
age.index = ['love','alice','peter','mars','mechel'] #建立索引
age.index.name = 'age_series' #建立索引名
age.name = 'age_info' #建立series名字
print(age)上述五步等价于
#上述五步等价于以下两步
index = pd.Index(['love','alice','peter','mars','mechel'], name='age_series')
age = pd.Series(data=[23,34,35,12,23], index=index, name='age_info')
print(age)
#设置类型
age = pd.Series(data=[23,34,35,12,23], index=index, name='age_info',dtype=float) #设置数据类型结果

2.取数
(1)索引取数:age['love']
(2)切片:age[0] 取第一个,age[:3] 取前三个
3.操作
Series 与 ndarray 一样,也是支持向量化操作的。同时也可以传递给大多数期望 ndarray 的 NumPy 方法
age = age +1 #每个元素加一
print(age)
print(np.exp(age))
二、DataFrame类型
DataFrame 是一个带有索引的二维数据结构,每列可以有自己的名字及不同的数据类型。类似 excel 表格或者数据库中的一张表,DataFrame 是最常用的 Pandas 对象。
1.pandas构造
#pandas 构建方法
#方法一:字典方式
index = pd.Index(['love','alice','peter','mars','mechel'],name='name')
data = {'age':[23,34,35,12,23],
'city':['beijign','shanghai','hangzhou','tianjin','yunnan']}
df_age = pd.DataFrame(data=data, index=index)
print(df_age)
#方法二:二维数组
data = [[23,'beijing'],
[34,'shanghai'],
[35,'hanghzou'],
[12,'tianjin'],
[23,'yunnan']]
columns = ['age','city']
df_age = pd.DataFrame(data=data, index=index, columns=columns)
print(df_age)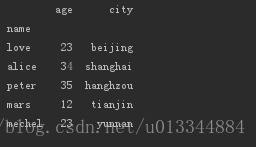
2.访问行
#访问操作
#访问行 --通过索引名 .loc
print(df_age.loc['mars']) #一行
print(df_age.loc[['mars','love']]) #多行
#通过索引位置 .iloc
print(df_age.iloc[0]) #一行
print(df_age.iloc[1:3]) #多行
3.访问列(切片访问方式将在数据筛选中讲述)
#访问列
print(df_age.age)
print(df_age['age']) #访问一列的两种方式
print(df_age[['age','city']]) #访问多列4.删除、新增一列
删除:del,pop,drop 新增:赋同一个值,不同值,
#新增一列
df_age['sex'] = 'female' #新增一列赋予相同值
df_age['age_2'] = df_age.age + 1 #新增一列,赋予不同值,从已有的列演算
df_age_2 = df_age.assign(age_3 = df_age['age'] + 2) #不改变原来数据
print(df_age)
print(df_age_2)
#删除一列
del df_age_2['age_2'] #原始数据集改变
df_age_2.pop('age_3') #原始数据集改变
print(df_age_2)
df_age_2.drop(labels=['sex'],axis=1,inplace=True) #inplace=True时改变原始数据集,否则不改变
print(df_age_2)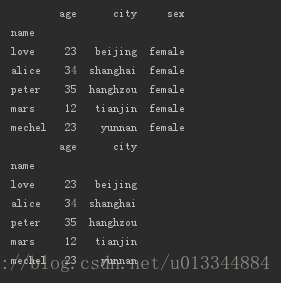
5.修改列、索引名称
在使用 DataFrame 的过程中,经常会遇到修改列名,索引名等情况。rename 可以实现,通过rename的columns/index参数可以改变列名索引名
#修改列名。索引名
print(df_age.rename(columns={'age':'Age','city':'City','gender':'Gender','age_2':'Age_2'},
index={'alice':'Alice','love':'Lilly'}))
6.类型操作
1.get_dtype_counts 方法,获取每种类型的列数。
print(df_age.get_dtype_counts())#每种类型的个数统计

2. astype 转换数据类型
print(df_age.age.astype(float)) #转为浮点型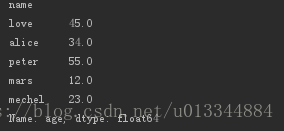
3.object 类型转为其他类型,常见的有转为数字、日期、时间差,Pandas 中分别对应 to_numeric、to_datetime、to_timedelta
当类型转时,默认情况下,errors='raise',这意味着强转失败后直接抛出异常,设置errors='coerce' 可以在强转失败时将有问题的元素赋值为 pd.NaT(对于datetime和timedelta)或 np.nan(数字)。设置 errors='ignore' 可以在强转失败时返回原有的数据。
df_age['height']=['156','178','180','190','166cm']
print(pd.to_numeric(df_age.height,errors='coerce')) #返回该列转换后的结果,df_age中对应数据未发生改变
