爬虫的定义:请求网站并提取数据的自动化程序


put请求的参数会包含在url中,而post则不会

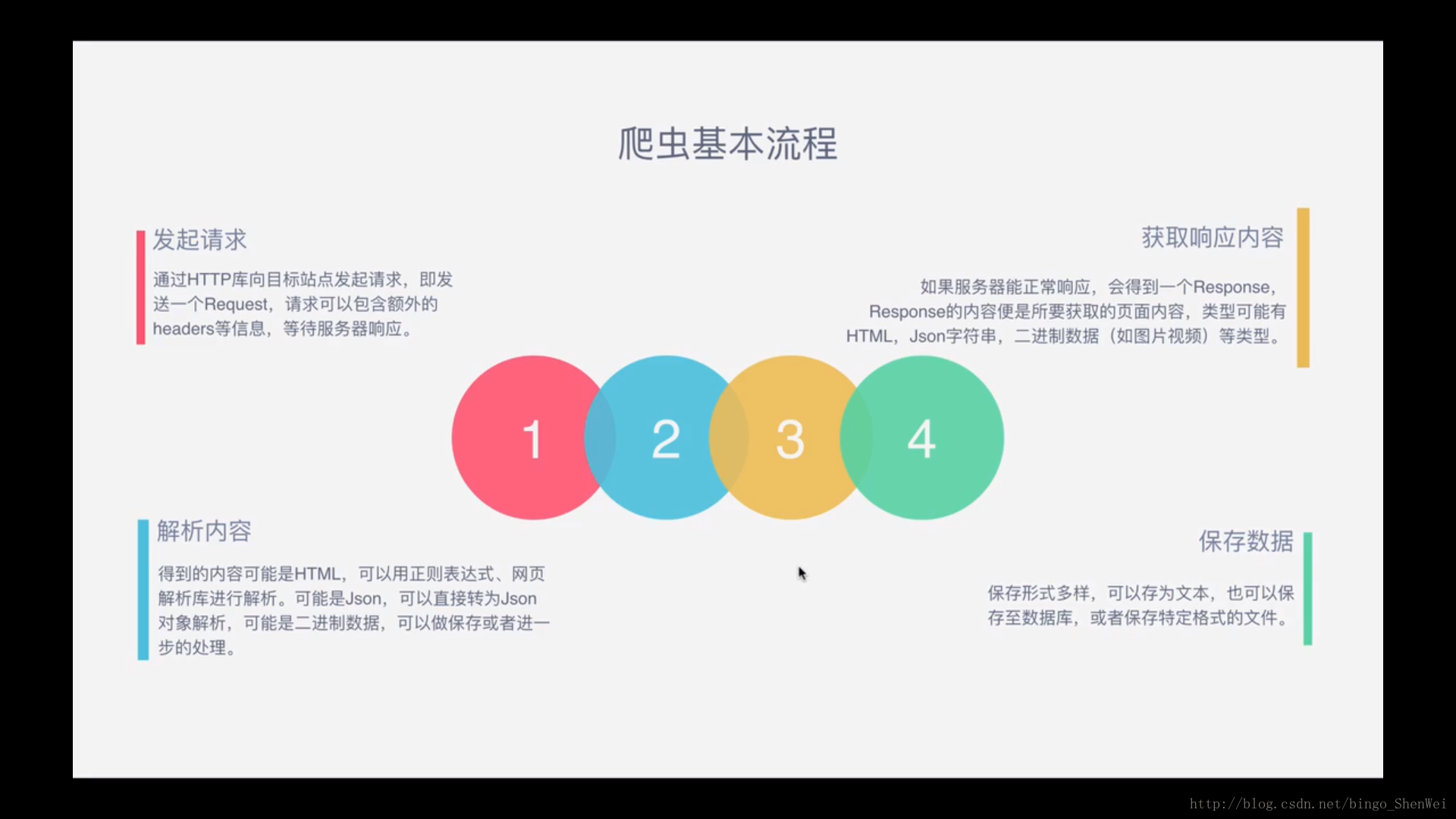
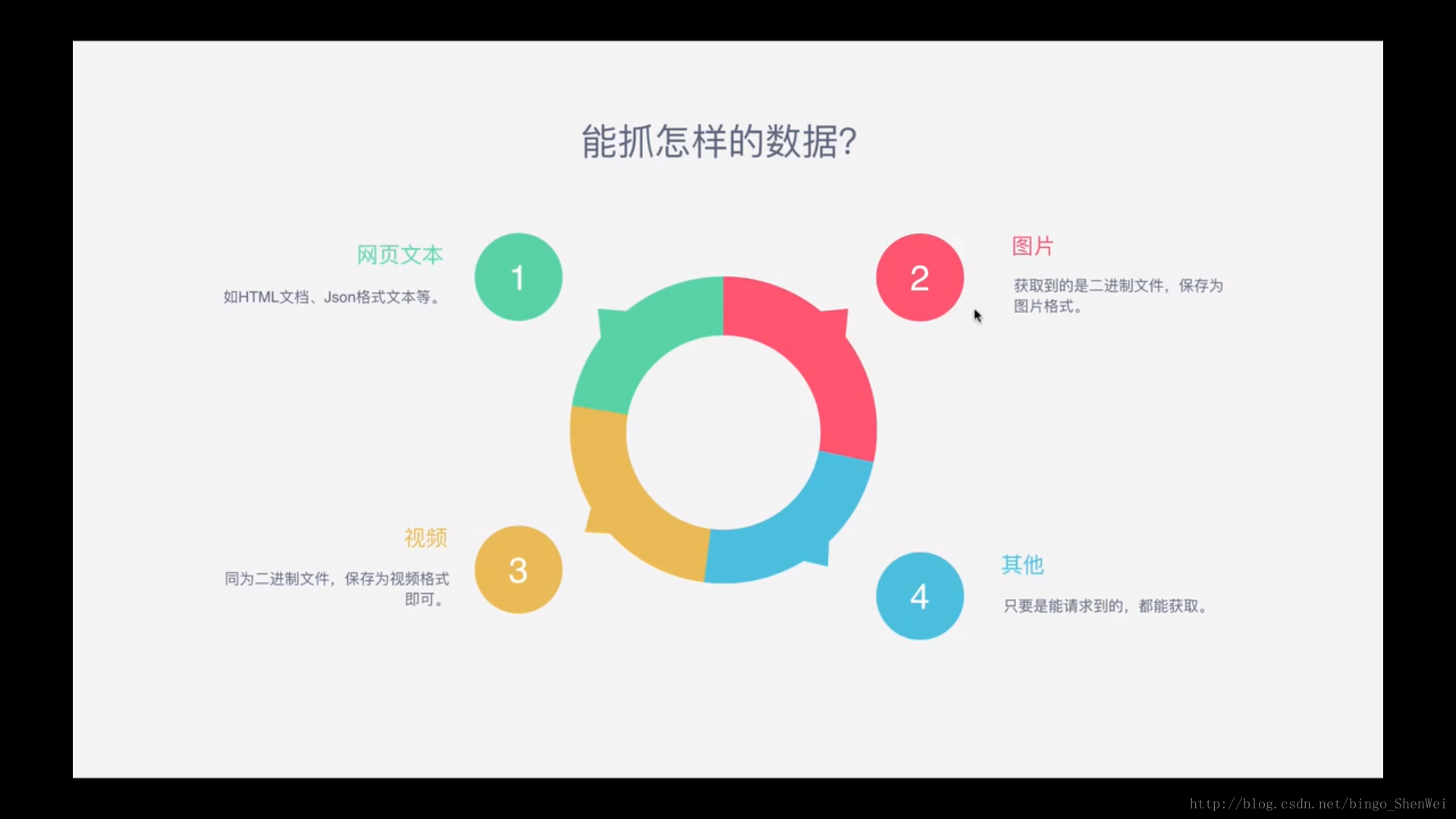
响应体就是源代码.先得到文件的类型,就是源代码,然后在继续请求内置的各种链接,一般都是图片啊,视频之类的.
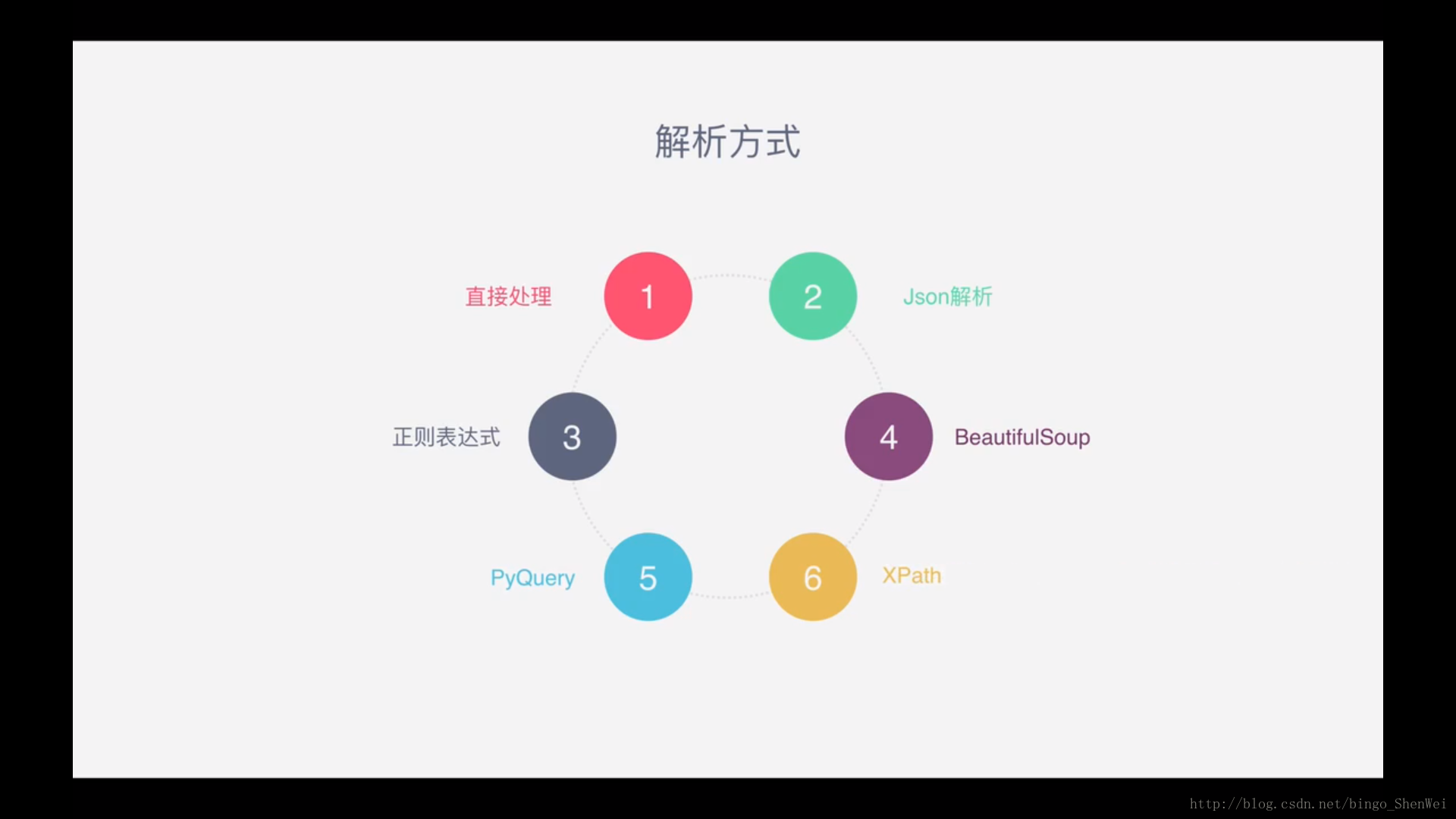
如何来解析?
为什么我们抓到的数据和浏览器中看到的不一样呢?
用库得到的是网页的源代码,而浏览器(elements)中,显示的是经过js渲染的
怎样解决JavaScript渲染的问题?

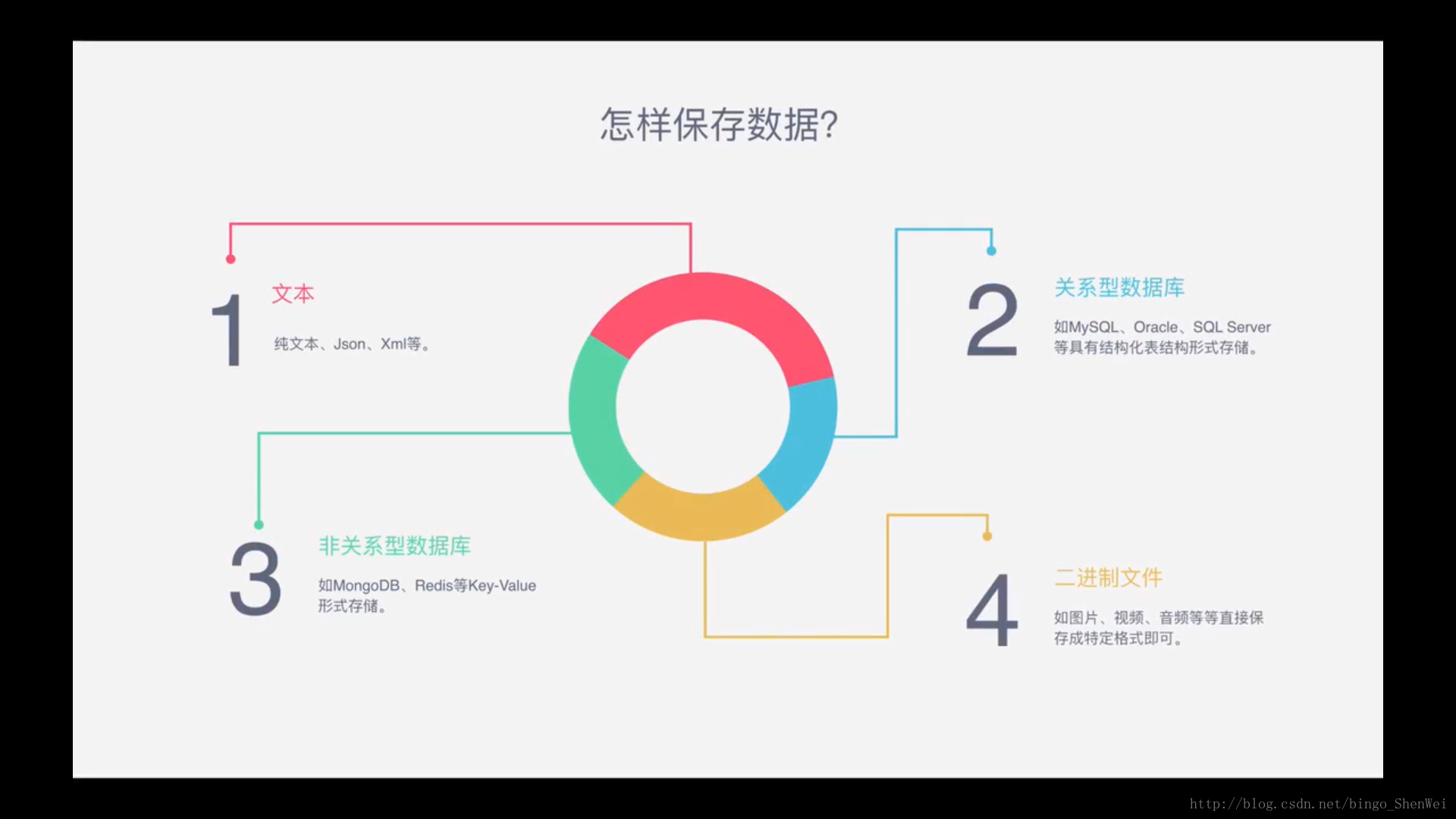
怎样保存数据?
爬虫的定义:请求网站并提取数据的自动化程序
put请求的参数会包含在url中,而post则不会
响应体就是源代码.先得到文件的类型,就是源代码,然后在继续请求内置的各种链接,一般都是图片啊,视频之类的.
如何来解析?
为什么我们抓到的数据和浏览器中看到的不一样呢?
用库得到的是网页的源代码,而浏览器(elements)中,显示的是经过js渲染的
怎样解决JavaScript渲染的问题?
怎样保存数据?