Iterator迭代器
迭代 ==》遍历
什么是迭代器;
- 一个用来遍历集合的对象,该对象实现了Iterator接口。
- 对 collection 进行遍历的迭代器。
- 不能遍历数组
如何获得迭代器对象:
通过集合对象调用该方法:
- Iterator<E> iterator() 获得迭代器对象。
例如:
ArrayList<String> list = new ArrayList<>(); Iterator<String> it = list.iterator();
Iterator接口常用方法:
- boolean hasNext() : 判断是否有下一个元素,有返回true,否则false
- E next() : 先将指针下移指向下一个元素,并将当前指针指向位置的元素作为返回值返回。
- void remove : 删除当前指针元素。
Iterator示例代码:
public class IteratorDemo02 {
public static void main(String[] args){
// 创建集合对象
ArrayList<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
// 使用普通for循环遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐");
// 获得迭代器对象
Iterator<String> it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}如果集合中没有元素可迭代了,仍然调用next方法获得元素,则会抛出异常。
java.util.No such Element Exception:没有元素异常。
迭代器基本使用:
使用循环改进。
迭代器的好处:
- 屏蔽了众多集合的内部实现,对外提供统一的遍历方式。
- 所有的单列集合都可以使用迭代器进行遍历。
迭代器使用的注意事项:
- hasNext方法仅仅是判断是否有下一个元素,不会移动指针位置。
- hasNext方法和next方法必须成对出现,调用一次haxNext就对应一次next方法。
- 使用迭代器遍历集合时不能对集合进行增删操作,否则会抛出异常。
java.util.ConcurrentModificationException: 并发修改异常
在使用迭代器遍历集合的过程中对集合元素进行了增删操作,则会抛出该异常。
注意:
迭代器 只能用一次,若要再遍历一次,则需要再创建一个迭代器。
增强for(foreach)
概述:
- JDK1.5新特性。
- 专门用来遍历集合和数组。
- 数组和单列集合可以直接遍历,双列集合不可以直接遍历。
本质:
迭代器
- 所以里面不能增删。
格式:
for(数据类型 变量名: 数组名或集合名){
// 循环体
}
快捷键:
iter
forEach
用forEach方法遍历集合:
1)单列集合
- List.forEach(new Consum<T>)
2)双列集合
- Map.forEach(new BiConsumer<T,U>)
本质:
Consum与BiConsumer都是接口,实现都是重写他们里面的accept抽象方法。
Consum与BiConsumer的accept方法:
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
}
public interface BiConsumer<T, U> {
/**
* Performs this operation on the given arguments.
*
* @param t the first input argument
* @param u the second input argument
*/
void accept(T t, U u);
}示例代码:
public class LambdaDemo06 {
public static void main(String[] args){
// 创建集合对象
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("凤姐",20,100));
list.add(new Student("如花",22,90));
list.add(new Student("芙蓉姐姐",18,95));
list.add(new Student("小苍",30,70));
// 使用匿名内部类遍历集合
list.forEach(new Consumer<Student>() {
@Override
public void accept(Student student) {
System.out.println(student);
}
});
System.out.println("-----------------");
// 使用lambda标准格式遍历集合
// void accept(T t);
list.forEach((Student student) ->{
System.out.println(student);
});
System.out.println("------------------");
// 使用lambda省略格式遍历集合
// void accept(T t);
Consumer<Student> c = student -> System.out.println(student);
list.forEach(c);
System.out.println("------遍历Set集合------------");
Set<Integer> set = new HashSet<>();
Collections.addAll(set, 2,31,23,13,13,1,3);
set.forEach(num-> System.out.println(num));
System.out.println("------遍历Map集合------------");
Map<String,String> map = new HashMap<>();
map.put("name", "jack");
map.put("gender", "男");
// void accept(T t, U u);
map.forEach((key,value)-> System.out.println(key+"="+value));
}
}泛型
什么是泛型:
数据类型参数化。
伪泛型:
泛型只会存在于编译期,编译完成之后就会被擦除。
- java中都是伪泛型
泛型概述:
- JDK1.5新特性。
- 泛型可以使用在方法上,类上,接口上。
- 泛型变量可以理解为是某种数据类型的占位符。
- 泛型变量还可以理解为是某种数据类型的变量。
- 泛型变量的命名规则:只要是合法的标识符就可以,一般使用一个大写字母表示
- 常用的泛型变量名有:T type E element K key V value
泛型在集合中的使用
泛型在集合中的使用:
- 创建集合同时指定集合存储的数据类型。
- 指定数据类型时,要么指定左边,要么两边都执行相同的数据类型。
- 在JDK1.7之前,必须两边都要指定并且要相同的数据类型。
- 在JDK1.7之后,指定左边即可。
- 在泛型中没有多态的概念。
泛型在集合中使用的好处:
- 将运行时错误转换为编译期错误,增强了集合的安全性。
- 省去了数据类型强制转换的麻烦。
泛型方法
引入:
定义一个方法,方法可以接受任意类型的数据。
概念:
在定义方法时定义了泛型变量的方法就是泛型方法。
定义格式:
修饰符 <T> 返回值类型 方法名(参数列表){}
注意事项:
- 泛型变量的具体数据类型是由调用者调用方法时传参决定。
- 泛型变量的具体数据类型不能是基本数据类型,如果要使用基本数据类型则需要使用对应的包装类类型。
- 包装类类型.valueof(基本数据类型 变量名)
自己的总结:
- 如果参数类型跟返回类型是一样的,则返回类型可以写T。
- 如果参数类型跟返回类型不一样,则必须要写所需要的具体返回值类型。
泛型方法示例代码:
public class Demo01 {
public static void main(String[] args){
Integer in = test(123);
String str = test("abc");
Student stu = test(new Student());
double d = test(0.6);//自动拆箱
int age = 10;//自动拆箱
System.out.println(age);
}
//泛型方法
public static <T> T test(T param){
T a = null;
return a;
}
}泛型类
概念:
在定义类的同时定义了泛型变量的类。
定义格式:
class 类名<T>{
// 在该类中可以将泛型变量T当成一种数据类型使用。
}
注意事项:
- 泛型类泛型变量的具体数据类型是在创建该类对象时由创建者指定。
- 如果创建泛型类对象时没有指定泛型变量的具体数据类型,则默认是Object。
- 静态方法不能使用类上定义的泛型变量,如果该方法中要使用泛型变量,则需要将该定义为泛型方法。
使用场景:
当类中很多方法都使用泛型时,则将类定义为泛型。
泛型类示例代码:
public class MyArrays<T>{
/*
方法参数接收一个任意类型的数组
‐ 一个方法的功能是将数组的元素反转.
*/
public void reverse(T[] arr){
for (int i = 0,j = arr.length ‐ 1; i < j ; i++,j‐‐) {
T temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
public static <T> void reverse02(T[] arr){
for (int i = 0,j = arr.length ‐ 1; i < j ; i++,j‐‐) {
T temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}泛型接口
分层开发:
- 表现层
- 业务层
- 数据访问层:直接和数据库打交道,对数据库直接增删改查操作。
泛型接口的概念:
在定义接口的同时定义了泛型变量的接口。
泛型接口的定义格式:
interface 接口名<T>{
// 可以将泛型变量T当成一种数据类型使用
}
泛型接口的实现方式:
方式1:
实现接口的同时指定泛型变量的具体数据类型。(不够灵活)
- 例:
- public interface Dao<T>{}
- public class ProductDao implements Dao<Product>{}
- ProductDao productDao = new ProductDao();
方式2:
实现接口的时不指定泛型变量的具体数据类型,那么此时需要将该实现类定义为泛型类,由使用者创建实现类对象时指定泛型变量的数据类型。(推荐使用)
- 例:
- public interface Dao<T>{}
- public class BaseDao<T> implements Dao<T> {}
- BaseDao<Product> baseDao02 = new BaseDao<>();
泛型上下限
泛型通配符:
- ? : 泛型通配符,可以匹配任意类型的数据。
- ? 一般不会单独使用,一般会结合泛型的上下限使用。
- ? 不能用来定义泛型方法,泛型类,泛型接口。
- ? 不能在方法体中当成一种数据类型使用、
泛型上限:
- ? extends Number:可以接收Number或Number子类类型的数据。
泛型下限:
- ? super Integer : 可以接收Integer或Integer父类类型的数据。
- 这里的 ? 如果换成 T 或者其他字母(泛型)都可以。
数据结构
java中常见的数据结构:
- 栈
- 队列
- 数组
- 链表
- 红黑树
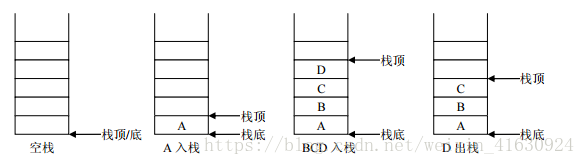
栈
特点:
先进后出(First In Last Out)简称:FILO
结构图:
队列
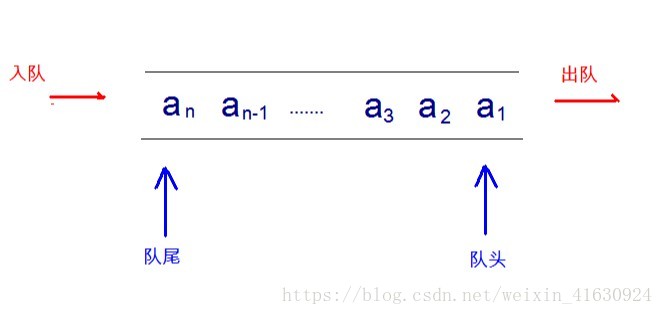
特点:
- 先进先出(First In First Out)简称:FIFO
- 是受限的线性表,入口、出口各一侧。
结构图:
数组
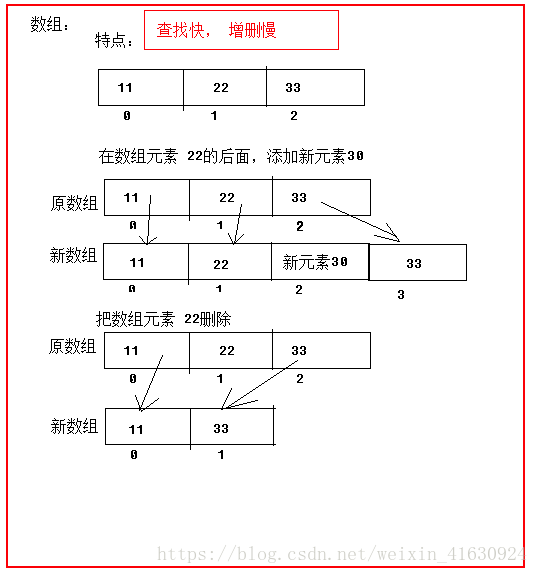
特点:
- 增删慢:每次增删元素时需要创建新的数组,需要复制旧数组的元素到新数组中。
- 查询快:可以根据索引查询指定的元素。
结构图:
链表
类型:
- 单链表
- 双链表
单链表结构图:

双链表结构图:

特点:
- 增删快:每次增删元素时不需要移动元素位置,只需要修改上一个元素记住下一个元素的地址值。
- 查询慢:每次根据索引查询元素时都需要从链表头或链表尾部开始遍历查询。
- 多个结点之间,通过地址进行连接。
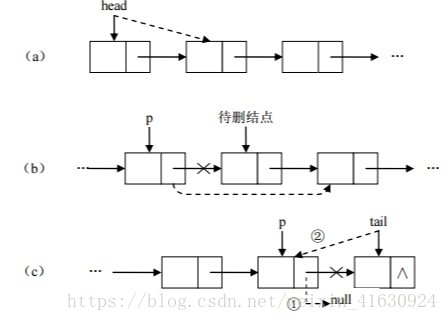
增加结点结构图:
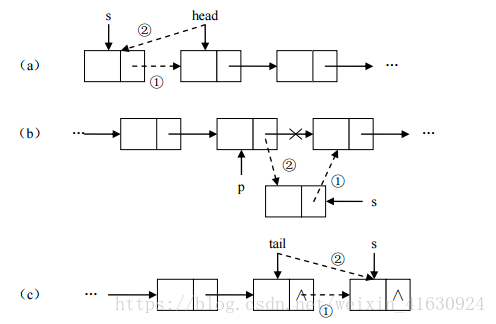
删除结点结构图:
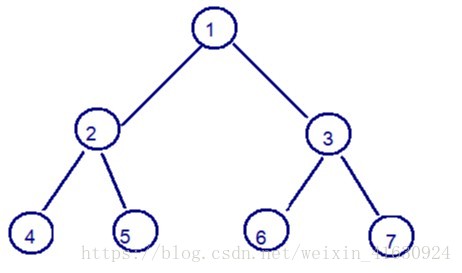
红黑树(了解)
概述:
红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。
二叉树结构图:
对象哈希值
什么是对象哈希值:
- 哈希值就是一个十进制的整数,每一个对象都会有对应的哈希值。
- 哈希值默认是对象在内存中的地址值。
如何获得哈希值:
通过对象调用hashCode方法获得。
哈希值的作用:
哈希值是对象存储到哈希表的重要依据。
字符哈希值小结:
- 字符串内容相同,哈希值一定相同。
- 字符串内容不一样,哈希值也可能相同。
哈希表
什么是哈希表:
- 在JDK1.8之前,哈希表是数组+链表。
- 在JDK1.8之后,哈希表是数组+链表+红黑树。当链表长度大于等于8时,将链表转换为红黑树,目的为了提高查询
效率。
哈希表存储元素,底层依赖元素的:
hashCode 与 equals 方法。
- 所以当存储自定义对象时,如果希望两个对象成员变量值都相同时只存储一个,则需要在自定义类中重写 hashCode 与 equals 方法。
哈希表存储过程
先创建一个容量为16的数组。
- 每存入一个新的元素都要走以下五步
1)调用对象的hashCode()方法,获得要存储元素的哈希值。
2)将哈希值与表的长度(即数组的长度)进行求余运算得到一个整数值,该值就是新元素要存放的位置(即是索引值)。
- 如果索引值对应的位置上没有存储任何元素,则直接将元素存储到该位置上。
- 如果索引值对应的位置上已经存储了元素,则执行第3步。
3)遍历该位置上的所有旧元素,依次比较每个旧元素的哈希值和新元素的哈希值是否相同。
- 如果有哈希值相同的旧元素,则执行第4步。
- 如果没有哈希值相同的旧元素,则执行第5步。
4)比较新元素和旧元素的地址是否相同。
- 如果地址值相同则用新的元素替换老的元素。停止比较。
- 如果地址值不同,则新元素调用equals方法与旧元素比较内容是否相同。
- 如果返回true,用新的元素替换老的元素,停止比较。
- 如果返回false,则回到第3步继续遍历下一个旧元素。
5)说明没有重复,则将新元素存放到该位置上并让新元素记住之前该位置的元素。
哈希表的扩容:
加载因子是0.75,说明哈希表里面的数组有超过4分之3的空格有元素,就会自动扩容,每一次扩大为原来的1.5倍。