1 本章简要记录
“Deep learning methods are representation-learning methods with multiple levels of representation, obtained by composing simple but nonlinear modules that each transform the representation at one level (starting with the raw input) into a representation at a higher, slightly more abstract level. [. . . ] The key aspect of deep learning is that these layers are not designed by human engineers: they are learned from data using a general-purpose learning procedure” – Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, Nature 2015. [9]
“深层学习方法是多层次表示的表示学习方法,由简单但非线性的模块组成,每个模块将一个层次(从原始输入开始)上的表示转换为一个更高、更抽象的层次上的表示。[…]。深层学习的关键在于这些层次不是由人类工程师设计的:它们是通过一个通用的学习程序从数据中学习的。”
AI的中心目标是:提供一系列算法和技术集合,它们能够解决人类可以直觉上或接近自动的执行的问题,但是这些问题对计算机是一个挑战。如理解图片内容问题。
虽然AI包含了与自动机器推理(推理、计划、启发等)有关的大量问题,但是机器学习只与子领域问题:模式识别和从数据中学习感兴趣。
ANN是机器学习的一个子类,专门从数据中学习且专门致力于模式识别,它受大脑的结构和功能启发。深度学习是ANN的一个子集,大多数下,两种术语等价介绍。
2 深度学习历史发展
《神经网络浅讲:从神经元到深度学习》,该文详细讲述了深度学习的历史发展进程,与该系列一的第2章类似,这里将文章地址写在这里,https://blog.csdn.net/chiu1991/article/details/74357828。
第一个神经网络模型是1943年的McCulloch and Pitts模型,该模型手动调整参数。
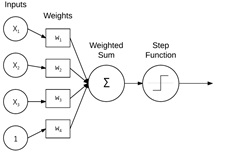
之后,在1950s,Rosenblatt 发表seminal Perceptron algorithm,该模型能够自动学习权重,如图所示,这种自动训练过程构成了(Stochastic Gradient Descent) SGD的基础,在今天SGD仍然被用作深度学习模型的训练方法。
在1969年,Minsky发表了基于感知机的模型不能识别简单的XOR问题,遂进入到了冰河期。

幸运的是,Werbos 、Rumelhart和LeCun 研究了(backpropagation algorithm )BP算法。 BP算法的研究可以训练多层前馈网络,如下图:

结合非线性激活函数,现在可以学习非线性函数且能够解决XOR问题,打开了神经网络研究的大门。进一步研究表明,神经网络是通用逼近器,可以逼近任何连续的函数。
BP算法是现代神经网络的转折。但是由于当时(1)计算性能较低(2)缺乏大量、有标签的训练集,使得不能训练超过两层的神经网络。
现在,神经网络的最新代表是深度学习(deep learning)。深度学习不同于以往的体现是,我们拥有更快、更专业的硬件和更多可用的训练数据。我们现在可以用更多的隐藏层来训练网络,能够进行分层学习,分层学习即在网络的下层学习简单的概念,在上层学习更抽象的模式。
3 层次特征学习
机器学习算法通常分三类:监督、非监督、半监督学习。
监督学习例子中,机器学习算法的输入和目标输出都给定。监督学习类似于老师指导。
非监督学习例子中,机器学习算法试着自动发现差异特征,而不需要输入的任何提示。非监督学习类似于自学。
在机器学习应用到图像分类的例子中,机器学习算法的目标是根据图片集合,识别出模式,该模式可用来区分互相之间不同的图像类别/物体。
过去,我们手动度量一张图片的内容,现在通过深度学习自动度量。对于数据集中的每张图片,我们执行feature extraction或图片处理的过程,通过一些算法度量它(算法称为feature extractor或image descriptor),之后输出能够度量图片内容的向量(例如,一些数字)。如下图所示:

图 通过颜色、质地、形状image descriptor对处方药品的度量
我们手工设计的特征倾向于描述质地、形状、颜色。
其它一些方法,如关键点探测器(FAST, Harris, DoG)和局部不变性描述器(SIFT, SURF, BRIEF, ORB等),描述图像的突出区域(即最感兴趣的区域)。
其它方法,如HOG则对图像物体检测方面擅长。
上述这些应用,都是采用手动度量特定的图像内容。
深度学习,特别是CNNs,采用一种不同的方法。代替从图片中手动设计规则与算法来抽取特征,深度学习从训练过程中自动提取特征。
使用深度学习,我们依据概念的层次学习来理解它。每一个概念都建立在其它概念之上,在网络中的较下层的概念编码问题的基本表示,而高层将使用这些较下层来构建更抽象的概念。这种层次学习允许我们完全移除手动抽取特征过程,而降CNNs作为端到端的学习者。
给定一副图片,我们将像素强度值作为输入传递给CNNs,一系列隐藏层用于抽取输入图像的特征,最后输出层用于对图像进行分类并获得输出类标签。输出层直接或间接受到网络中其他节点的影响。
深度学习和复杂的神经网络的主要好处之一是,它可以让我们跳过特征提取步骤,转而专注于训练我们的网络来学习这些滤波器的过程。然而,正如我们在本书的后面将会发现的那样,在给定的图像数据集下,训练一个网络来获得合理的准确性并不总是一件容易的事情。