Github:https://github.com/Calamari-OCR/calamari
依赖:
Python3
Tensorflow1.8
图片预处理:
- 灰度图片
- 高度48pix
- 基于OCRopy 对训练图片的每一行进行退缩操作
- 由于LSTM的瞬态效应,每一行的左右各补16个白色的像素
网络结构:
cnn=40:3x3,pool=2x2,cnn=60:3x3,pool=2x2,lstm=200,dropout=0.5
CODEC: ['', ' ', "'", '(', ')', ',', '-', '.', '0', '1', '2', '4', '7', '9', ':', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'K', 'L', 'M', 'N', 'O', 'P', 'R', 'S', 'T', 'U', 'V', 'W', 'Y', 'Z', '[', ']', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']需要注意的是在tensorflow中blank是最后一个label,而在这里的CODEC里面,blank是第一个label。
layers {
filters: 40
kernel_size {
x: 3
y: 3
}
stride {
x: 1
y: 1
}
}
layers {
type: MAX_POOLING
kernel_size {
x: 2
y: 2
}
stride {
x: 2
y: 2
}
}
layers {
filters: 60
kernel_size {
x: 3
y: 3
}
stride {
x: 1
y: 1
}
}
layers {
type: MAX_POOLING
kernel_size {
x: 2
y: 2
}
stride {
x: 2
y: 2
}
}
layers {
type: LSTM
hidden_nodes: 200
}
solver: ADAM_SOLVER
dropout: 0.5
features: 48
classes: 66
backend {
cudnn: true
}
ctc_merge_repeated: true
learning_rate: 0.0010000000474974513评价标准:
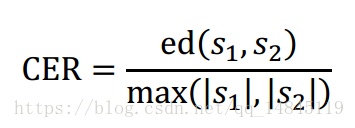
字符错误率CER(Character Error Rate),编辑ed(edit distance )。
整体公式表达了编辑距离和pred和groundtruth中较大值的比值。
CER=0表示所有字符匹配正确,CER=1表示没有字符匹配正确
多模型融合:
论文中作者使用了5折交叉训练,可以分别训练5个模型。然后进行模型融合,基于confidence_voter_default_ctc (default), confidence_voter_fuzzy_ctc, sequence_voter这3种投票方法,输出最终识别结果。
总结:
- CRNN的思路,由于这里的模型只有2个卷积层,比CRNN的网络要小很多,所以使用了模型融合的思想。
- 纯python制作,支持自己训练和测试
- 目前只有识别模块,没有检测模块