PBFT即实用拜占庭容错算法,由Miguel Castro和Barbara Liskov在1999年提出,可以在作恶节点少于三分之一的情况下,保证系统的正确性(避免分叉)。与原始的BFT算法相比,算法复杂度从指数级降低到了多项式级,从而使得BFT算法的实际应用成为可能。实际上,Tenermint就是PBFT的一个简化版本的实现。
基本概念
首先了解一下几个基本概念:(从区块链的视角)
- replica:即区块链节点,提供“副本复制”服务
- client:向primary发起请求的客户端节点,在区块链中往往跟primary合二为一
- primary:区块发起者,在收到请求后生成新区块并广播
- backup:区块验证者,在收到区块后进行验证,然后广播验证结果进行共识
- view:一个primary和多个backup形成一个view,在该view上对某个区块进行共识
- sequence number(n):由primary指定的一个数字,可以理解为区块高度
- checkpoint:如果某个sequence number对应的区块收到了超过2/3的确认,则称为一个checkpoint
另外,primary是所有节点轮流做的,每个view上都会选出一个新的primary。
三阶段协议
三阶段协议是PBFT的核心,参见下图:
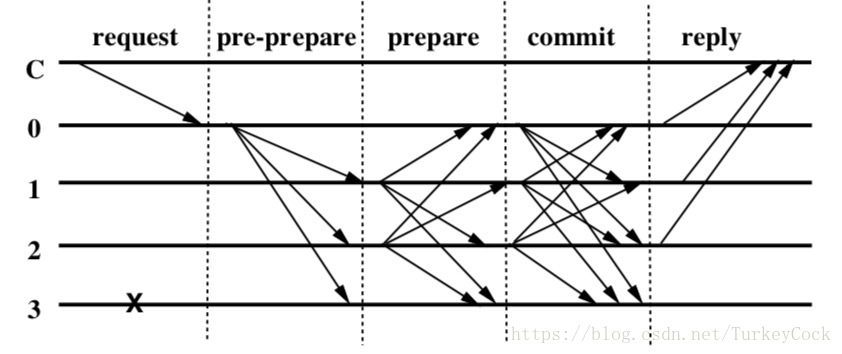
从发起请求到最终收到reply,中间的共识过程需要经过3个阶段:
- pre-prepare:primary收到请求,生成新区块并广播
- prepare:所有replica收到区块后,广播区块验证结果,同时等待接收超过2/3的节点的广播
- commit:收到2/3的节点广播或者超时后,再次发送广播,同时再次等待接收超过2/3的节点的广播
这里的逻辑有点绕:
第一次等待超过2/3的节点广播,是为了确认“已经有超过2/3的节点收到区块了”。但是这只是你自己知道,别人并不知道啊,因此需要再发送一次广播,告诉别的节点“我已经确认有超过2/3的节点收到区块啦”。而第二次等待超过2/3的节点广播,则是为了确认“已经有超过2/3的节点确认(有超过2/3的节点收到区块啦)”,此时说明已经达成共识,可以把该区块写到链上了。
PBFT状态机
这个原文是没有图的,只能根据文字描述自行理解,还是挺复杂的:
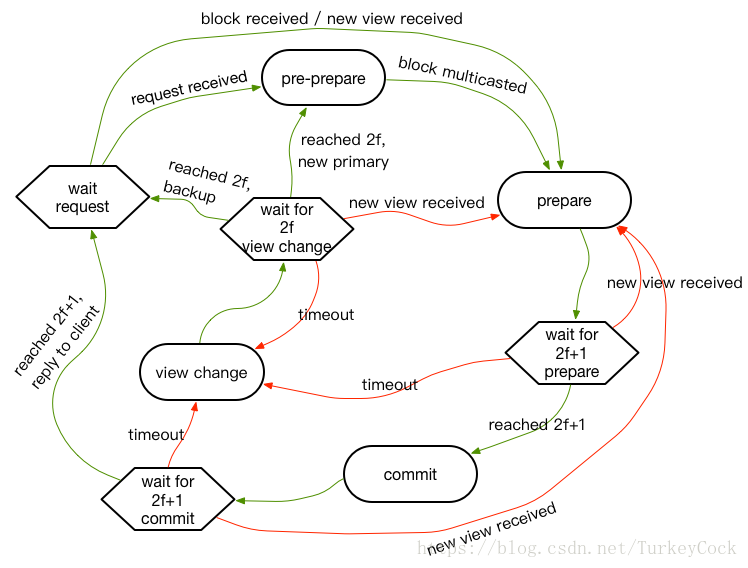
图中的圆角矩形表示状态,六边形表示等待阶段,绿线代表正常流程,红线代表异常流程。下面一个一个的来介绍:
- wait request
- 即等待请求状态,所有节点初始均处于该状态
- primary收到REQUEST消息后,会转换到pre-prepare状态
- backup收到区块后,会转换到prepare状态
- pre-prepare
- 这个状态是primary专属的,primary生成区块并广播PRE-PREPARE消息后,转换到prepare状态
- prepare
- 进入该状态后,广播PREPARE消息,并等待2f+1个节点确认
- wait for 2f+1 prepare
- 如果等到了2f+1个节点确认(accept或reject),转换到commit状态
- 如果超时,转换到view change状态
- commit
- 进入该状态后,广播COMMIT消息,并等待2f+1个节点确认
- wait for 2f+1 commit
- 如果等到了2f+1个节点确认(accept或reject),发送REPLY消息,转换回wait request状态
- 如果超时,转换到view change状态
- view change
- 进入该状态后,广播v+1的VIEW-CHNAGE消息,等待接收2f个节点的VIEW-CHANGE消息
- wait for 2f view change
- 这个状态比较复杂,可以分为以下4种情形:
- 收到了2f个节点的VIEW-CHANGE消息,并且是新的primary,广播NEW-VIEW消息,并转换到pre-prepare状态
- 收到了2f个节点的VIEW-CHANGE消息,并且是backup,转换到wait request状态
- 接收超时,重新回到view change状态,广播v+2的VIEW-CHANGE消息
- 在收到2f个节点的VIEW-CHANGE消息之前,收到了NEW-VIEW消息,则转换到prepare状态
- 这个状态比较复杂,可以分为以下4种情形:
需要注意的是,如果接收到了NEW-VIEW消息,则表示当前view未达成共识,需要在更高层的view上完成共识。因此,不管当前处于哪个阶段,都需要重新回到prepare状态。
数据结构
接下来就是介绍一下相关的数据结构了,主要是状态和消息。
State

节点的状态主要包含三部分:
- 世界状态(即最新区块信息)
- 消息日志
- 当前view
Three Phase Protocol

这里列出了三阶段协议相关的消息结构,其中PRE-PREPARE消息包含新生成的区块,其他消息则主要包含一些id、sequence number、区块内容摘要和签名等信息。
VIEW-CHANGE
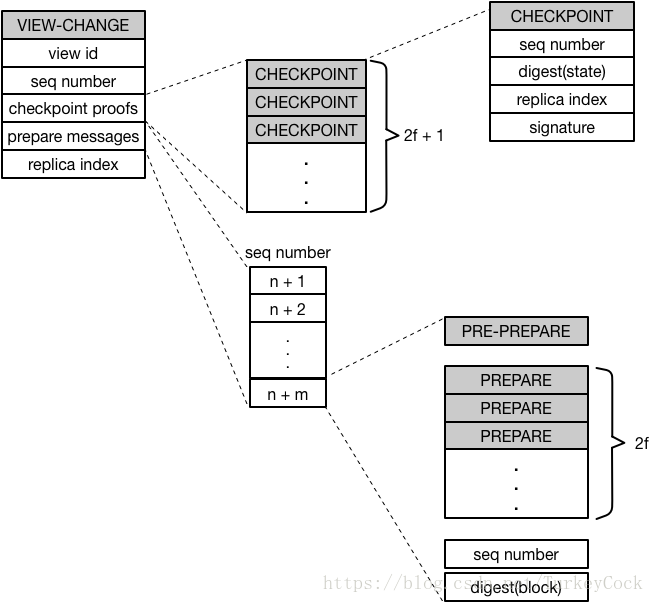
VIEW-CHANGE消息包含的内容比较多:
首先需要基于一个稳定的checkpoint,因此需要包含2f+1个CHECKPOINT消息以证明该checkpoint是有效的。
然后,在该checkpoint之上的所有sequence number,都需要打包对应的PRE-PREPARE消息以及2f个PREPARE消息。
NEW-VIEW
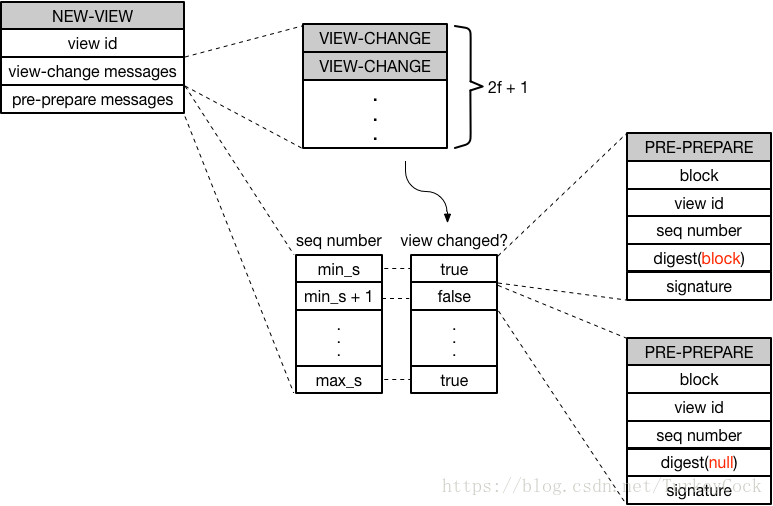
NEW-VIEW消息首先需要包含2f+1个VIEW-CHANGE消息,以证明确实有超过2/3的节点同意在更高的view上进行新一轮共识。
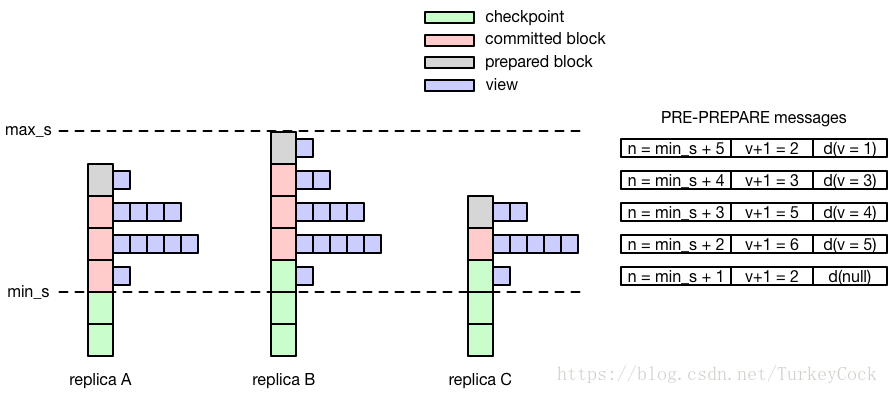
然后,根据收到的所有VIEW-CHANGE消息中的checkpoint信息,找出最小值min_s和最大值max_s,打包该区间内的每一个sequence number对应的PRE-PREPARE消息。
特别的,为了减少重复验证,如果在某个sequence number上从未进行过view change(即第一轮就达成了共识),则PRE-PREPARE中包含一个特殊的null请求的摘要信息。
具体逻辑参见下图:
如果想要了解更多的算法细节,可以阅读论文原文:
http://pmg.csail.mit.edu/papers/osdi99.pdf
更多文章欢迎关注“鑫鑫点灯”专栏:https://blog.csdn.net/turkeycock