Preface:算法不够好,需要调试参数时必不可少。比如SVM的惩罚因子C,核函数kernel,gamma参数等,对于不同的数据使用不同的参数,结果效果可能差1-5个点,sklearn为我们提供专门调试参数的函数grid_search。
在sklearn中以API的形式给出介绍。在离线包中函数较多,但常用为GridSearchCV()这个函数。
1.GridSearchCV:
看例子最为容易懂得使用其的方法。
sklearn包中介绍的例子:

卤煮直接从官网上贴上例子:grid_search_digits.py
- from __future__ import print_function
- from sklearn import datasets
- from sklearn.cross_validation import train_test_split
- from sklearn.grid_search import GridSearchCV
- from sklearn.metrics import classification_report
- from sklearn.svm import SVC
- print(__doc__)
- # Loading the Digits dataset
- digits = datasets.load_digits()
- # To apply an classifier on this data, we need to flatten the image, to
- # turn the data in a (samples, feature) matrix:
- n_samples = len(digits.images)
- X = digits.images.reshape((n_samples, -1))
- y = digits.target
- # Split the dataset in two equal parts
- X_train, X_test, y_train, y_test = train_test_split(
- X, y, test_size=0.5, random_state=0)
- # Set the parameters by cross-validation
- tuned_parameters = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4],
- 'C': [1, 10, 100, 1000]},
- {'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]
- scores = ['precision', 'recall']
- for score in scores:
- print("# Tuning hyper-parameters for %s" % score)
- print()
- clf = GridSearchCV(SVC(C=1), tuned_parameters, cv=5,
- scoring='%s_weighted' % score)
- clf.fit(X_train, y_train)
- print("Best parameters set found on development set:")
- print()
- print(clf.best_params_)
- print()
- print("Grid scores on development set:")
- print()
- for params, mean_score, scores in clf.grid_scores_:
- print("%0.3f (+/-%0.03f) for %r"
- % (mean_score, scores.std() * 2, params))
- print()
- print("Detailed classification report:")
- print()
- print("The model is trained on the full development set.")
- print("The scores are computed on the full evaluation set.")
- print()
- y_true, y_pred = y_test, clf.predict(X_test)
- print(classification_report(y_true, y_pred))
- print()


其中,将参数放在列表中
tuned_parameters = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4], 'C': [1, 10, 100, 1000]}, {'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]建立分类器clf时,调用GridSearchCV()函数,将上述参数列表的变量传入函数。并且可传入交叉验证cv参数,设置为5折交叉验证。对训练集训练完成后调用best_params_变量,打印出训练的最佳参数组。
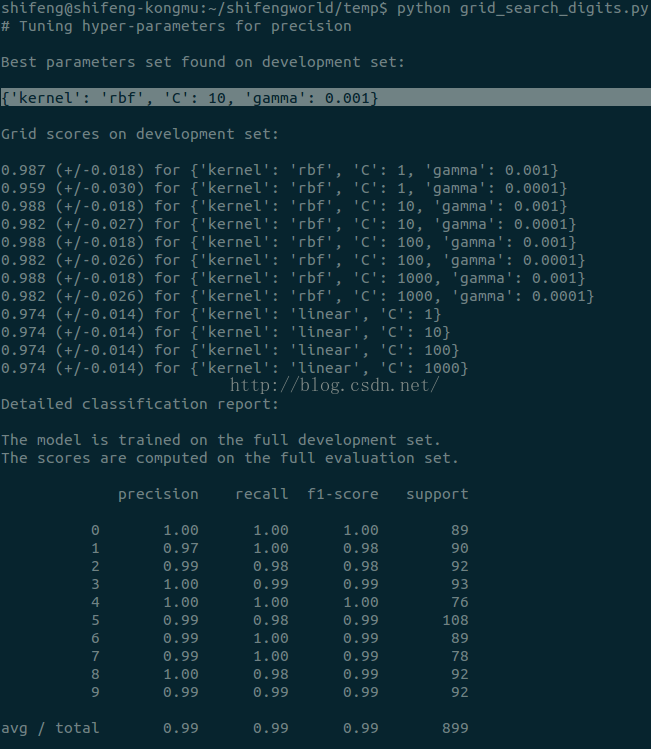
Figure :运行结果
可以看出,其得出最佳参数组字典,还有每一次用参数组进行训练得出的得分。最后在测试集上,给出10个类别的测试报告,对于类别0,RPF都为1,。。。。这里使用sklearn.metrics下的classification_report()函数即可,输入测试集真实的结果和预测的结果即返回每个类别的准确率召回率F值以及宏平均值。
对于SVM分类器,这里只列出线性核和RBF核,其中线性核不必用gamma这个参数,RBF核可用不同惩罚值C和不同的gamma值作为组合。上述列出的结果即可看出有哪些组合。这里的结果是RBF核,惩罚项为10,gamma值为0.001效果最佳。卤煮以为RBF核是比较好的,但是在最近的学习中,确实是不一定,用了线性核效果更好些,但选训练非常慢,数据集不一样效果差很多吧,可能。
另外有个grid_search_text_feature_extraction.py程序写得也很不错,只是卤煮fetch_20newsgroup数据集没有准备好,跑不了