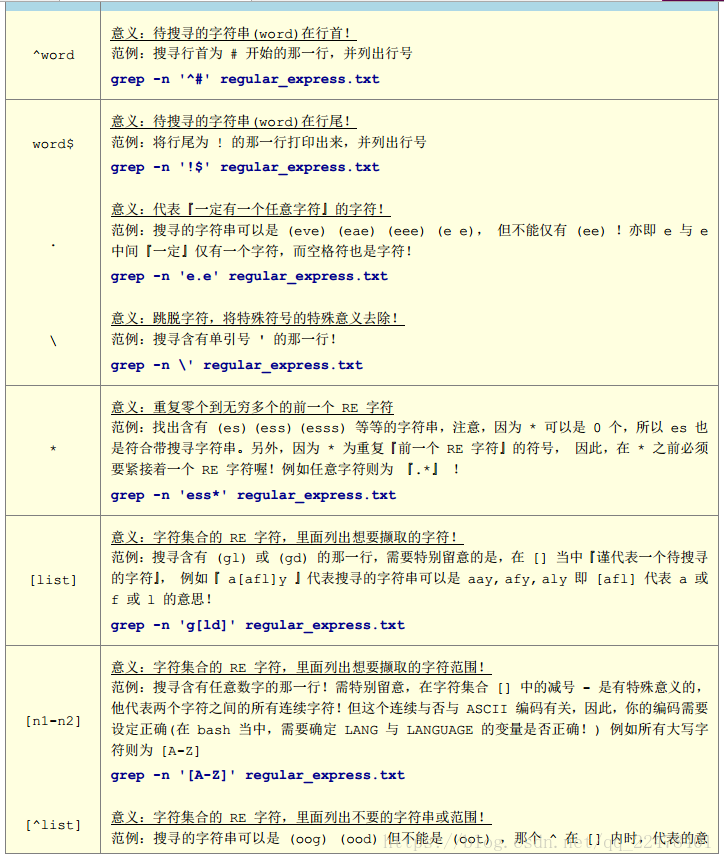
正则表达式:
[:alnum:]:
代表所有英文字母和数字
[:alpha:]
代表所有英文字母
[:blank:]
表示空格和tab按键
[:cntrl:]
代表键盘上的控制按键
[:digit:]
代表所有的数字
[:graph:]
除了空格和tab外其他所有按键
[:lower:]
代表所有小写字母
[:print:]
代表任何可以被打印出来的字符
[:punct:]
代表所有标点符号
[:upper:]
代表所有大写字母
[:space:]
代表所有可能的空白的字符,所有空格键,tab,CR等
[:xdigit:]
代表所有16进位的数字类型,0-9,A-F,a-f
###########################################################################
利用中括号在括号的区间内选择查询字符
grep -n 'th[ea]' text.txt
[^]字集反向选择
^[]表示在文字行首
.&在查询语句的末尾
a-z 查询a-z的字段
[[:digit:]]代表数字查询
############################################################################
通配符
o*
表示0个o或多个o
go*g
可以匹配
gg,gog,goog,gooog
############################################################################
g..g
表示匹配两个.为随机文字
例如goog,gddg,gdeg
######################################################################
g.*g
表示匹配任何符合随机满足g随机任意字符g的文字匹配
#########################################################################
n\{2,5\}
表示n的重复次数为2和5之间文字匹配
#####################################################################

##############################################################################
sed
动作模式
-n: 使用安静模式,在一般sed的用法中,所有stdin的数据都会被输出到屏幕上,加上参数可以值让涉及到的查询结果显示,否则会显示两遍
-e: 直接在指令上进行sed的动作编辑(默认)
-f: 将动作写入一个文件内, 可以使用 -f filename执行sed动作
-r: sed 的动作支持是延伸型正则表达式的语法(默认是常规正则表达式)
-i: 直接修改内容,而不是输出结果(危险操作)
n1,n2,function
在n1和n2之间进行动作行为
动作行为参数
a: 新增,在当前的下一行插入字符串
c: 取代,c的后面可以接字符串,来取代范围内的内容
d: 删除,将范围的内容删除
i: 插入,插入指定行的上一行
p: 将范围内的内容输出到屏幕上
s: 可以用正则表达式对范围内的内容进行查询, 1,30s/oldcontent/newcontent/g
#################################################################
延伸正规表达式
+
一个或一个以上的重复字符
如go+d会匹配
god,good
?
零个或一个的字符
如go?d会匹配
gd,god
|
在给出的条件内查询匹配字符
gd|good
会匹配查询含有两个其中之一关键字的语句
(|)+
范围群组
a(god|good)b
会匹配agodb或者agoodb包含的语句
()+
会包含多个重复就语句的群组
###################################################################
printf
会以区块为边界打印内容,显示格式
\a 发出警告声音
\b 退格键
\f 清除屏幕
\n 换行
\r Enter按键
\t 水平的Tab按键
\v 垂直的tab按键
\xNN NN为两位数的数字,可以转换成字符
%ns n是数字,表示多少字符
%ni n是数字,i表示整数字符
%N.nf n和N都是数字,f表示浮点数,N为总数,n为小数点后的数量,则整数位为N-1-n,小数点占一位
##########################################################################
awk 类似于sed的一种文件数据操作工作
以设定标记位为边界区分每个数据块编号默认为空格
NR表示当前第几行
NF表示当前一共有多少区块
FS表示当前的分隔符
一般格式如下
stdin | awk 'BEGIN{FS=":"} NR > 4 || NF > 3{print $1 $3}'
表示的意思为将输入以":"进行切割,当给定的数据是第4行或者当前分区块数量大于3时,将打印第1区块和第3区块
以/etc/passwd为例子
cat /etc/passwd | awk 'BEGIN{FS=":"}{sum= $3+$4
print "sum=""sum}'
必须进行换行打印,否则会提示语法错误
会将passwd的第3列和第4列的数据加后输出,仅是测试没有意义
###################################################################################
diff
对文件不同进行比较
-b
忽略一行中的空表
-B
忽略空白行
-i:
忽略大小写的不同
##########################################################################
cmp
将文件中的不同字节列举出来
-l
将所有的字节列出来,默认指显示第一个不同点
#########################################################################
patch
将文件的不同以补丁形式保存
diff -naur file.old file.new > update.pacth
在借由patch工具升级
-R
还原
##############################################################################
pr
将文件的标题页码时间连同内容一起显示出来
############################################