Embedding group and obstacle information in LSTM networks for human trajectory prediction in crowded scenes
在LSTM网络中嵌入群体和障碍物信息,以在拥挤的场景中进行人体轨迹预测
收录于 Computer Vision and Image Understanding
作者:Niccoló Bisagno, Cristiano Saltori, Bo Zhang, Francesco G.B. De Natale, Nicola Conci
论文地址:
发表时间:30 October 2020
备注:
开源代码:https://github.com/mmlab-cv/Group-Obstacle-LSTM
这篇文章只是和我最初的一些idea一致才仔细读,性能和创新没有很好
摘要
在这项工作中,我们提出了一个框架,通过丰富在人群中行走的行人之间的社会关系以及环境布局来丰富学习模型,从而改进人群运动预测的最新模型。
我们观察到与社会相关的人倾向于表现出连贯的运动模式。
利用运动连贯性,我们能够对具有相似运动属性的轨迹进行聚类,并改善轨迹预测,尤其是在组级别上。
此外,我们还将环境模型也纳入模型中,以确保更现实,更可靠的学习框架。
我们在标准人群基准数据集上评估了我们的方法,展示了其有效性和适用性,提高了轨迹预测的准确性。
1 引言
然而,这些方法既没有利用行人之间的现有社会关系(例如,夫妻在一起散步),也没有利用与环境中的障碍物的相互作用。
我们观察到,与社会相关的人,例如朋友/夫妇/家人,倾向于按照连贯的运动方式运动。
此外,在环境中航行的行人受到场景中是否存在障碍物的很大影响。
现有的模型(例如SFM)会针对障碍物提供排斥力,从而对逃避行为进行建模。
但是,像Alahi等人这样的深度学习模型, (2016); Vemula等。,(2018); Lee等, (2017)没有提供任何形式的障碍意识。
摘自Bisagno等人提出的初步工作,(2018),在这项工作中:
•我们将社交群体定义为通过利用运动连贯性而在时间上共享相似运动特性的行人,(2012)。这样,可以突出显示和分割同一组内的行人。
•我们展示了如何利用已识别的社会关系来改善预测。
•我们在深度学习框架中添加了障碍注释,以完善和改进预测任务的结果。
•我们展示了社交团体和环境中固定障碍物的组合表示如何改善轨迹预测的性能。
本文的结构如下。在第2节中,报告并简要分析了最具代表性的最新作品。在第4节中,提出了建议的框架。在第5节中,我们介绍了实验设置(第5.1节),定量结果(第5.2节)和定性结果,例如预测的轨迹(第5.3节)。结束语在第6节中进行了总结。
2 相关工作
有关人群分析的最新文献的详细概述,尤其是人群动力学建模,社交活动预测和群体细分,可以在以下调查论文中找到:Li等,(2015)Grant和Flynn(2017)Kok等, (2016)。因此,在接下来的段落中,我们将更多地关注与群体分析,避障和预测有关的工作。
2.1. Group analysis in crowds(人群中的群体分析)
早期方法面临着采用轨迹作为人群中低水平运动特征的群体分析问题。通过将具有相似运动趋势的轨迹聚类,行人可以关联到不同的群体。在钟等人的论文中,(2015年),k均值被用来学习场景中不同的运动方式。在Lawal等,(2017)作者依靠支持向量聚类对行人进行分组。在周等,(2012年),提出了一种相干过滤策略来检测在拥挤的环境中的相干运动模式。
就集体活动的代表而言,Ge等,(2012年)检测到一起旅行的小团体。 Ryoo和Aggarwal(2011)介绍了小组活动的概率表示,目的是识别不同类型的高级小组行为。 Yi等,(2015年)调查了固定人群与行人之间的相互作用,以分析行人的行为,包括路径预测,目的地预测,个性分类和异常事件检测。邵等人,(2016年)提出了一系列与场景无关的描述子,以定量描述群体的属性,例如集体性,稳定性,统一性和冲突性。 Bagautdinov等,(2017)提出了一个统一的端到端框架,用于使用深度循环网络进行多人动作本地化和集体活动识别。
2.2. Obstacle avoidance(避障)
在文献中,通常如Helbing和Molnar(1995)Pelechano等人所提出的那样,障碍物通过作用力限制了移动主体,(2007),或作为流体的边界,如Treuille等,(2006)。
最近已采用数据驱动的方法来捕获和建模人群和障碍物之间的交互。总体思路包括尝试学习和复制与人群集体行为有关的局部或全局特征。向量场可用于多种作品中,以了解真实场景的速度和导航特征。 Patil等,(2011年)使用学习或手动绘制的矢量场来引导人群在环境中的流动。如Bisagno等人所提出的,依赖于目标的速度场也可用于在全球范围内指导仿真(2017)。 Hu等,(2008)提出了一种解决方案,以处理全球和局部人群流动,作为从真实场景转移到模拟场景的功能,在瞬时运动场的基础上学习人群运动模式。
2.3. Human behavior prediction(人类行为预测)
社交活动的预测最近引起了广泛的关注,尤其是在人群分析领域。就交互建模而言,Hellbing和Molnar(1995)提出了众所周知的SFM,该模型依靠牛顿力来模拟行人之间的交互,并指导每个特工实现其目标。其他模型,例如连续人群模型(Treuille et al。(2006)),能够使用先验来重现人类的互动。人群被建模为体液,并且代理商受其目标,位置,首选速度和不适因素影响。在阿拉希等。 (2014年),提出了“社会亲和力地图”功能以及“起点和终点”先验信息,以使用多视图监控摄像头预测行人的终点。在机器人技术中,倒数速度障碍(RVO)(请参见Van Den Berg等人(2011))及其扩展(Chandra等人(2019))被广泛用于对代理之间的避免碰撞进行建模。所有这些方法都能够描述与模型相关的强先验条件下的人群行为。这些都基于能量潜力,相对距离和手工制定的规则。
最近,神经网络已被用来预测拥挤视频中的事件。特别是,随着深度生成模型(如RNN,LSTM,VAE等)的出现,可以有效地解决序列间生成问题,从而有可能直接处理长期预测任务。
Jain等,(2016年)采用结构化RNN,该结构结合时空图和递归神经网络对场景中的运动和交互进行建模。
Varshneya和Srinivasaraghavan(2017)在Social-LSTM上同时应用了软注意力和硬连线注意力,从而显着提升了轨迹预测性能。
Varshneya和Srinivasaraghavan(2017)提出了一种软注意力机制,可以利用空间感知的深度注意力模型来预测个人的前进路径。
Vemula等,(2018)提出了一种新颖的社交注意力模型,该模型可以捕获场景中每个人的相对重要性。
Haddad等,(2019)还采用注意力模型来改进不同情况的建模。 Alahi等,(2016)提出了Social-LSTM,通过添加新的社交池层来模拟邻里人与人之间的互动。
在李等 (2017)作者提出了一种深度随机IOC RNN编码器-解码器框架,以预测动态场景中多个交互代理的未来路径。
Ballan等,(2016)考虑了移动主体的动力学和场景语义来预测特定场景的运动模式。
Pei等,(2019)引入了社交亲和力图,通过对社交关系建模来改善轨迹预测任务。
在古普塔等(2018)采用生成对抗神经网络(GAN)来预测在拥挤的环境中社会上合理的轨迹。
3 Preliminaries: the Social LSTM model
在路径预测领域,LSTM网络在预测行人行为方面表现出良好的能力。 Alahi等人提出的Social-LSTM模型(2016年)能够捕获每个代理的邻域状态(由社会隐藏状态张量表示)来完善轨迹预测。
第j个行人,在场景中称为 t 时刻的 ped j,由LSTM网络的隐藏状态
表示。
令隐藏状维数为D,邻域大小为N0。
代理人pedi的邻域由定义为张量Hit的社交池层描述,维度为N0×N0×D:

hj t-1:在t-1处pedj(∀j,i)的LSTM的隐藏状态
Ni:代表行人pedi的邻居集合
1mn [x,y]:是位置(m,n)的存在指标,
定义为:

池化操作的图形表示如图4a所示

社会隐藏状态张量Hi t的表示。黑点表示感兴趣的行人。其他行人pedj(∀j,i)以不同的颜色代码显示。由N0×N0单元所描述的邻里状态,通过将同一单元格中的邻居集合在一起来保留空间信息。
预测中的下一个位置(xi t + 1,yi t + 1)取决于上一个时间步hi t的隐藏状态。
受Graves(2013)的启发,并在Alahi等人的论文中进行(2016),预测了以下参数,这些参数表征了双变量高斯分布:均值

,标准偏差
和相关系数ρit + 1。
原始模型使用5×D权重矩阵Wp估计参数。
因此,下一个时间步t + 1的坐标计算如下:

为了估计LSTM模型的参数,在当前时间t内,最小化了代理人pedi的对数似然损失L:

对模型进行训练,以使属于数据集的所有轨迹的对数似然损失最小化。
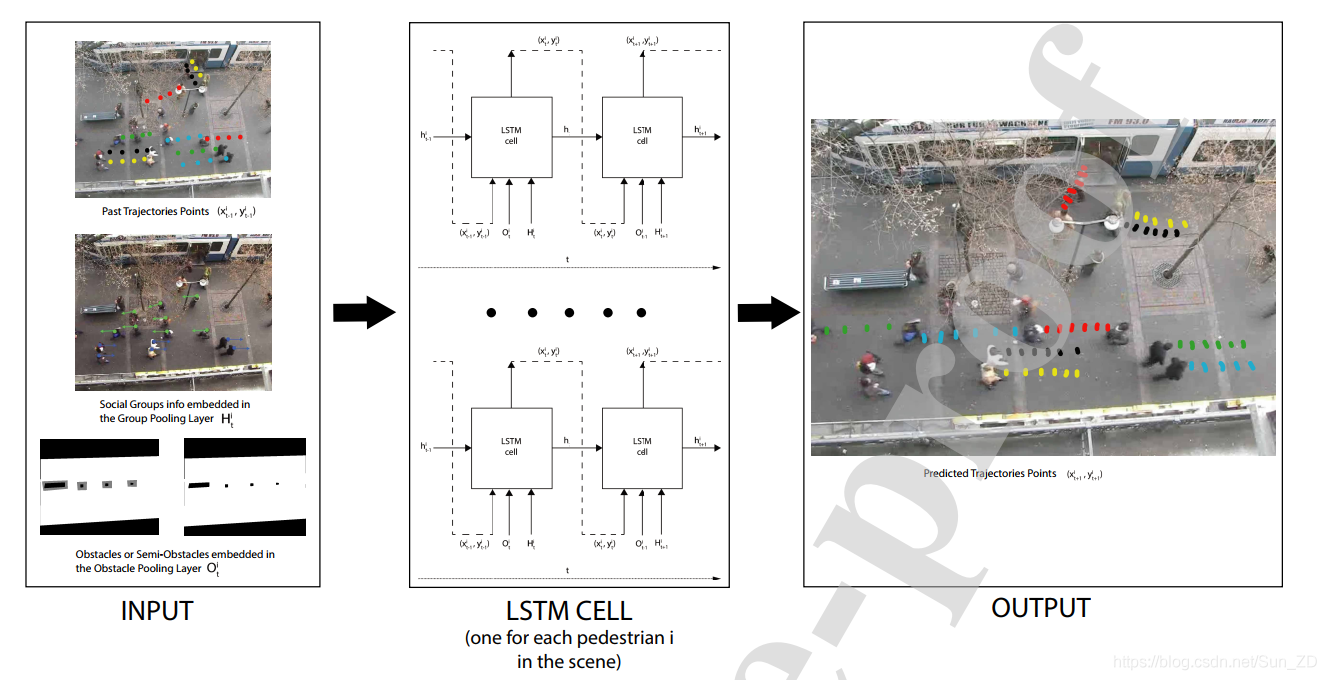
4 The proposed method
在拥挤的场景中移动的行人会根据其他行人的运动和位置以及邻里障碍物的位置来调整他们的运动。
因此,对个人轨迹的预测必然也需要考虑到代理人移动的环境。
在阿拉希等,(2016年),考虑到行人与邻居之间的相互作用来模拟邻里状态。
与Social-LSTM的原始公式(在第3节中简要介绍)相比,我们建议使用一种更全面的模型,称为Group-LSTM,该模型包括人群中行人之间的社会关系,从而提高了预测性能。
此外,我们提出了一个名为Obstacle-LSTM的系统模块,其目标是利用与环境中固定障碍物有关的信息来扩展对代理程序当前状态的描述。
4.1. Group-LSTM
如前几段所述,行人在拥挤场景中的运动受到周围其他人的行为及其相互关系的极大影响。
固定人群,一群步行者一起走,相反方向的人,会对一个步行者采取的行动产生不同的影响。
因此,我们提出了一个框架,该框架能够考虑感兴趣的对象是否与周围环境中的行人一致地行走。
通过利用相干滤波方法,周等人(2012年)我们首先检测到人群中相关运动的人,然后采用Social-LSTM进行预测未来的轨迹。
这样,我们可以提高预测性能,考虑场景中社交相关和无关的行人之间的交互。
4.1.1. Pedestrian trajectory clustering行人轨迹聚类
相干运动描述了粒子(行人个体)在人群中的集体运动。
相干滤波Zhou等,(2012)介绍了一个先验,旨在描述相干邻居不变性,即相干运动的粒子之间的局部时空关系。
该算法基于两个步骤:
首先,它检测场景中行人的连贯运动。
然后,将连贯移动的点关联到同一群集。
点群集将继续发展,并且随着时间的推移将出现新的群集。最终,每个行人i被分配到一个集群si。
相干滤波的输出包含以相干方式移动的人的集合si(i = 1,2,···,n)。
相干滤波的原始实现依赖于KLT跟踪器Tomasi和Kanade(1991),其目的是检测用于跟踪和生成轨迹的候选点,然后将其用作算法的输入。
我们的目标是将行人分为几组,每组中的每个人都用一个点表示,如图2所示。
因此,在不失一般性的前提下,我们将相干滤波算法直接应用于行人的地面真实性轨迹。
4.1.2. Group trajectory prediction
在Social-LSTM模型中,每个行人都是使用LSTM网络建模的,如图3所示。
然后,每个行人通过所谓的社交池层与附近的其他人链接。
社交池层允许行人共享其隐藏状态,从而使每个网络都可以基于其自身的隐藏状态和邻域中的隐藏状态来预测某个人的未来位置。
场景中时间t处的行人由LSTM网络中的隐藏状态表示。
我们分别将
隐藏状态维度设置为D,
将邻域大小设置为N0。
使用等式中的张量Hi t描述第i个行人pedi的邻域。
如公式1所示 ,维度尺寸等于N0×N0×D:
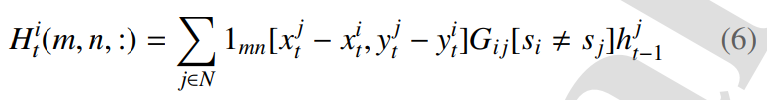
如公式2所示,其中1mn [x,y]是一个用于选择等式中定义的邻域中行人的指标函数,。
如果两个行人i和j属于同一相干集合si,则在为每个行人计算社交池层时将不考虑它们。函数Gi j [i∈si,j∈si]是一个指标函数,定义如方程7:

这样做,每个行人的社交池层仅包含有关与社交无关的行人的信息,这些行人没有与所考虑的代理人紧密联系。
如果附近的所有行人都属于不同的连贯组,则我们的模型的表现类似于Social LSTM Alahi等人, (2016)。
如果附近的所有行人都属于同一相干组,则张量Hi将为0的向量,并且预测行人i的轨迹就好像没有发生社会互动一样。
该操作背后的直觉是,网络通常会学习行人之间的排斥力,从而避免碰撞。
如果行人与社会相关(socially-related),他们将趋于彼此靠近,因此排斥力将变小(几乎被忽略),并且对行进不连贯的行人的未来轨迹的影响也较小。
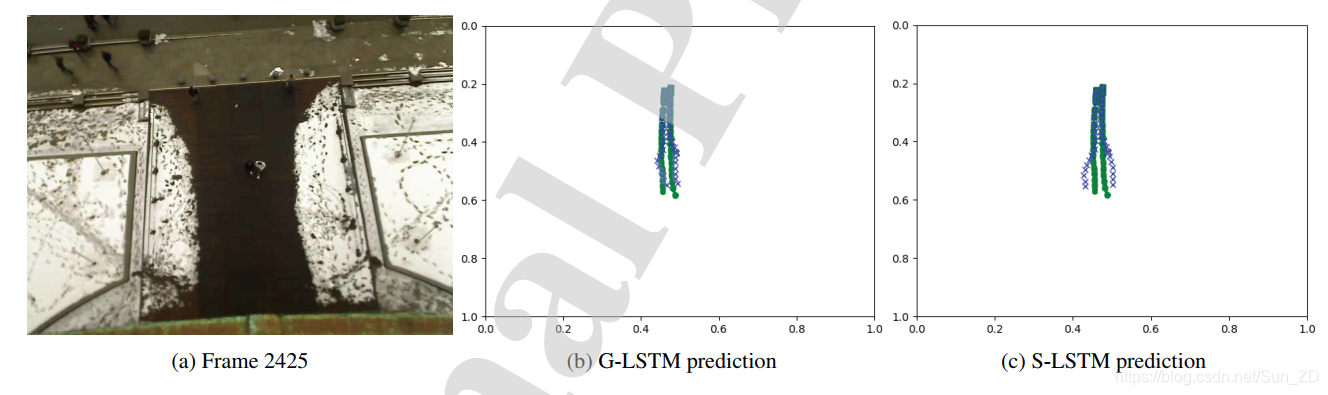
如果在社会统筹中考虑与社会相关的行人,这将导致社会群体四处分散,而不是像图6所示那样保持在一起。
图6显示了缺少组如何导致性能下降。
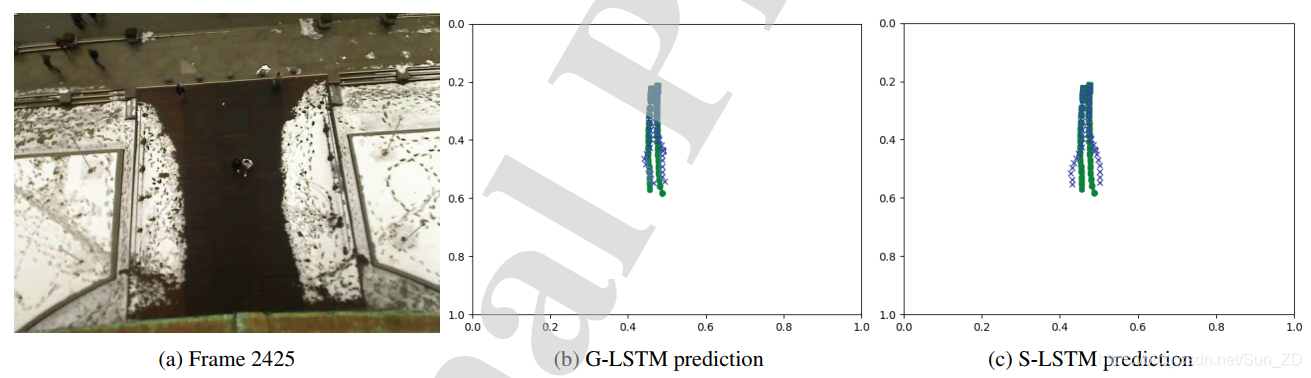
ETH数据集帧2425:
将每个行人的社会张量集中到不属于同一群体的行人中,提高了预测效果。
绿色的点代表地面真实轨迹;蓝色的叉表示预测的路径。使用分组模块可以使预测器比S-LSTM情况下更接近属于同一组的行人
一旦计算出,社会隐藏状态张量就被嵌入到向量ai中。
输出坐标嵌入向量ei t中。遵循第3节中定义,我们可以逐渐预测我们的轨迹。
4.2. Obstacle-LSTM
在环境中固定的障碍物在塑造和确定人群流动方面的影响不可忽略。
根据障碍物的性质,行人采取不同的策略来防止碰撞,并做出主观决定。
然后,我们希望将此信息嵌入建议的模型中,从而考虑代理人附近是否存在障碍。
通过考虑场景中行人与障碍物之间的相互作用,我们利用此附加注释来改善预测性能。
由于自动障碍物检测不在本文的讨论范围之内,因此在当前工作中,我们手动注释场景中固定的障碍物,这是一项一次性操作。
尽管场景还可能包含动态障碍物(例如汽车,自行车),但示例数量太有限,因此无法训练相应的模型。
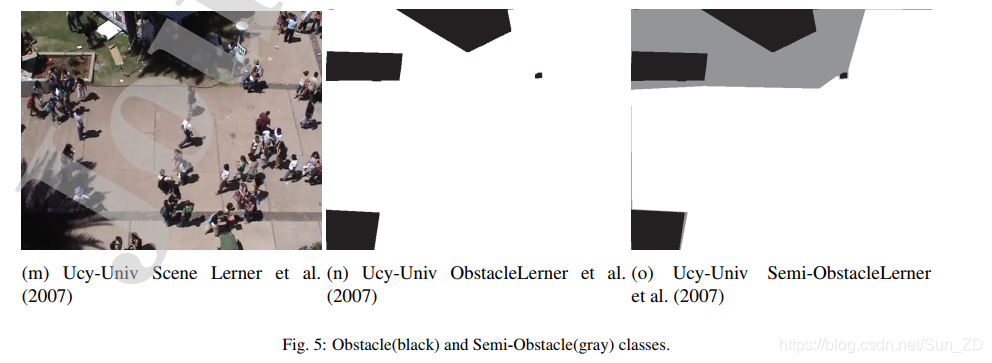
就注释而言,为了完整起见,我们确定了两类障碍:
•必须避免的障碍物,并且行人不能横穿(例如,树木或灯杆,墙壁);
•半障碍物,步行者最好避免(例如,树木,草地或街道上积雪的地方周围的花坛)。
这种区分将推动两个不同的实验:
一个实验仅考虑障碍物,
第二个实验同时考虑障碍物和半障碍物,以便紧密模拟场景中行人在场景布局方面的表现如何。
对这些类别进行注释后,对于从Pellegrini等人获得的每种已研究场景,都会生成两个不同的障碍图(一个仅带有障碍,一个带有障碍和半障碍)(2009)和Lerner等(2007)。
与轨迹注释的过程类似,使用每个数据集的可用单应性,在图像平面上标注障碍物,然后将其坐标以米为单位投影在地平面上。
图5展示了5个感兴趣的场景的障碍物和半障碍物图。从现在开始,如果没有明确提及,我们将使用障碍一词,包括障碍和半障碍。在获得障碍物图之后,相应的坐标已通过在每个外部边界区域上的相等采样点进行注释。


4.2.1. Obstacle Tensor
障碍物汇聚层使行人能够了解附近的障碍物状态,从而提高他们对周围环境的了解。障碍物的配置由障碍张量表示。我们将邻域大小设置为N0。使用张量Oit(尺寸为N0×N0×D)来描述第i个智能体pedi附近的障碍物。我们定义了两种形式的障碍物张量:
•障碍物存在(OP)张量,其中常数值表示给定单元中是否存在障碍物;
•障碍物距离(OD)张量,其中障碍物和目标行人之间的距离表示给定单元中是否存在障碍物。
OP张量表示为:
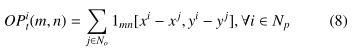
1mn:是行人i在场景障碍物集合No中的每个障碍物j的位置(m,n)的存在函数,
OP张量允许模型学习行人i附近的一个单元格(m,n)是否被占用。
OD张量不仅表示占用,还考虑了观察到的行人i与障碍物j之间的欧几里得模D(i,j),从而:
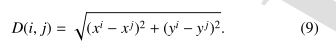
ODi张量表示为:
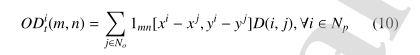
1mn:是行人i在场景障碍物集合No中,
每个障碍物j处行人i的位置(m,n)的存在函数,D(i,j)是i和j之间的欧几里得范数,而Np是存在的人数。
4.2.2 有障碍物的行人轨迹预测
就像在Alahi等人中(2016),障碍张量和社会隐藏状态张量分别嵌入向量bit和ait中。
输出坐标嵌入向量ei t中。
通过以下公式定义结果的重复发生率:
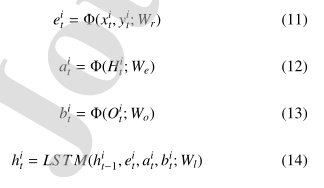
因此,在Obstacle-LSTM中,LSTM单元的输入张量由三个相同大小的嵌入式张量组成(如图1所示):
Social张量
实际行人位置
Obstacle张量。
在部署时,根据我们使用的是OP还是OD,我们可以有4种不同的Obstacle-LSTM配置,再加上障碍物或半障碍物图。
5. Experimental Results
5.1. Implementation Details
PyTorch框架
RMSprop来优化目标函数
网络使用以下超参数训练:
200个spochs,
0.0015学习率,
0.95衰减率。
最终模型具有3个嵌入的输入层,每个输入一层:
时间t时的位置pt,
社交张量 Alahi等(2016)
障碍张量。
相干滤波参数是根据原始论文设置的。因此使用K = 10,d = 1和λ= 0.2进行组聚类。
在UCY 和ETH基准数据集。
UCY数据集包含两个视频的3个视频,共786人。
ETH数据集由两个不同场景的视频组成,总共包含750名行人。
训练和测试过程使用留一法进行,即对4组轨迹进行训练和验证,对其余轨迹进行测试。
5.2. Quantitative results
与文献中的其他工作类似(Pellegrini等(2009); Lerner等(2007)),我们使用以下两个指标评估我们的方法:
•平均位移误差(ADE),即相对于地面真实路径,预测路径的每个点之间的平均位移误差(以米为单位)。
•最终位移误差(FDE),即,预测轨迹的终点与地面真相轨迹的终点之间的距离(以米为单位)。
对于训练和验证(再次与文献中的相关工作一致),我们使用0.4秒的时间间隔观察和预测轨迹。
我们观察8个时间步长的轨迹并预测接下来的12个时间步长,这意味着我们观察轨迹fortobs = 3.2秒,并预测下一个tpred = 4.8秒。
在训练阶段,仅考虑留在场景中至少8秒钟的轨迹。我们将我们的方法与Social-LSTM模型(Alahi等人(2016))以及Gupta等人提出的最新方法进行了比较,(2018)。
我们也将我们的模型与线性模型进行了比较,线性模型使用卡尔曼滤波器在线性加速度的假设下预测未来的轨迹,正如Alahi等人报道的那样。 (2016)。数值结果示于表1。
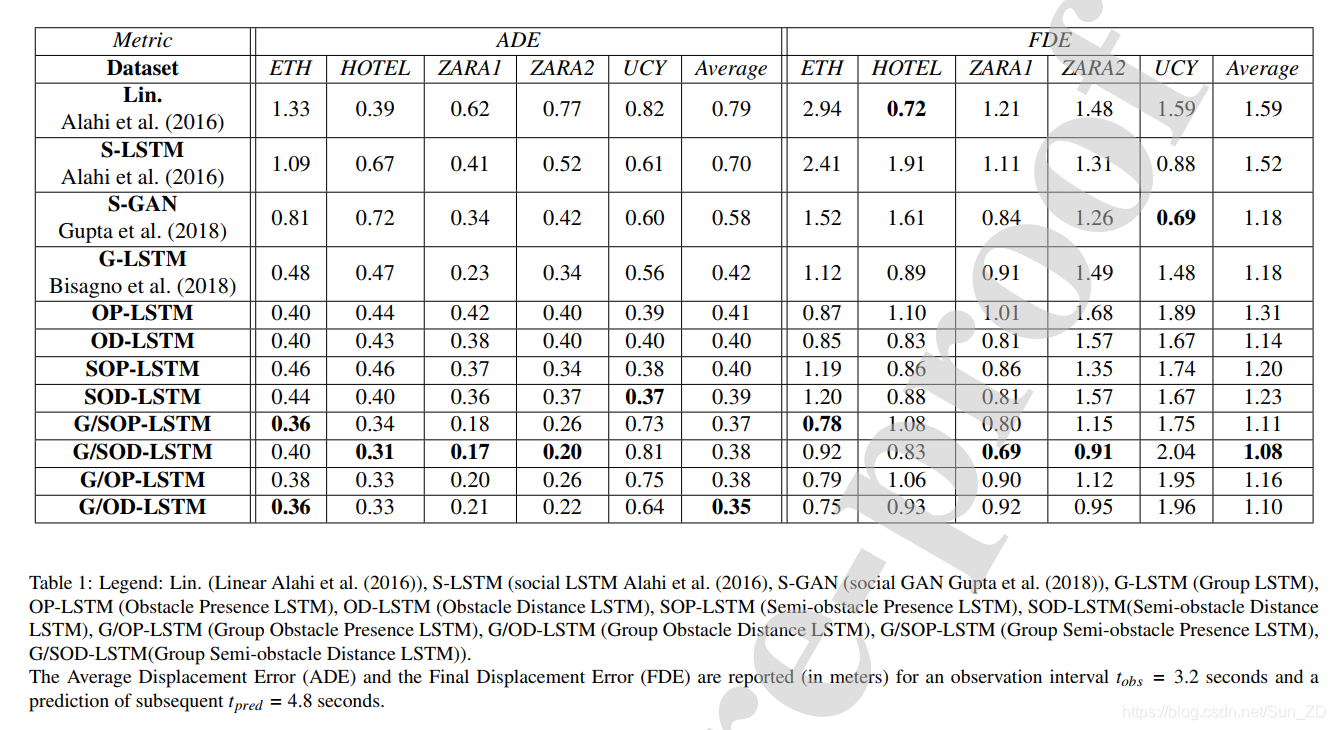
提议的Group-LSTM(G-LSTM)的平均表现要优于Social-LSTM和Social-GAN,尤其是在UCY数据集上。这是由于场景中人群流动的特性所致,通常是由容易识别的,朝相反方向行走的人群组成。对于ETH数据集,运动模式反而变化多且混乱。**所得结果表明,当考虑行人不连贯时,可以提高预测性能。**实际上,运动的变化和轨迹的演变主要受到相对于感兴趣的行人朝不同方向移动的行人的影响。相反,一起走动的人们会像一群人一样相互影响。根据我们是将障碍物还是半障碍物与在场张量或距离张量结合使用,我们的障碍物LSTM的性能会有所不同。由于在两个场景中障碍物所确定的强大影响,Obstacle-LSTM在ETH数据集上的性能优于其他方法。相反,在Zara场景中,未注释移动障碍物(例如汽车),这导致预测任务中的网络性能下降。当结合在一起时,Obstacle和Group-LSTM优于其他方法。使用Group-LSTM与距离张量的组合可获得最佳结果。
5.2.1. Ablation Study.
我们的Group模块允许在每个数据集(但UCY)中都有更好的性能。
UCY数据集的特征在于组合并和分裂时的混乱行为,这导致组模块使我们的方法的整体性能恶化。
总体而言,组模块能够提高网络的性能,尤其是在人群流量更加规则的情况下。
障碍物方法在场景中执行,其特征是在步行空间(例如ETH,UCY)的边缘分布的障碍物较少。
当障碍物位于步行空间的中间时,半障碍物的性能优于障碍物,因此导致场景导航更加困难。
在障碍物和半障碍物情况下,提供障碍物相对于感兴趣的行人的距离都优于Presence方法,因为更精确的信息会传递到网络。
当场景在步行空间的中间出现较少障碍物(例如ETH,UCY)时,性能相似
5.3 定性结果
在5.2节中,我们显示了仅考虑行人不连贯的行人可以提高预测精度。
在本节中,我们将进一步评估预测轨迹的一致性。
通常,基于LSTM的轨迹预测方法遵循数据驱动策略。
此外,人群中行人的未来计划在很大程度上受到他们的目标,周围环境和过去的运动历史的影响。
在社交层中汇总正确的数据可以显着提高预测性能。
为了保证可靠的预测,我们不仅需要考虑时空关系,而且还需要保留行为的社会性质。
根据人际距离的研究(Hall等人(1968); Conci等人(2018)),与不知名的行人一起起步相比,与社会相关的人倾向于在自己的私人空间中更靠近并在拥挤的环境中一起行走。
仅合并不相关的行人将更多地关注宏观的群体间交互作用,而不是群体内部动力学,从而使LSTM网络能够改善轨迹预测性能。
如果两个行人一起成群走动,避免碰撞会以类似的方式影响行人的未来运动。
在图6,图8和图7中,我们显示了一些预测轨迹的示例,这些示例突出了Group-LSTM如何能够以更高的精度预测行人轨迹,展示了当我们将每个人的社交张量集中在一起时,如何改进预测行人只有不属于该组的行人。
在图6中,我们展示了当两个行人不在彼此的汇聚层中汇聚在一起时,如何提高他们在人群中一起行走的预测。
当两个行人汇聚在一起时,网络会施加典型的排斥力以避免碰撞。
但是,由于他们属于同一组,因此每个行人都允许彼此保持近距离。
在图7中,我们显示了彼此接近的两组的序列。

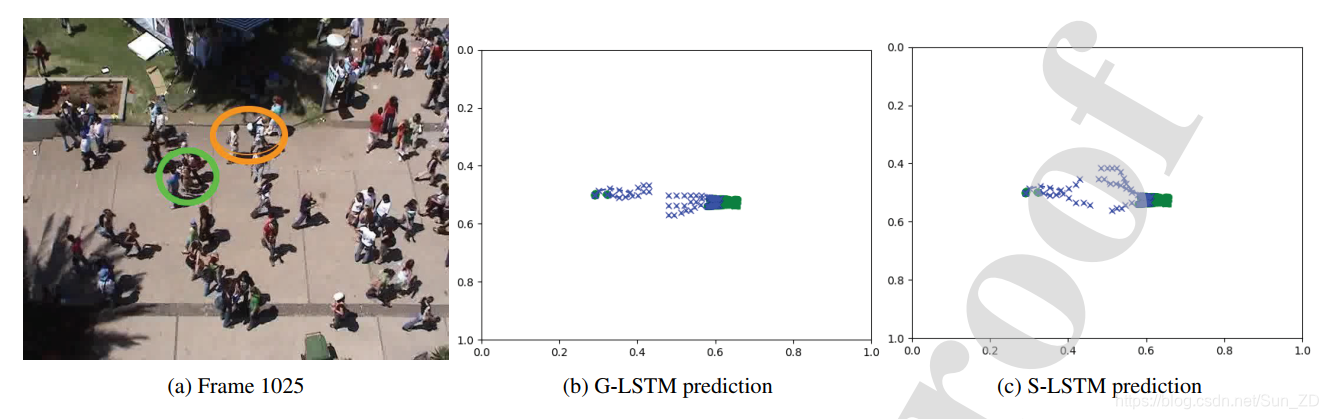
在图8中,我们显示了相对于Social-LSTM,这两组人的预测是如何改进的,展示了预测在环境中移动时属于同一组的行人如何保持在一起的能力。
5 结论
在这项工作中,我们解决了拥挤场景中行人轨迹预测的问题。我们提出了一种新颖的方法,该方法结合了组检测和障碍物注释来完善预测。使用Group-LSTM,相干过滤可用于识别在人群中一起行走的行人,而LSTM网络可通过利用组间和组内动力学来预测未来的轨迹。 LSTM障碍物显示障碍物和非侵入区域如何强烈影响行人的未来轨迹。实验结果表明,在两个公共基准(UCY和ETH数据集)的预测任务中,所提出的LSTM框架将群体信息和可观察的信息嵌入其中,其性能优于Social-LSTM。