哈希表 是一种以关联方式存储数据的数据结构,在哈希表中,数据以数组格式存储,其中每个数据值都有自己唯一的索引。如果我们知道所需数据的索引,那么数据的访问就会变得非常快。 所以关键是 找到索引, 而检索 数值关键字 到 索引 的方式就是 哈希(Hashing)。
因此,在这个结构中插入和搜索操作非常快,不管数据的大小。哈希表使用数组作为存储介质,并使用散列技术(就是我们的哈希算法)生成一个索引。
哈希(Hashing)
哈希是一种将一系列键值转换成数组的一系列索引的技术。我们以取模运算(基数是20)来演示哈希算法。
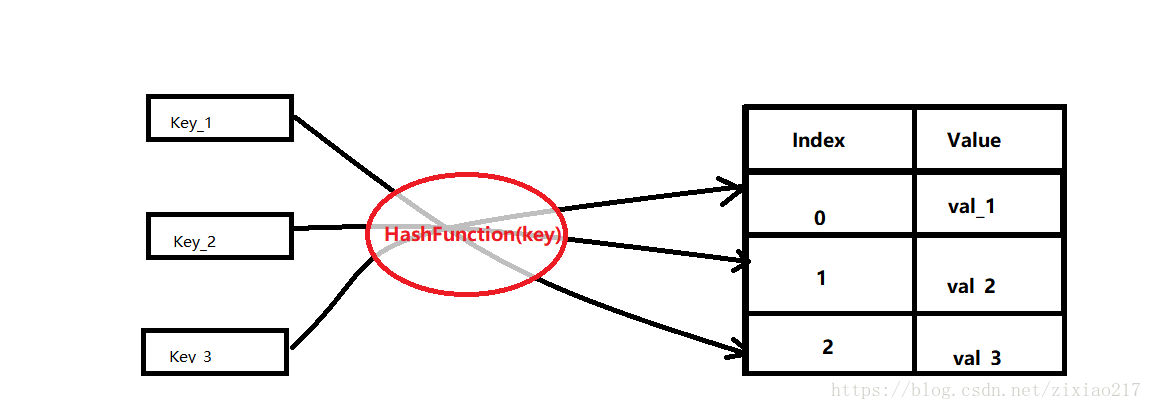
图解: 通过hash算法将左边的key映射到右边的存储数组中的索引值。
假定有以下值键组:注意:第二个值表示key,一般我们(是key,value)才是规范的写法。
(100, 1)
(100, 2)
(100, 42)
key分别为: 1, 2, 42; 使用哈希算法(取模,基数为20)后, 各自映射的索引值应该是: 1, 2, 2。如图:

哈希碰撞
哈希碰撞:就是不同key的哈希值是一样的。我们的实例:1,2,42 进行 20 取模后,就发生了哈希碰撞,其中2 和 42 哈希后的索引值是一样的。
线性推测(Linear Probing)
发生哈希碰撞后,我们可以使用简单的线性推测,依次往下寻找直到找到一个空的位置。像42,先哈希再进行线性推测后,索引值为3。因为索引2后面的索引位置3是空的坑位。

数据项
class DataItem{
int data;
int key; //key关键字,对其使用哈希算法
}插入数据到hash存储结构中
/**
* 插入新值到hash表
* <pre>
* hash后,发现坑位没有被占,则占有该坑位;
* hash后,发现该坑位被占了:
* Step1: key和新插入的key不登,则使用线性推测方式,按队列顺序往后打探下一个坑位的情况(这是一个循环表顺序)
* Step2: 循环打探坑位:发现新坑位则占住
* </pre>
* @param item
*/
static void insert(DataItem item) {
boolean standFlag = false;
//获取hash索引
int idx = hashCode(item.key);
if( null != hashArray[idx] ) {
if( hashArray[idx].key != item.key ) {
//【被占】---》 则使用线性推测方式处理,找到空位进入
while( null != hashArray[idx] && hashArray[idx].key != item.key ) {
idx = hashCode( ++idx );
if( null == hashArray[idx] ) {
hashArray[idx] = item;
standFlag = true;
}
}
}
}else {
//hash索引处为empty,则坑可用,直接存储
hashArray[idx] = item;
standFlag = true;
}
if( !standFlag ) {
System.err.println("插入失败!");
}
}检索
/**
* 发生hash冲突时,检索效率就会低了,所以hash算法很关键,唯一的最好
* @param key
* @return
*/
static DataItem search(int key) {
int idx = hashCode(key);
while(null != hashArray[idx]) {
//如果存在了哈希冲突(即哈希值已经被占用了)
if(hashArray[idx].key == key) {
//如果hash相同的索引key值一样则检索到了
return hashArray[idx];
}
//hash冲突,没有检索到,则线性推测查找
idx++;
//环绕检索,下一个索引位置
idx = hashCode(idx);
}
return null;
}完整的哈希检索、插入程序示例
package org.byron4j.dsaa;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
/**
* hash 表数据结构实例详解
* <pre>
* 在哈希表中,数据以数组格式存储,其中每个数据值都有自己唯一的索引
* 哈希是一种将一系列键值转换成数组的一系列索引的技术
* </pre>
* @author BYRON.Y.Y
*
*/
public class HashTableExample {
private static int SIZE = 20;
private static DataItem[] hashArray = new DataItem[20];
public static void main(String[] args) {
System.out.println(Arrays.asList(hashArray));
/*insert(new DataItem(100, 1));
insert(new DataItem(100, 2));
insert(new DataItem(100, 42));
insert(new DataItem(100, 62));
insert(new DataItem(100, 82));
insert(new DataItem(100, 102));
insert(new DataItem(100, 122));
insert(new DataItem(100, 142));*/
//打乱顺序测试hash
insert(new DataItem(100, 1));
insert(new DataItem(100, 2));
insert(new DataItem(100, 102));
insert(new DataItem(100, 122));
insert(new DataItem(100, 42));
insert(new DataItem(100, 82));
insert(new DataItem(100, 62));
insert(new DataItem(100, 142));
insert(new DataItem(100, 162));
insert(new DataItem(100, 182));
insert(new DataItem(100, 202));
insert(new DataItem(100, 222));
insert(new DataItem(100, 242));
insert(new DataItem(100, 282));
insert(new DataItem(100, 262));
insert(new DataItem(100, 302));
insert(new DataItem(100,322));
insert(new DataItem(100, 342));
insert(new DataItem(100,362));
insert(new DataItem(100, 382));
System.out.println(Arrays.asList(hashArray));
}
static class DataItem{
int data;
int key;
public DataItem(int data, int key) {
super();
this.data = data;
this.key = key;
}
@Override
public String toString() {
return "DataItem [key=" + key + "]";
}
}
/**简易Hash方法,取模*/
static int hashCode(int key){
return key % SIZE;
}
/**
* 发生hash冲突时,检索效率就会低了,所以hash算法很关键,唯一的最好
* @param key
* @return
*/
static DataItem search(int key) {
int idx = hashCode(key);
while(null != hashArray[idx]) {
//如果存在了哈希冲突(即哈希值已经被占用了)
if(hashArray[idx].key == key) {
//如果hash相同的索引key值一样则检索到了
return hashArray[idx];
}
//hash冲突,没有检索到,则线性推测查找
idx++;
//环绕检索,下一个索引位置
idx = hashCode(idx);
}
return null;
}
/**
* 插入新值到hash表
* <pre>
* hash后,发现坑位没有被占,则占有该坑位;
* hash后,发现该坑位被占了:
* Step1: key和新插入的key不等,则使用线性推测方式,按队列顺序往后打探下一个坑位的情况(这是一个循环表顺序)
* Step2: 循环打探坑位:发现新坑位则占住
* </pre>
* @param item
*/
static void insert(DataItem item) {
boolean standFlag = false;
//获取hash索引
int idx = hashCode(item.key);
if( null != hashArray[idx] ) {
if( hashArray[idx].key != item.key ) {
//【被占】---》 则使用线性推测方式处理,找到空位进入
while( null != hashArray[idx] && hashArray[idx].key != item.key ) {
idx = hashCode( ++idx );
if( null == hashArray[idx] ) {
hashArray[idx] = item;
standFlag = true;
}
}
}
}else {
//hash索引处为empty,则坑可用,直接存储
hashArray[idx] = item;
standFlag = true;
}
if( !standFlag ) {
System.err.println("插入失败!");
}
}
}
运行结果如下:
[null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null] [DataItem [key=382], DataItem [key=1], DataItem [key=2], DataItem [key=102], DataItem [key=122], DataItem [key=42], DataItem [key=82], DataItem [key=62], DataItem [key=142], DataItem [key=162], DataItem [key=182], DataItem [key=202], DataItem [key=222], DataItem [key=242], DataItem [key=282], DataItem [key=262], DataItem [key=302], DataItem [key=322], DataItem [key=342], DataItem [key=362]]