一、什么是分布式系统
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。。。
在很多文章中,主要讲分布式系统分为分布式计算(computation)与分布式存储(storage)。计算与存储是相辅相成的,计算需要数据,要么来自实时数据(流数据),要么来自存储的数据;而计算的结果也是需要存储的。在操作系统中,对计算与存储有非常详尽的讨论,分布式系统只不过将这些理论推广到多个节点罢了。
那么分布式系统怎么将任务分发到这些计算机节点呢,很简单的思想,分而治之,即分片(partition)。对于计算,那么就是对计算任务进行切换,每个节点算一些,最终汇总就行了,这就是MapReduce的思想;对于存储,更好理解一下,每个节点存一部分数据就行了。当数据规模变大的时候,Partition是唯一的选择,同时也会带来一些好处:
(1)提升性能和并发,操作被分发到不同的分片,相互独立
(2)提升系统的可用性,即使部分分片不能用,其他分片不会受到影响
二、分片Partition与复制集Replication
理想的情况下,有分片就行了,但事实的情况却不大理想。原因在于,分布式系统中有大量的节点,且通过网络通信。单个节点的故障(进程crash、断电、磁盘损坏)是个小概率事件,但整个系统的故障率会随节点的增加而指数级增加,网络通信也可能出现断网、高延迟的情况。在这种一定会出现的“异常”情况下,分布式系统还是需要继续稳定的对外提供服务,即需要较强的容错性。最简单的办法,就是冗余或者复制集(Replication),即多个节点负责同一个任务,最为常见的就是分布式存储中,多个节点复杂存储同一份数据,以此增强可用性与可靠性。同时,Replication也会带来性能的提升,比如数据的locality可以减少用户的等待时间。
下面这种来自Distributed systems for fun and profit 的图形象生动说明了Partition与Replication是如何协作的。
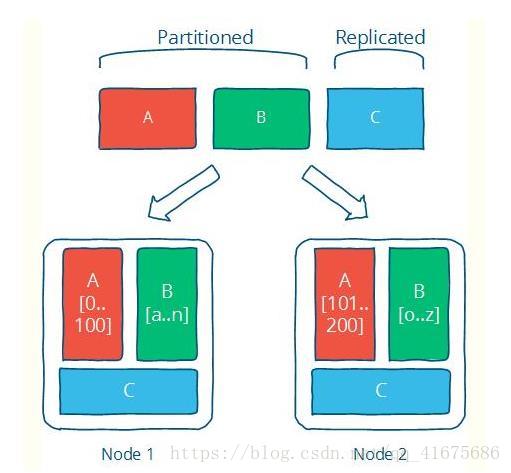
Partition和Replication是解决分布式系统问题的一记组合拳,很多具体的问题都可以用这个思路去解决。但这并不是银弹,往往是为了解决一个问题,会引入更多的问题,比如为了可用性与可靠性保证,引用了冗余(复制集)。有了冗余,各个副本间的一致性问题就变得很头疼,一致性在系统的角度和用户的角度又有不同的等级划分。如果要保证强一致性,那么会影响可用性与性能,在一些应用(比如电商、搜索)是难以接受的。如果是最终一致性,那么就需要处理数据冲突的情况。CAP、FLP这些理论告诉我们,在分布式系统中,没有最佳的选择,都是需要权衡,做出最合适的选择。
三、分布式系统挑战
分布式系统需要大量机器协作,面临诸多的挑战:
第一,异构的机器与网络:
分布式系统中的机器,配置不一样,其上运行的服务也可能由不同的语言、架构实现,因此处理能力也不一样;节点间通过网络连接,而不同网络运营商提供的网络的带宽、延时、丢包率又不一样。怎么保证大家齐头并进,共同完成目标,这四个不小的挑战。
第二,普遍的节点故障:
虽然单个节点的故障概率较低,但节点数目达到一定规模,出故障的概率就变高了。分布式系统需要保证故障发生的时候,系统仍然是可用的,这就需要监控节点的状态,在节点故障的情况下将该节点负责的计算、存储任务转移到其他节点
第三,不可靠的网络:
节点间通过网络通信,而网络是不可靠的。可能的网络问题包括:网络分割、延时、丢包、乱序。
相比单机过程调用,网络通信最让人头疼的是超时:节点A向节点B发出请求,在约定的时间内没有收到节点B的响应,那么B是否处理了请求,这个是不确定的,这个不确定会带来诸多问题,最简单的,是否要重试请求,节点B会不会多次处理同一个请求。
总而言之,分布式的挑战来自不确定性,不确定计算机什么时候crash、断电,不确定磁盘什么时候损坏,不确定每次网络通信要延迟多久,也不确定通信对端是否处理了发送的消息。而分布式的规模放大了这个不确定性,不确定性是令人讨厌的,所以有诸多的分布式理论、协议来保证在这种不确定性的情况下,系统还能继续正常工作。
四、为什么你要使用分布式?
分布式系统并非灵丹妙药,解决问题的关键还是看你对问题本身的了解。通常我们需要使用分布式的常见理由是:
为了性能扩展——系统负载高,单台机器无法承载,希望通过使用多台机器来提高系统的负载能力
为了增强可靠性——软件不是完美的,网络不是完美的,甚至机器本身也不可能是完美的,随时可能会出错,为了避免故障,需要将业务分散开保留一定的冗余度。在以提供 Service 为主的服务端软件开发过程中常常遇到这些问题。
五、一些分布式方案能解决你的问题,另一些却不能,要学会的其实是选择
笼统的讨论分布式没有太大的意义,就如我刚才所谈的,实际上分布式很容易实现。真正难的地方在于如何选择正确的分布方案。
例如,当你想要建立一个分布式的数据管理系统的时候,你就必须得面对“一致性”问题。如果你对数据一致性要求很高,你就不得不容忍一些缺陷例如规模伸缩困难;而如果你放弃它,你可以轻松伸缩规模,但你必须解决好由此带来的一系列数据不一致导致的问题。(CAP 问题)
于是你会意识到,有许多种分布方案,为了正确解决你的问题,你需要对每一个方案都进行了解,并评估,选择不同的方案有时候区别不大,有时候却会深刻的影响整个系统中其他部分的工作方式,甚至影响用户界面中用户操作时的流程。这是我们学习分布式系统的重点所在。
六、分布式学习入门——基础知识要点
如我前面所讲,分布式入门不难。主要包含如下知识点:
Process(进程)。在分布式系统中,进程是基本单元。
通信协议。Process 间需要相互配合才能完成工作,因此通信协议是最基本要解决的问题。这部分其实挺复杂,牵涉面光,不过核心还是抓住两方面,一是存在哪些需求,二是各个协议如何满足这些需求命名法。两个 Process 要通信,必须相互知道对方的名字,名字可以是数字,也可以是结构化的字符串。例如众所周知域名系统就是一种命名方案,但是方案还有很多,各有特点协作。
上面都在谈 Process 之间的通信,可是为什么要通信?因为要协作。协作是个复杂的主题,其中最基本最基本的一个问题就是同步问题。而聊同步问题必然要聊“锁”……知识点就这么展开了。
上面几点是最基础的知识。了解了这些其实就算入门了。可是如何进阶呢?那么必然要开始学习下面的问题:
一致性。数据存储时,最基本的问题。其实也是实际设计系统时常常需要反复考虑的问题
容错。冗余是容错的基础,但并不是全部,分布式本身为实现容错提供了一些便利,这也是实际设计系统时常常需要考虑的问题
以上都是分布式系统的理论基础,上海尚学堂Java学科在年前做了重大改进更新,加入了分布式系统课程,详情可以点击 上海java培训 查看上海尚学堂Java课程大纲和详情。获取免费资料或者试听资格可以联系客服咨询。
本文部分参考:xybaby https://www.cnblogs.com/xybab...