在文件夹里创建一个爬虫项目
scrapy startproject ITcast
在spiders目录下:
scrapy genspider itcast
---------------------------------------------------------------------------------------------------------------------------------------------------------------
#items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ItcastItem(scrapy.Item):
# define the fields for your item here like:
#老师姓名
name = scrapy.Field()
#老师职称
title = scrapy.Field()
#老师信息
info = scrapy.Field()# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'#必需参数
#爬取域范围,允许爬虫在这个域名下进行爬取(可选)
allowed_domains = ['http://www.itcast.cn']
#起始url列表,爬虫执行后第一批请求,将从这个列表中获取
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
#在scrapy里,在parse方法外的所有的属性都是初始化的
def parse(self, response):#必须参数
node_list=response.xpath("//div[@class='tea_con']//div[@class='li_txt']")
for node in node_list:
#.extract()将xpath对象转换为Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
print(name[0])
print(title[0])
print(info[0])执行命令:
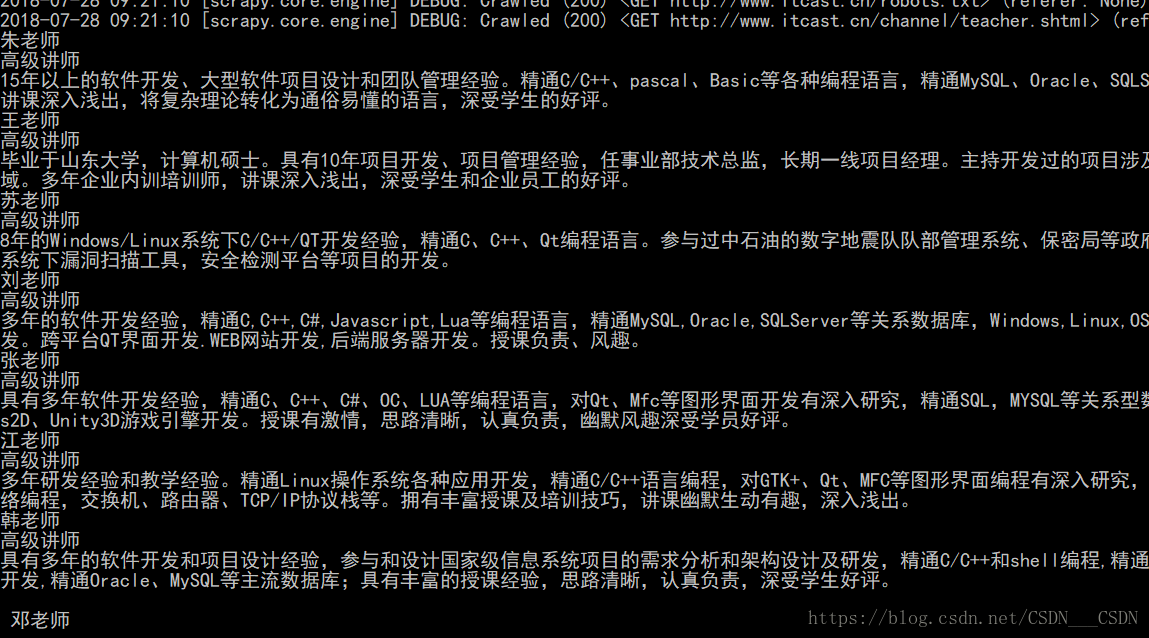
scrapy crawl itcast
就会在cmd窗口中显示老师的信息
我在写这一小段程序的时候,报过两次错误:

1、inconsistent use of tabs and spaces in indentation:
这个报错就是混用了tab和4个空格造成的,检查代码,要不全部用tab,要不全部用4个空格,要特别注意!
2、IndentationError:expected an indented block
Python语言是一款对缩进非常敏感的语言,我就是for循环下面的语句没有缩进,也算是个低级错误。
【尝试一下】在上面的print后面不加“[0]”,则返回的都是列表。
说明xpath返回的是列表,还要把他转化成相应的字符串

在没有使用管道之前,先把它们保存到一个列表里,生成一个itcast.json的文件
#itcast.py
# -*- coding: utf-8 -*-
import scrapy
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'#必需参数
#爬取域范围,允许爬虫在这个域名下进行爬取(可选)
allowed_domains = ['http://www.itcast.cn']
#起始url列表,爬虫执行后第一批请求,将从这个列表中获取
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
#在scrapy里,在parse方法外的所有的属性都是初始化的
def parse(self, response):#必须参数
node_list=response.xpath("//div[@class='tea_con']//div[@class='li_txt']")
items = []
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
#.extract()将xpath对象转换为Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item["name"]=name[0]
item["title"]=title[0]
item["info"]=info[0]
items.append(item)
return items
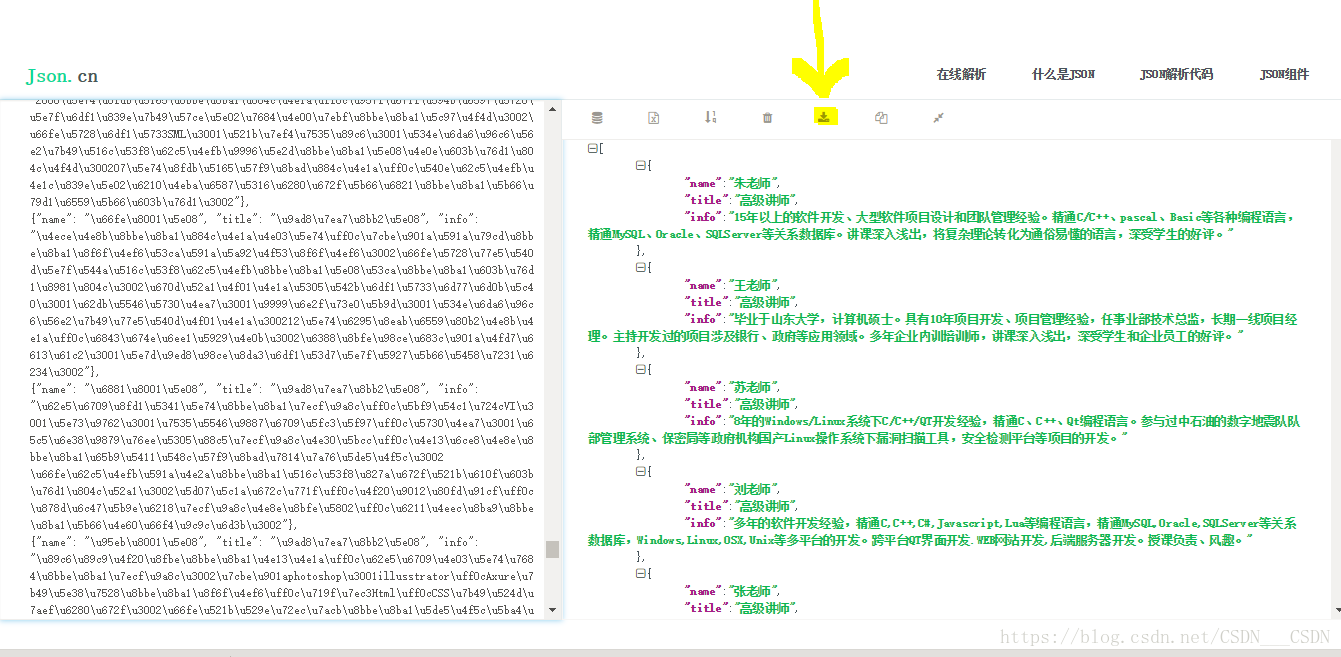
在当前目录下就会生成一个


https://www.json.cn/该网站可以进行解码,点击该键可以进行下载。也可以生成csv文件,按照https://blog.csdn.net/csdn___csdn/article/details/81255003里面的方式进行转码(在用记事本转码的时候貌似直接就是中文,但是还要以utf-8的形式进行另存为,覆盖)。
--------------------------------------------------------------------------------------------------------------------------------------------------------------
下面使用管道
#itcast.py
# -*- coding: utf-8 -*-
import scrapy
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'#必需参数
#爬取域范围,允许爬虫在这个域名下进行爬取(可选)
allowed_domains = ['http://www.itcast.cn']
#起始url列表,爬虫执行后第一批请求,将从这个列表中获取
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
#在scrapy里,在parse方法外的所有的属性都是初始化的
def parse(self, response):#必须参数
node_list=response.xpath("//div[@class='tea_con']//div[@class='li_txt']")
#items = []
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
#.extract()将xpath对象转换为Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item["name"]=name[0]
item["title"]=title[0]
item["info"]=info[0]
#items.append(item)
#返回数据,不经过pipeline
#return items
#将获取的数据交给pipeline,如果一个函数里面有yield,那么这个函数就是一个生成器
#yield返回数据之后,下次再调用函数会从yield暂停那个地方继续往下执行
#然而return再次调用函数的时候,是从头重新执行函数
#返回提取到的每个数据给管道文件处理,同时还会回来继续执行后面的代码(for循环)
yield item#items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ItcastItem(scrapy.Item):
# define the fields for your item here like:
#老师姓名
name = scrapy.Field()
#老师职称
title = scrapy.Field()
#老师信息
info = scrapy.Field()# -*- coding: utf-8 -*-
BOT_NAME = 'ITcast'
SPIDER_MODULES = ['ITcast.spiders']
NEWSPIDER_MODULE = 'ITcast.spiders'
ITEM_PIPELINES = {
'ITcast.pipelines.ItcastPipeline': 300,
}#pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ItcastPipeline(object):
def __init__(self):
self.f = open("itcast_pipeline.json","w",encoding="utf-8")
def process_item(self, item, spider):
content = json.dumps(dict(item),ensure_ascii=False)+",\n"
self.f.write(content)
return item在pipelines里,没有加入encoding="utf-8"的时候,竟然少了一个老师的信息,我从后往前找,还真的找到了,少了一个李老师





和xpath中的结果一样,最后就会在你运行“scrapy crawl itcase”那条命令的路径下生成“itcast_pipeline.json”。