fabric源码解析10——文档翻译之Architecture
构架释义
Fabric的构架提供了以下优势:
- Chaincode信任机制(trust)灵活性。Fabric的构架将对于chaincode的信任假设(trust assumptions)从对于ordering的信任假设中分离了出来。换句话说,ordering服务(the ordering service)可能由一个结点集合(orderers)提供并容忍其中的一些结点失败或犯错(即容错性),背书者(endorser)对于每个chaincode来说可能不同。
- 可扩展性。由于负责特殊chaincode的背书者正交于(are orthogonal to)orderers,系统可以比所有功能都由同一个结点实现有更好的规模(指的是效率,交易吞吐量更高)。特别的,这样将导致,如果有一些chaincode指定了互斥的背书者,需要在chaincode与背书者之间引入分区(partitioning)以隔开两者,和允许并行执行chaincode(背书)。除此之外,某些潜在的非常消耗的chaincode的执行,被从ordering服务的关键路径删除了。
- 机密性。fabric构架帮助了那些有交易内容/状态等方面的机密性需求的chaincode的部署。
- 共识(Consensus)模块。该构架模块化并允许热插拔的共识(如,ordering服务)操作。
第一部分:Fabric v1相关的架构的元素
1.系统(System)构架
2.交易背书的基本工作流
3.背书策略
第二部分:后续版本的构架元素
4.账本检查点(Ledger checkpointing)(正在修改中)
1.系统构架
区域链(blockchain)是一个由多个结点相互通信所组成的分布式系统。区域链运行的被称作链码(chaincode)的程序,持有状态(state)和账本数据(ledger data),执行交易。chaincode是核心元素,因为交易是在chaincode上的一系列调用操作。交易必须被背书(be endorsed),只有背书过的交易才可能被提交并作用于状态。区域链中可能存在一个或多个特殊的chaincode用于管理功能和参数,被成为系统链码(system chaincodes)。
1.1.交易
交易可以是两种类型:
- Deploy交易。该交易创建一个新的chaincode并把program作为参数。当一个部署交易运行成功,说明这个新的chaincode已经被“安装”到blockchain上了。
- Invoke交易。该交易涉及到一个chaincode和一个自身提供的function,当交易运行成功,该chaincode会执行指定的function-可能会修改相应的state并返回输出结果。
后文描述的,部署交易其实是特殊情况的Invoke交易。该交易创建了一个新的chaincode,对应的是在一条system chaincode上执行一次Invoke交易。
注意:文档在此假设无论是Deploy交易还是Invoke交易,前提都是已经部署好了chaincode。该文档未描述的部分有:a)查询交易的最佳方法(包含在v1版本中) b)对交叉链的支持(v1之后版本的特征)。
1.2.区域链数据结构
1.2.1.状态
区域链最新的状态(或者简单点儿,状态)是按照版本化的“键/值”这样的键值对(key-value pair)格式存储(KVS),键是名称,值则是任意的点(blob)。这些条目(账目)由运行在区域链上的chaincode通过获取(get)或存入(put)这样的键值存储操作(KVS-operation)来维护。状态是永久性存储的,对状态的修改会被记录。注意状态的格式采用版本化的KVS(这里版本化的意思是说,键值对中的值是用来存储版本号的),一种实现可能就是使用现行的KVSs,也可能是关系型数据库管理系统(RDBMS)或者其他解决方案。
更正式的来说,状态s被模型化为K->(V x N)的映射元素,其中:
K 是一个键集合
V 是一个值集合
N 是一个无限版本号序列集合。该集合的内射函数(Injective function)“next:N->N”(内射函数,在go中可以把它想象成一个集合结构体的挂载函数func (*s set)next(now n) n{…},其中set是这个集合结构体,n是版本号类型)使用一个元素N去返回N的下一个版本号。
V和N都包含一个特殊的元素“\bot”,该元素是N的最小值(即最小的版本号)。初始时所有的键被映射成“(\bot,\bot)”。比如对于“s(k)=(v,ver)”,我们可以用“s(k).value”表示v,用“s(k).version”表示ver。(解释一下:即s这个状态k的映射是(v,ver),可以把(v,ver)想象成一个有两个成员的结构体。v应该是和k对应的,同一个事物,由k和v对应,k不变,v也不变,ver则是独立的,这点可以从下面的put函数看出来。可以暂时这么理解,一个状态映射中,kv组合算是标识着一个独立的对象,在该对象下进行着各种版本的变化)。
KVS操作如下一样被模式化:
- put(k,v),这其中,k属于K这个集合,v属于V这个集合。该函数将当前区域链的状态s改变为s’。如此的话(可推算出等式),只要k’不等于k,则有s’(k)=(v,next(s(k).version)),s’(k’)=s(k’)。(即状态s’映射的k的值为(v和下一个版本号),状态s’的k’映射与s的k’映射的值相等,s’表示现在的状态,s表示过去的状态,同时也说明所谓世界状态,前后是连贯和记录的,你可以从s’找回过去s时的状态,也可以从过去s获取现在s’的状态)。
- get(k),返回s(k)。即返回k所映射的状态。
State由peer结点操作维护,而不是客户端或orderer。
状态分区(这个分区是分割的意思,参考糗百的分割,一般在此区域是对同一主题的一些解释性说明或版本差异)。在KVS中的键值可以被认为是chaincode的名称,也就是说特定的chaincode所进行的交易只能修改属于他的键值。原则上,任何chaincode都可以读去属于其他chaincode的键值。对于交叉链交易(cross-chaincode transactions),修改状态的权限属于两个或更多的chaincode,这是v1后续版本的特性。
1.2.2.账本
账本(Ledger)提供了一个可验证的历史记录,该记录保存了系统运行期间所有成功或失败的状态的改变,这里的成功和失败也就是交易(transactions)的成功和失败。
账本作为一个全部按顺序排列的由交易产生的块的哈希链(hashchain),由ordering服务(参看1.3.3部分)构建。该哈希链在账本中把块(block)全部依序排列,每个块包含一个全部被依序排列的交易的数组。所有的交易之间,都必须遵循这种全部的依序排列。
所有的peer结点都保存着账本,一部分orderer结点也可以选择性的保存。我们在一个orderer结点的上下文(context)中查阅账本相当于查阅orderer类账本(OrdererLedger),在一个peer结点的上下文中查阅账本相当于查阅peer类账本(PeerLedger)。PeerLedger不同于OrdererLedger之处在于,peer结点维护一个位掩码(bitmask)并以此分辨有效的交易和无效的交易(更详细的说明请参考XX部分)。
peer结点可以像在XX(v1后续版本特性)部分所描述的那样修改PeerLedger。orderer为了容错性和PeerLedger的效率而维护OrderLedger,并可以在任何时间修改OrderLedger,提供的ordering服务的属性也被相应维护。
账本允许peer重新实现所有交易历史,重构状态。因此,在1.2.1部分描述的状态是一个可选择的数据结构。
1.3.结点(Nodes)
结点(Node)是区域链交流的实体。一个Node仅仅是一个逻辑功能(logical function),从这种意义上说多种不同类型的node可以在同一个实体服务器上。结点问题上需要在意的是,如何在信任领域(trust domains)组织这些结点,如何将这些结点与逻辑实体(logical entities)联合起来并由这些逻辑实体控制这些结点。
(这里的逻辑功能和逻辑实体的关系,如ordering服务,它是一项服务,也即一项逻辑上的功能,可以称之为节点,因为它属于整体功能中的一部分,整体服务过程中的一节,因此称为节点。而实实在在编译所成并运行在系统中的orderer程序,称为结点,它实现了或者说被设计成用于ordering服务,是承载ordering服务的实体,因此称之为结点。逻辑功能与逻辑实体可以一一对应,也可以根据实际需要一对多,多对多。而在faric中,都是一对一的关系,所以一般不用区分这两者)
这里有三种类型的结点:
- 客户端(Client)或提交客户端(submitting-client):一个客户端,该客户端提交(submits)真实的交易召唤(transaction-invocation)给背书者,广播交易请求(transaction-proposals)给ordering服务。(这里,背书前的交易称为invocation,是背书后的交易称为proposals,invocation是为了proposal而去“召唤”各个背书者进行背书)
- Peer:一个结点,该结点提交(commits)交易,维护世界状态和一个账本的拷贝(参看1.2)。此外,peer可以当一个特殊的背书者的角色。(这里的提交与客户端的submitting要进行区别,submitting类似与提交初稿供大家审阅修改,而commit则类似于将审阅后的定稿提交,用于发行)。
- ordering服务结点(Ordering-service-node)或者orderer:一个结点,该结点运行着信息传送服务,提供消息分发的担保,如原子性,全部排序广播。
这些类型的结点在下文有更详细的解释:
1.3.1.客户端
客户端代表着一个扮演了一半的终端用户(end-user)角色的实体。它必须连接到一个peer,才能在区域链上通信(communicate)。它可以根据它的选择连接到任何一个peer上。客户端创建并因而调用(invoke)交易。
如在章节2所详述的,客户端既与peer通信,也与ordering服务通信。
1.3.2.peer
一个peer从ordering服务接收排序后的块形式的状态升级信息,然后维护相应的世界状态和账本。
peer可以额外的扮演一个背书peer(endorsing peer)的角色,或者说是背书者(endorser)。背书者这个特殊的功能存在于特别的chaincode上(这里的特别就是说的该chaincode需要背书),并在提交交易之前对交易进行背书中发挥作用。每个chaincode可以指定一个背书策略(endorsement policy),该策略可能涉及到一个需要进行背书的peer的集合(即定义了需要哪些peer背书后,该交易才能提交,类似于现实中的一个文件必须有哪些人签过字之后才能生效或者往上层提交一样)。背书策略定义了一个有效的交易背书所具有的必要和满足的条件(典型的就是一个背书者的签名集合),如下文章节2和3描述的那样。在安装新的chaincode的部署交易(deploy transaction)这种特殊情形中,(部署)背书策略指定的像系统chaincode(system chaincode)的背书策略一样。
1.3.3.orderer
orderer结点形成了排序服务(the ordering service),即,一个提供分发保证的通信fabric。排序服务可以以不同的方式被实施:从一个中心化的服务(在开发和测试中使用)到面向不同的网络、结点错误模型的分布式协议。
ordering服务为客户端和peer提供了一个共享的通信频道(channel),为包含交易的消息(messages)提供广播服务。客户端连接到该频道后可以在频道上广播消息,之后消息会被分发给所有的peer。这个频道支持对所有的消息进行原子分发,即,消息通信是在完全排序分发(total-order delivery)和可靠性的条件下进行的。换句话说,这个频道把同一消息按统一的逻辑顺序输送到所有连接到该频道的peer。这个原子通信担保(atomic communication guarantee)又被称作完全排序广播(total-order broadcast),原子广播(atomic broadcast),或者分布式系统共识机制(consensus in the context of distributed systems)。对于区域链状态来说,被分发的消息就成为了候选交易(供各个peer进行背书,签名等操作)。
分割(ordering服务频道)。ordering服务可能支持多个频道,类似于一个发行-订阅消息系统(publish/subscribe messaging system)。客户端可以连接到给定的频道,之后可以发送消息和获取消息。频道可以被认为是分隔物(partitions),连接到一个频道的客户端不会意识到其他频道的存在,但是客户端可以连接多个频道。尽管一些ordering服务实现,包括fabric,支持多频道,但为了呈现的简洁,接下来的文章中,我们假定ordering服务由单独的一个服务于一个频道/话题组成。
ordering服务API。peer通过ordering服务提供的接口连接到由ordering服务所提供的频道。ordering服务接口由两个基本的操作(更通用的异步事件)组成:
(TODO 为获取客户端或peer指定的的序列号(范围)的对应的块增加接口)
- broadcast(blob):客户端调用此函数,广播一条自定义的消息blob在频道中散播。在拜占庭容错系统的上下文中当发送一个请求到服务器时,这个操作也被称为request(blob)。
- deliver(seqno, prevhash, blob):ordering服务在peer上调用此函数,分发一个消息blob,对应为该消息的指定了一个非负整数序列号seqno,和最近的上一个已经被分发的blob的哈希值prevhash。换句话说,这是一个来自ordering服务的输出事件。有时deliver()在发布-订阅系统中也被称为notify(),在拜占庭容错系统(BFT systems)中也被称为commit()。(这里说的在peer上调用,意思不是说ordering服务在peer上,而是上文所说的,peer通过ordering服务的接口连接ordering服务提供的频道后进行通信,因此这里说在peer上调用此函数,意思是说peer调用此ordering服务函数)。
账本和块的结构。账本(看1.2.2部分)包含ordering服务输出的所有数据。从表面上看,它是一个deliver(seqno, prevhash, blob)事件的队列,根据计算prevhash,如上文所述的那样,该队列形成了一个哈希链(hash chain)。
大部分时间里,出于效率原因,ordering服务会将多个blob消息组成一组,然后在一个单独的deliver事件中输出块,以此替代单个blob一个交易一个交易地输出的方式。这种情况下,ordering服务必须在每一个块中强制并输送确定顺序的blob信息。blob在块中的顺序的数字可以通过ordering服务的操作被动态的确定。
下文中,为了呈现的简单,我们定义ordering服务的功能并在一个deliver事件对应一个blob消息的基础上解释交易背书(章节2)的工作流。通过上文提到的在一个块内的对blob消息确定性的排序,这些很容易被扩展到块上面,假设一个针对块的deliver事件,该块对应的是一个由多个单独的针对块中一个个blob消息的deliver事件组成的队列。
ordering服务属性
ordering服务担保规定了如何广播一条信息和分发信息之间的关系。这些担保描述如下:
- 安全(一致性保证):只要每个peer连接到共享频道足够长的时间(他们可以连接断开或被销毁,但是会重启并重新连接),这些peer将看到完全一样的一系列被分发的(seqno, prevhash, blob)消息。这意味着输出(即deliver()事件)在所有peer和所依据的次序号码上都是以同样的顺序产生的,对于同一个次序号码的消息则必持有同样的内容(指blob和prevhash)。注意这个顺序只是逻辑上的顺序,一个在某一peer上调用的deliver(seqno, prevhash, blob)不要求与在另一个peer上输出同样消息的所调用的deliver(seqno, prevhash, blob)有任何实时关系(即同样一份信息传给所有peer,但是不要求同时传达)。换句话说,给定一个明确的seqno,不存在两个正确的peer(这里的正确是指频道中peer正常连接且身份合法)被分发了不同的prevhash或blob值。此外,只有一些客户端(或peer)真正调用了broadcast(blob),最好是每个blob只广播发送一次,值blob才会被分发。更深的讲,deliver()事件包含了上一次deliver()事件所生数据(prevhash)的加密哈希值(cryptographic hash)。当ordering服务执行原子广播,prevhash是对一个从次序号码是seqno-1的deliver()事件而来的元素加密后的hash值。这由从头到尾的deliver()事件建立了一条hash链,这条链用于帮助检查ordering服务输出的完整性,像稍后的章节4和5讨论的那样。对于第一个deliver()事件这样的特殊情况,prvhash有一个默认值。
- 活性(Liveness)(分发保证):ordering服务的活性保证由ordering服务实施方案来指定。正确的担保可能依靠网络和错误结点模型。首要的就是,如果正在提交交易的客户端(the submitting client)没有失败,ordering服务应该保证每个连接到服务的正确的peer最终分发每一个由客户端提交的交易(这里的peer分发,指的是peer也可以调用broadcast()事件,通过ordering服务向频道中的其他peer进行广播消息)。
总结一下,ordering服务保证如下特性:
- 一致性(Agreement)。对于在正确peer中的任意两个事件deliver(seqno, prevhash0, blob0)和deliver(seqno, prevhash1, blob1),seqno相同,则prevhash0==prevhash1且blob0==blob1。
- 哈希链的完整性(Hashchain integrity)。对于在正确peer中的任意两个事件deliver(seqno-1, prevhash0, blob0)和deliver(seqno, prevhash, blob),prevhash = HASH(seqno-1||prevhash0||blob0)。
- 禁止跳跃(No skipping)。如果ordering服务在一个正确的peer结点p上输出deliver(seqno, prevhash, blob),seqno>0,则p肯定在此之前已经被投递了一个事件deliver(seqno-1, prevhash0, blob0)。
- 禁止创建(No creation)。任一在一个正确peer上的事件deliver(seqno, prevhash, blob)必须以某些(可能很少)peer触发broadcast(blob)事件为先导。
- 禁止重复(No duplication)(可选,但是最好有)。当两个事件deliver(seqno0, prevhash0, blob)和deliver(seqno1, prevhash1, blob’)发生在正确的peer中且blob == blob’,则seqno0==seqno1和prevhash0==prevhash1,则会产生两个(重复的)事件broadcast(blob)和broadcast(blob’)。
- 活性(Liveness)。如果一个正确的客户端调用了broadcast(blob)事件,然后每个正确的peer都会最终(eventually)放出一个事件deliver(*, *, blob),其中*代表任意值。
2.交易背书的基础工作流
接下来我们要为一个交易描绘出高层次的请求工作流。
注意:留意这条协议:不要假定所有的交易都是确定性的,即,允许不确定的交易。
2.1.客户端创建一个交易并发送该交易到交易所选择的背书结点
为了请求一个交易(invocation),客户端发送一个PROPOSE消息到消息所选的背书peer点集合(中的每一位)(可能不是同时-参看章节2.1.2和2.3)。客户端通过peer使用一个给定chaincodID的背书peer点集合,即依次从背书策略(参看章节3)知道整个背书集合(意思是说,peer可以接触背书策略,而背书策略规定了背书者集合,所以说客户端通过peer把PROPOSE发送到该发送的peer中)。例如,交易可能会被发送到全部的给定chaincodeID中的背书者。同时也就是说,一些背书者可能掉线或者反对并拒绝为该交易背书。正在提交交易的客户端则是尝试着用有效的背书者去满足背书策略的表达。
下面我们先详述PROPOSE消息的格式,然后讨论在客户端和背书者之间相互作用的可能的例证。
2.1.1.PROPOSE消息格式
PROPOSE消息的格式为\
2.2.背书peer模拟执行一个交易并进行背书签名
从客户端接收一个\
2.3.客户端(The submitting client)收集交易的背书并通过ordering服务广播该背书
客户端(在发出交易后)会一直等待,直到它收集到“足够(enough)”的消息和在(TRANSACTION-ENDORSED, tid, , )语句上的签名,以得出该交易被背书的结论。如章节2.1.2中讨论的那样,这可能与各个背书者之间触发多次交互的“往返旅行”。
关于“足够”的确切定义,由chaincode的背书策略所决定(参看章节3)。如果满足了背书策略,则就说该交易已经被背书,注意此时该交易还没有提交(committed)。从那些构建了交易是被背书的背书者中而来的签名消息TRANSACTION-ENDORSED的集合(简单说就是,来自于那些认可交易的背书者的签名所形成的集合),被称为一个背书(endorsement,这里是名词),并用背书表示。
如果客户端没有成功收集到交易申请的背书(即收到的背书者的签名不满足背书策略),它会用一个选项(option)抛弃这个交易并稍后再试。
对于拥有有效背书的交易,我们现在开始使用ordering服务。客户端使用broadcast(blob)触发ordering服务,这里blob=endorsement。如果客户端没有直接触发ordering服务的能力,它可以通过选择某个peer去代理它的broadcast。该peer必须是被客户端信任的,信任这个peer不会从背书中删除任何信息或者做其他可能使交易被视为无效的事情。注意,然而,一个代理peer可能不会捏造一个有效背书(同时也就是说可能捏造)。
2.4.ordering服务分发一个交易到各个peer
当一个事件deliver(seqno, prevhash, blob)发生时,一个peer必定已经用一个比seqno小的次序数字为blobs(之前的blob或者说其他的blob)申请了所有状态更新,一个peer做了如下的事:
- 根据chaincode(blob.tran-proposal.chaincodeID指定)的策略检查blob.endorsement是否有效。
典型的情形是,与此同时也确认依赖(blob.endorsement.tran-proposal.readset,读集合)(dependencies,参看章节2.2,也就是版本依赖)仍没有被违背。更复杂的使用情况,背书中的tran-proposal字段可能不一样,在这种情况下,背书策略(参看章节3)规定了状态如何演化。根据为状态更新选择的一致性(或着说“隔离度保证”,isolation guarantee)属性,版本依赖的校验可以用不同的方法实现。可串行性(Serializability)是一个默认的隔离度保证,除非chaincode背书策略指定了一个不同的。要求在readset中与每个key相关联的版本值等于在状态中这些key对应的版本值,并且拒绝那些不满足该要求的交易,这样则能提供所谓的可串行性。
如果这些检查全部通过,这个交易则被视为有效的或可提交的(committed)。这种情形下,peer用PeerLedger的位掩码(bitmask)中的1标记这个交易,应用blob.endorsement.tran-proposal.writeset(写集合)到区域链状态(blockchain state)(如果交易申请是相同的,背书策略逻辑的其他方面定义了相应的使用blob.endorsement的功能)。
- 如果对blob.endorsement的背书策略校验失败,这个交易则是无效的且peer使用PeerLedger的位掩码中的0标记这个交易。重点留意无效的交易是不改变区域链状态的。
注意,用一个给定的次序号处理一个deliver事件(块)后,所有(正确)的peer会拥有相同的状态,(对于交易背书的基础工作流来说)这样就足够了。这就是说,在ordering服务的保证下,所有正确的peer将接收一个deliver(seqno, prevhash, blob)事件的相同次序(也即一个相同次序的deliver事件集)。因为背书策略的测定和readset中的版本依赖的测定是确定的,所以无论包含在一个blob中的交易是否有效,所有正确的peer也将得出相同的结论。自此,所有的peer提交并应用同样顺序的交易,并用同样的方法升级他们的状态。
交易流程图(通用情况下的方式):
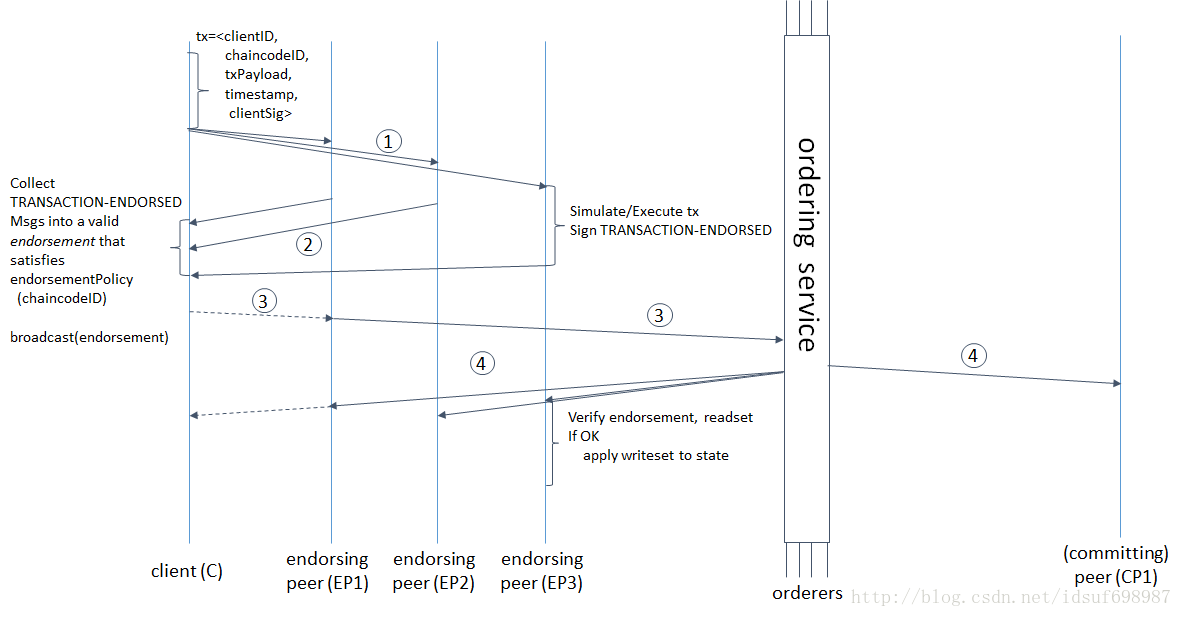
流程图的①②③④与2.1,2.2,2.3,2.4对应。
3.背书策略
3.1.背书策略详细说明
一个背书策略(endorsement policy),是一个如何背书一个交易的条件。区域链的peer拥有一个预定义的背书策略集合,该背书策略与安装指定chaincode的部署交易(deploy transaction)相关。背书策略可以被参数化,这些参数可以通过一个部署交易来指定。
为了保证区域链和安全(security)特性,背书策略集合应该是一个经过验证的由有限的功能(函数)集合组成的策略集合,目的在于确保边界的执行时间(bounded execution time,即可终止),确定性(determinism),执行(performance)和安全担保(security guarantees)。
背书策略的动态添加(如,通过部署交易在chaincode之上部署时间条件)在有限的策略评定时间,决策,执行和安全担保这些项上是非常敏感的。因此,不允许背书策略的动态添加,但是在将来能被支持。
3.2.交易评定(Transaction evaluation)对照背书策略
只有当一个交易已经依据指定的策略被背书,该交易才会被声明为有效的。对于某chaincode的一个请求交易必须先包含一个满足该chaincode策略的背书,否则这个交易不会被提交(committed)。这个发生在客户端和背书peer之间的交互过程中,如章节2解释的那样。
正常的,背书策略是在背书上的声明,潜在的更深的意思就是评定为TRUE或FALSE的状态。对于部署交易,背书根据一个系统范围的策略被包含(例如,从系统的chaincode)。
一个背书策略声明要引用确定的变量。潜在的它可能引用:
- 与这个chaincode相关的key或者身份(identities)(key或身份存在于chaincode中的原始数据),如,一个背书者的集合。
- 更丰富的chaincode原始数据(metadata,一般指配置文件中配置的值或功能源代码之类的)。
- endorsement和endorsement.tran-proposal的元素。
- 更多潜在的。
以上列表按表现力和复杂性的递增排列,也就是说,只引用一个结点的key或身份对于所能支持的策略来说,是相对简单容易些的。
背书策略声明的评定必须是确定性的。一个背书应该由每一个peer在本地评定,如此一个peer就不需要再与其他peer交互了,而且所有正确的peer都使用同样的方法评定背书策略。
3.3. 背书策略示例
声明可能包含逻辑表达式和TRUE或FALSE评定。典型的,条件将使用在由chaincode对应的背书peer讨论的交易请求上的数字签名。
设定chaincode指定的背书者集合E = {Alice, Bob, Charlie, Dave, Eve, Frank, George}。则一些示例策略如下:
- 一个来自所有E成员针对同一个交易请求(tran-proposal)的有效签名。
- 一个来自单独一个E成员的签名。
- 来自根据条件(Alice OR Bob) AND (any two of:Charlie, Dave, Eve, Frank, George)指定的背书peer对同一个交易请求的有效签名。(这里的条件表达式说明:必须有Alic或Bob签名,且同时有四个人中任意两个人的签名)。
- 7个背书者中的任意5个对同一交易请求的有效签名。(一般情况下,chaincode中有n个背书者,n>3f,则只要n个背书者中的任意2f+1个,或者任何一组多于(n+f)/2的背书者同意,则为有效签名)。
- 设定这里把一种赌注或权重的分配给每个背书者,像{Alice=49, Bob=15, Charlie=15, Dave=10, Eve=7, Frank=3, George=1},这里筹码总数是100:策略要求一个拥有占大头儿的赌注集合(即,所有人的赌注加起来严格的大于50)的有效签名。例如{Alice, X},其中X是除George外的任何人,或者{everyone together except Alice}。等等。
- 上一个分配赌注的例子的条件可以是静态的(在chaincode中的原始数据中修改),也可以是动态的(即,依赖于chaincode的状态并在运行期间修改)。
- tran-proposal1上(Alice OR Bob)的有效签名和tran-proposal2上(any two of: Charlie, Dave, Eve, Frank, George)的有效签名,这里tran-proposal1和tran-proposal2仅在指定的背书者和状态升级这两点上不一样。
以上这些策略的有用程度取决于具体的应用、所期望的对抗坏结点解决方案的弹性、和其他多种多样的属性。(这里的坏结点指一个因连接等原因导致连接失败或者故意在背书交易的事情上搞破坏的结点)。
4.(v1后续版本). 验证过的账本和PeerLedger验证节点(正在修改)
4.1.验证过的账本(VLedger)
为了维护一个只包含有效和可提交(committed)交易(例如,这样的特征出现在比特币中)的账本的抽象层,各个peer可能除状态(state)和账本(Ledger)外,还维护一个有效账本(VLedger)。这是一个由过滤掉账本中的无效交易而来的哈希链。也就是说,Ledger是用于记录所有的交易,无论该交易是否有效,只要发生就记录,而VLedger只用于记录发生的有效的交易。
VLedger块(这里称为vblock)的构建过程如下。因为一个PeerLedger的block中可能包含无效交易(即,一个交易拥有无效的背书或无效的版本依赖),这样的交易会在从block变为vblock之前被peer过滤掉。每个peer通过自身做这些工作(即,通过使用与PeerLedger相关的位掩码)。一个vblock被定义为没有无效交易的block,这些无效交易已经被删除。这样的话vblock在大小上天性就是动态的,也可能为空。vblock的构件图如下:
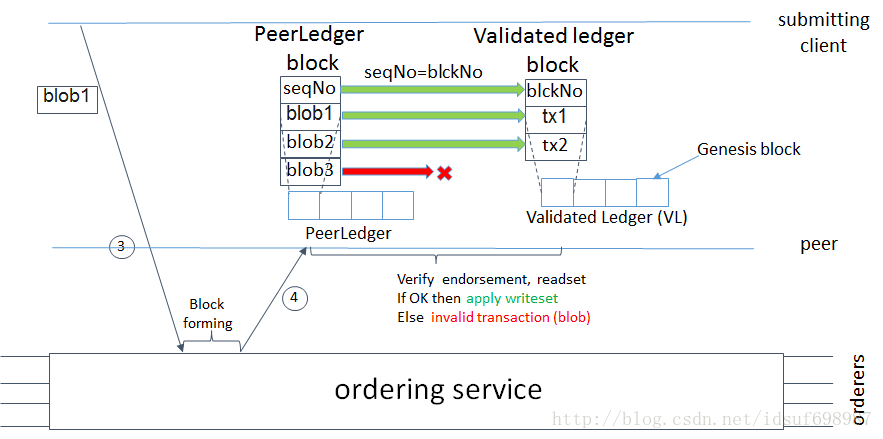
通过每一个peer,一块块vblock被连接在一起,从而形成一个哈希链。更详细点儿,这个验证过的账本中的每一块vblock都包含:
- 前一块vblock的哈希值
- vblock的号码
- 一个所有由peer提交的有效交易按序排列的列表(即,一个相应块中的有效交易列表)。
- 得出这个vblock所对应的block的哈希值
所有这些信息由一个peer连在一起并计算哈希值,产出在VLedger中的vblock的哈希值。
4.2. PeerLedger验证节点
账本包含一些可能永远不需要被记录的无效的交易。然而,peer不能简单的丢弃PeerLedger的block,也因此,一旦peer要建立对应的vblock,它们是去修剪Peerledger。也就是说,在这种情况下,如果一个新的peer加入了网络,其他peer不能传送被丢弃的block给这个新的peer,也不能让这个新的peer信服这些peer的vblock的有效性。
为了帮助修剪PeerLedger,该文档描述了一个验证节点机制(checkpointing mechanism)。这个机制建立了peer网络之间的vblock的校验,并允许检查过的vblock替换被丢弃的block。这样,依次的,减少了内存空间占用,因为不用在去存储无效的交易了。同时也减少了为一个新加入网络的peer重构状态的工作量(因为新加入的peer在通过重演PeerLedger重构状态时不需要去验证个别的交易,而只需重演包含在VLedger中的状态。这里的重演指的是,在为新peer建立state时,需要根据PeerLedger的状态,也就是需要从头到尾过一遍PeerLedger,所以原文用了replay)。
4.2.1.验证节点协议
验证结点周期性的由peer的每个CHK块执行,这里CHK是一个可配置的参数。为了初始化一个验证节点,peer广播(即,gossip)一条消息\
交易流
这部分文档描述了发生在一个标准的财产交换期间的交易机制(transactional mechanics)。“剧本”包含两个客户端,A和B,A买萝卜,B卖萝卜。两者在网络上都有一个peer,通过网络A和B发送交易并与账本交互。
假设
这个流程假设一个channel已经建立并运行。应用的使用者已经注册,已把组织的信任授权(CA)编入清单中并收到必要的用于验证的加密原材料。
一个chaincode(包含一个表示萝卜市场的初始化状态的键值对集合)被安装到两个peer上并在channel上实例化。该chaincode包含的逻辑定义了一个交易指令集合和双方都同意的一个萝卜的价格。一个背书策略也被设置到这个chaincode中,该策略需要满足peerA和peerB同时背书两者之间的任何交易。
1.客户端A初始化一个交易
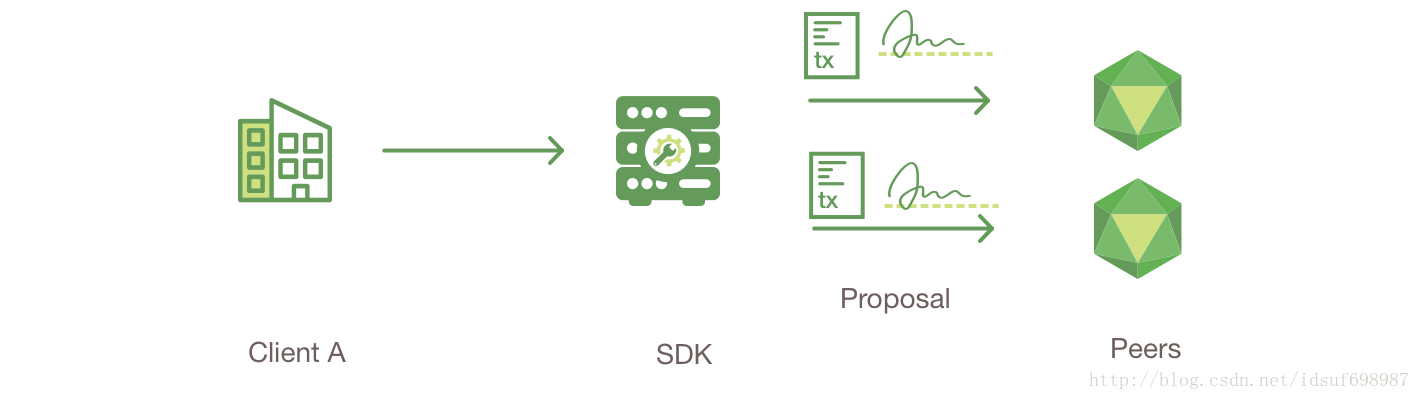
会发生什么呢?客户端A发送一个购买萝卜的请求。该请求(request)把peerA和peerB当作目标,各自对应客户端A和客户端B。背书策略规定了任何交易必须得到两个peer都要签名,因此该请求发送到peerA和peerB。
接着,一个交易申请(transaction proposal)被构建。一个撬动(leveraging)了所支持的SDK(Node, Java, Python)的应用程序(application)利用有效的API生成一个交易申请。该申请是一个触发一个chaincode功能(函数)的请求,如此就可以从账本中读取数据或把数据写到账本中(即,写一个针对财产的新的键值对)。SDK作为一个垫片(shim,相当于一个中间支撑件)把这个交易申请打包成合适的所设计的形式(在grpc上的protocol buffer格式),并使用用户的加密证书(cryptographic credentials)为该交易申请生成一个唯一的签名(signature)。
2.背书peer确认签名&执行交易
背书peer确认的有:(1)交易申请被完好的格式化,(2)之前没有被客户端提交(submitted)过(这是为了replay-attack防御),(3)签名是有效的(使用MSP),(4)提交者(在这个例子中是客户端A)在这个channel上被适当的授权,从而可以执行所计划的操作(即,每个背书peer确保提交者(submitter)满足这个channel的写者策略(Writers policy))。背书peer把这个交易申请的输入(inputs)作为被调用的(invoked)chaincode函数的参数。接着chaincode被执行,依靠当前状态数据库(state database)产生交易结果(transaction results),该交易结果包含一个应答值(response value),读集合(read set),写集合(write set)。至此,还没有对账本进行更新。这些值,与背书peer的签名和一个YES/NO背书语句一起形成一个集合,作为一个申请应答(proposal response)被传送回SDK,该SDK解析这些数据(payload),供应用程序消费(consume)。
{MSP是一个peer的组成部分,该部分确认从客户端到来的交易请求并给交易结果签名(背书)。写者策略在channel创建的时候被定义,决定了哪些peer被提名可以提交一个交易给channel}
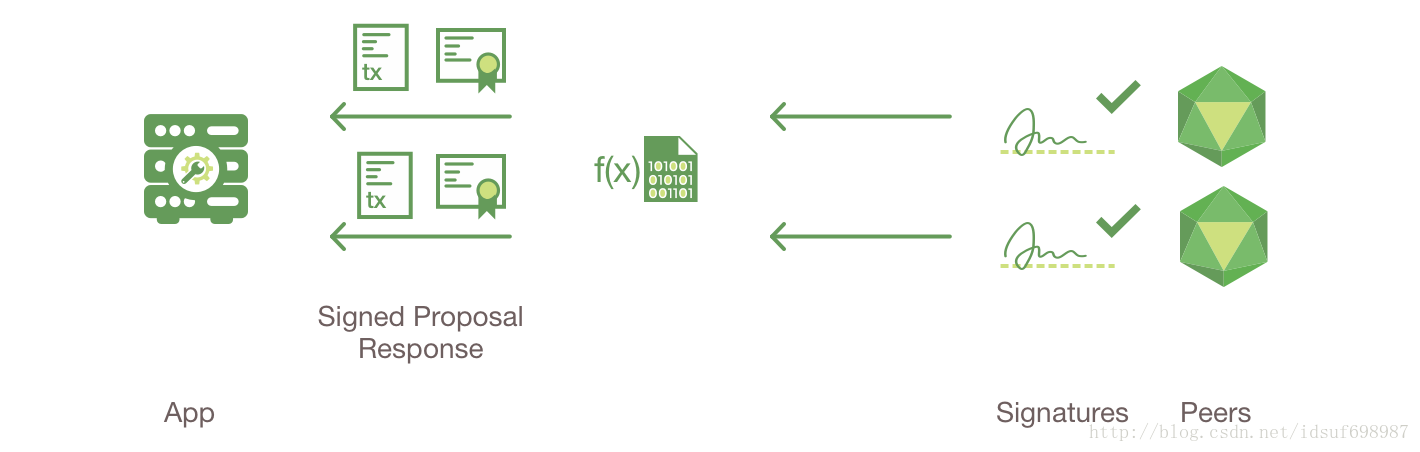
3.检查申请应答
应用程序确认背书peer的签名并对比申请应答(链接到包含申请应答的代表的词汇表,每个申请应答都有一个名字的)去决定申请应答是否一样(这里的一样应该指的是,是否是交易申请对应的那个应答),规定的背书策略是否完全被填写(即,peerA和peerB是否都进行了背书)。这里的设计是,即便一个应用程序选择不去检查应答或者在其他方面转发一个未背书的交易,这个检查也会在提交验证阶段(commit validation phase,即下文的第5步)被peer强制执行。
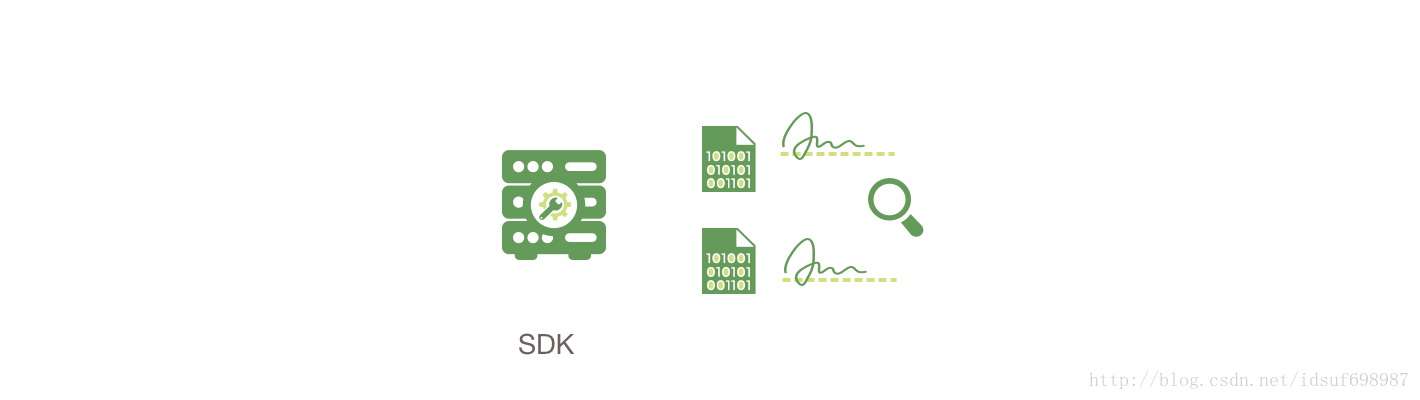
4.客户端将背书组装进一个交易
应用程序将交易请求和应答组装进一个交易消息(transaction message),并将此交易消息广播(broadcast)到ordering服务(Ordering Service)。这个广播交易包含了读写集合,所有背书peer的签名和频道ID(Channel ID)。ordering服务不需要去检查交易的整个内容用以执行内容的操作,而是简单的从网络中所有的channel接收交易,分频道按时间的前后顺序排序这些交易,创建每个channel的交易块(即包含这些交易的块)。
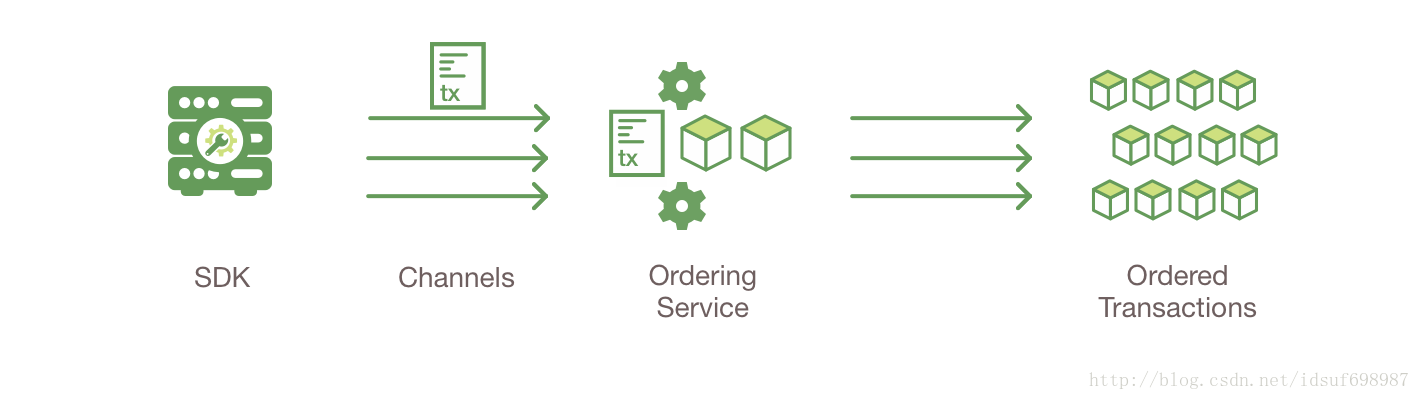
5.交易被校验和提交
这些包含交易的块(block)被分发到channel中所有的peer。每个peer都会验证块中的交易,以确保背书策略被完全填写,确保从交易执行生成读集合(第2步)起到现在,账本状态对于读集合来说没有任何变化(即根据读集合去验证账本状态是否发生变化)。在块中的交易被标记为有效(valid)或者无效(invalid)。
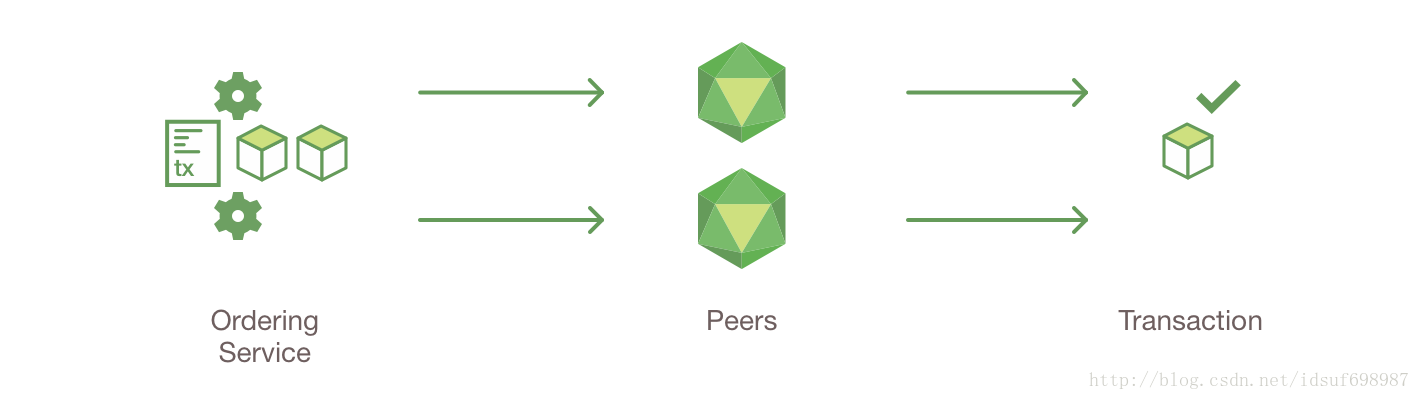
6.账本更新
每个peer把块(block)添加到频道的链(channel’s chain)上,对于每一个有效的交易,其中的写集合被提交到当前的状态数据库(state database,也就是账本)。然后,无论交易是否成功,一个事件被触发,把这个交易(invocation)已经被不可改变的添加到了链上的事实,和该交易是有效还是无效的“通知书”通知给客户端应用。

注意:对照泳道图(即上面每个步骤中所画的UML活动图)可以更好的理解服务端的流和protobuffers。
Hyperledger Fabric SDKs
…
Bringing up a Kafka-based Ordering Service
Caveat emptor
…
Big picture
…
Steps
…
Additional considerations
…
Supported Kafka versions and upgrading
…
Debugging
…
Example
…
频道
…
账本
…
链
…
状态数据库
…
交易流
…
状态数据库选项
…