#
问题记录
- 问题1
问题的错误信息:
Exception: HTTP 599: Unable to communicate securely with peer: requested domain name does not match the server's certificate.解决的办法:将代码中的基于https开头的地址,切换为http即可。实际的url地址还是https。
- 使用Pyspider过程中的nginx代理
将Nginx的端口直接映射到web服务的端口:
vim /etc/nginx/nginx/conf
文件的内容修改如下:
“`
server {
listen 8080;
server_name localhost;
root /usr/share/nginx/html;
location / {
proxy_pass http://127.0.0.1:5000;
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
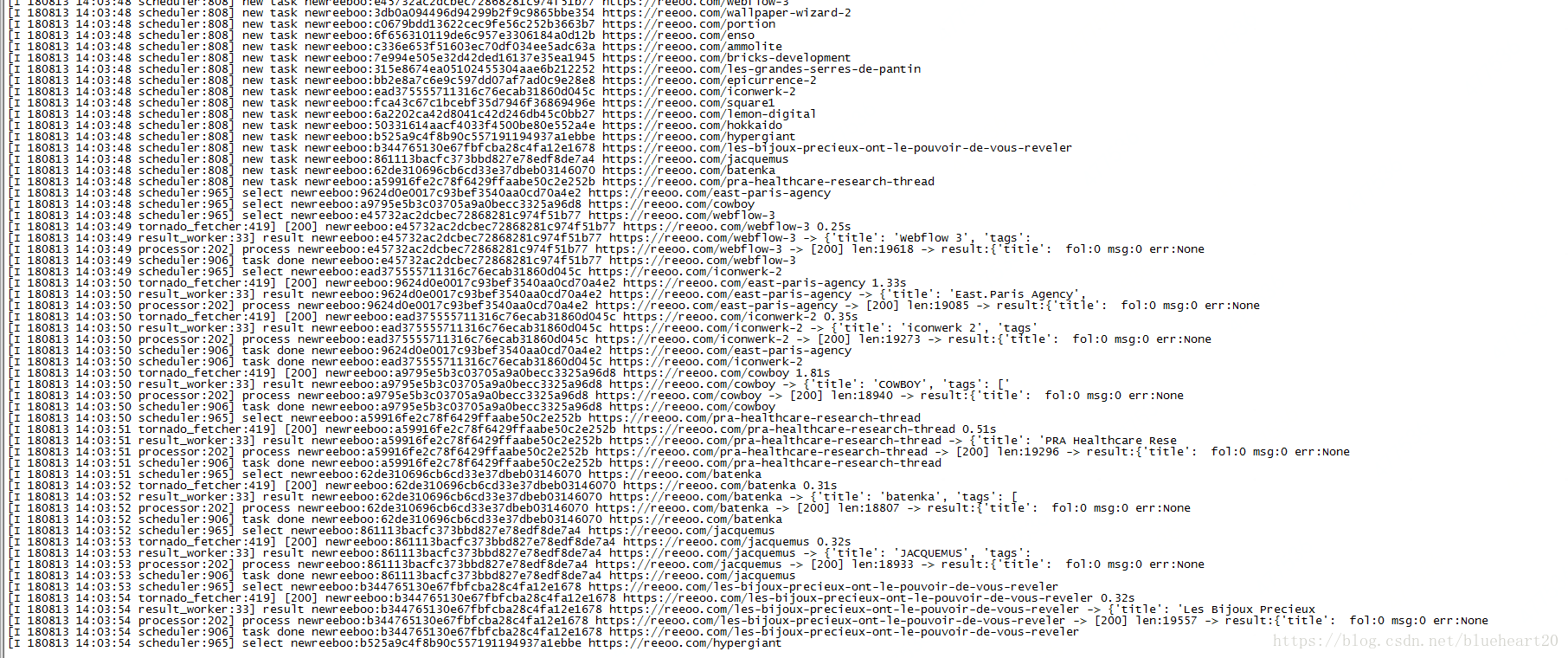
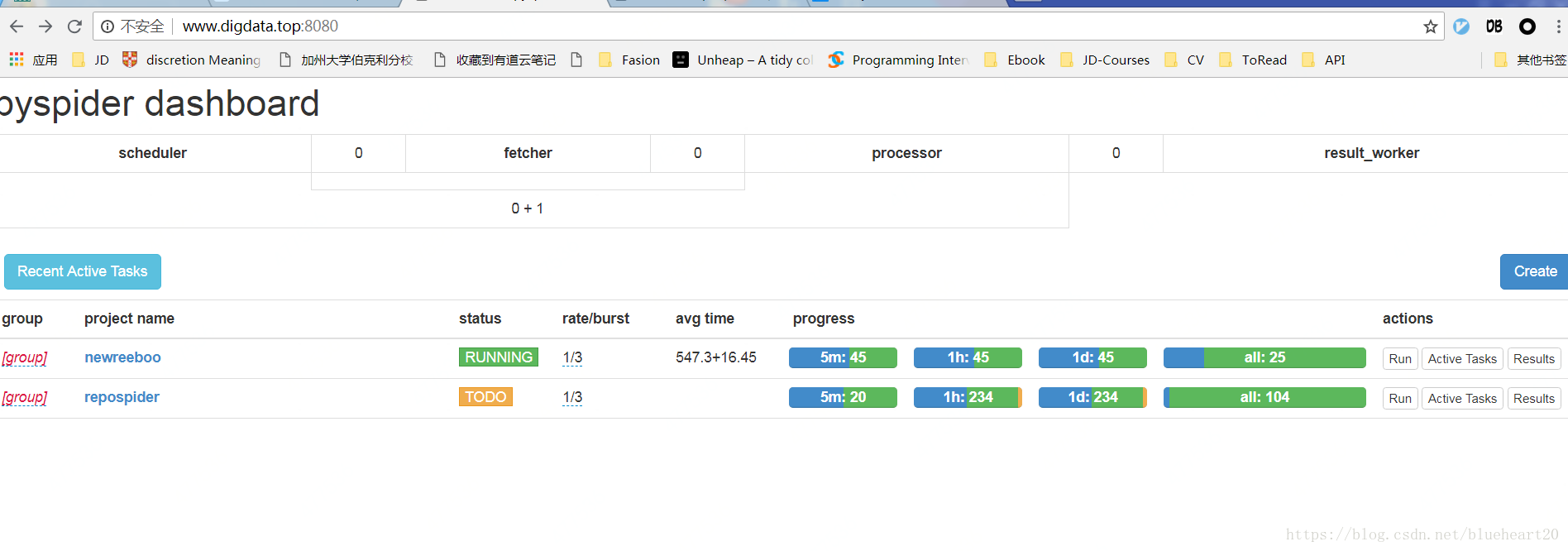
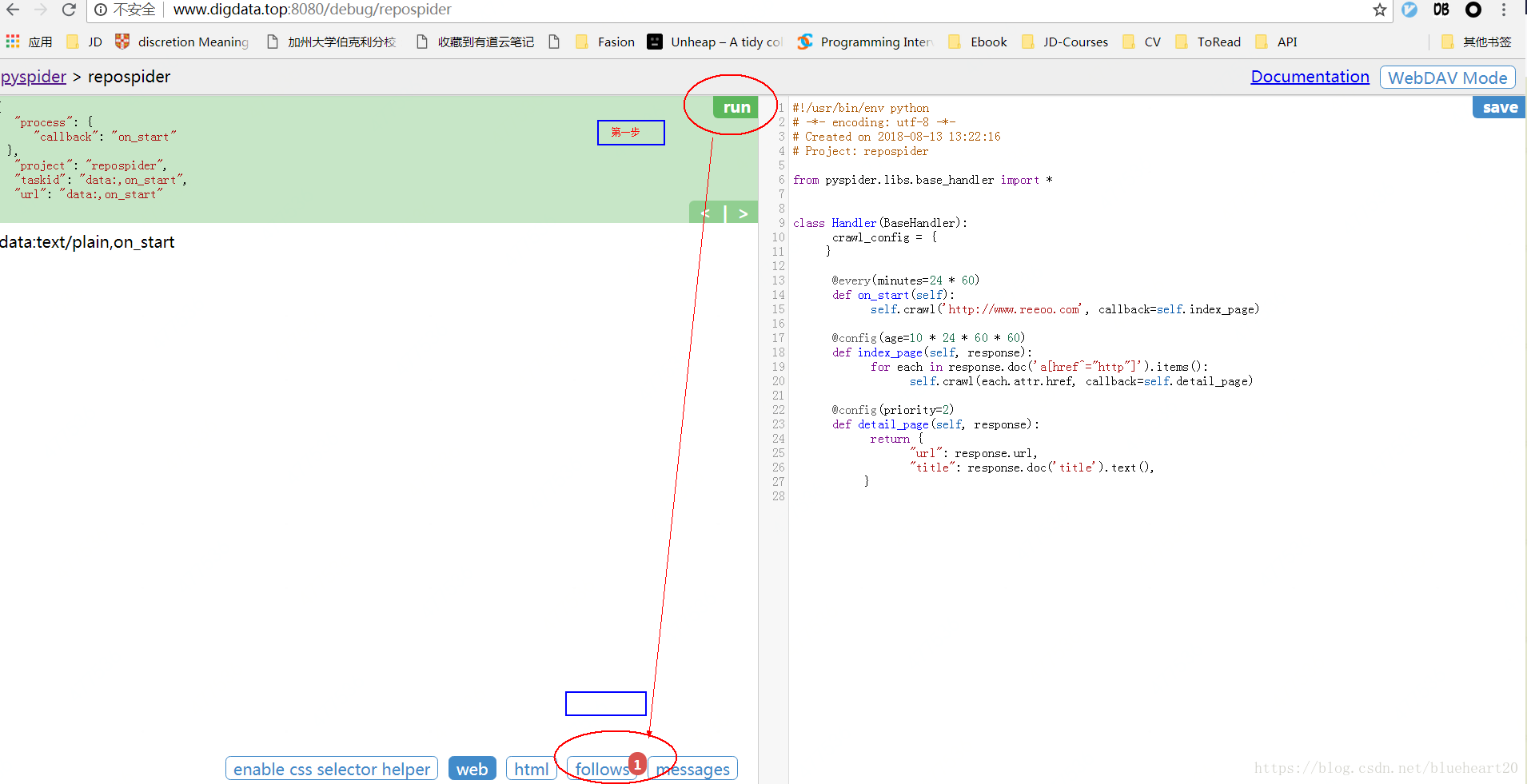
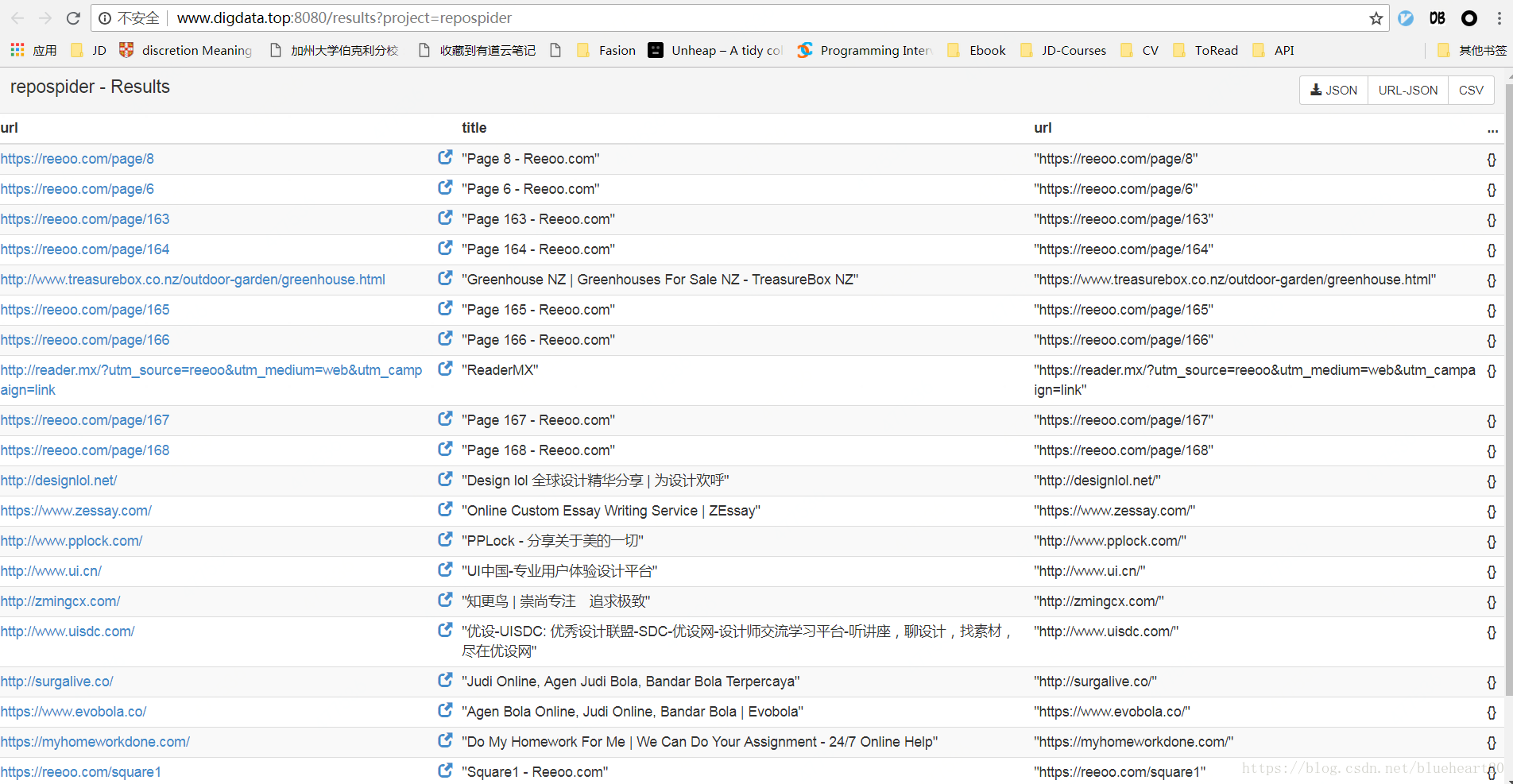
- pyspider中的操作界面截图 Case1
case1:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-08-13 14:05:23
# Project: test
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://reeoo.com/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}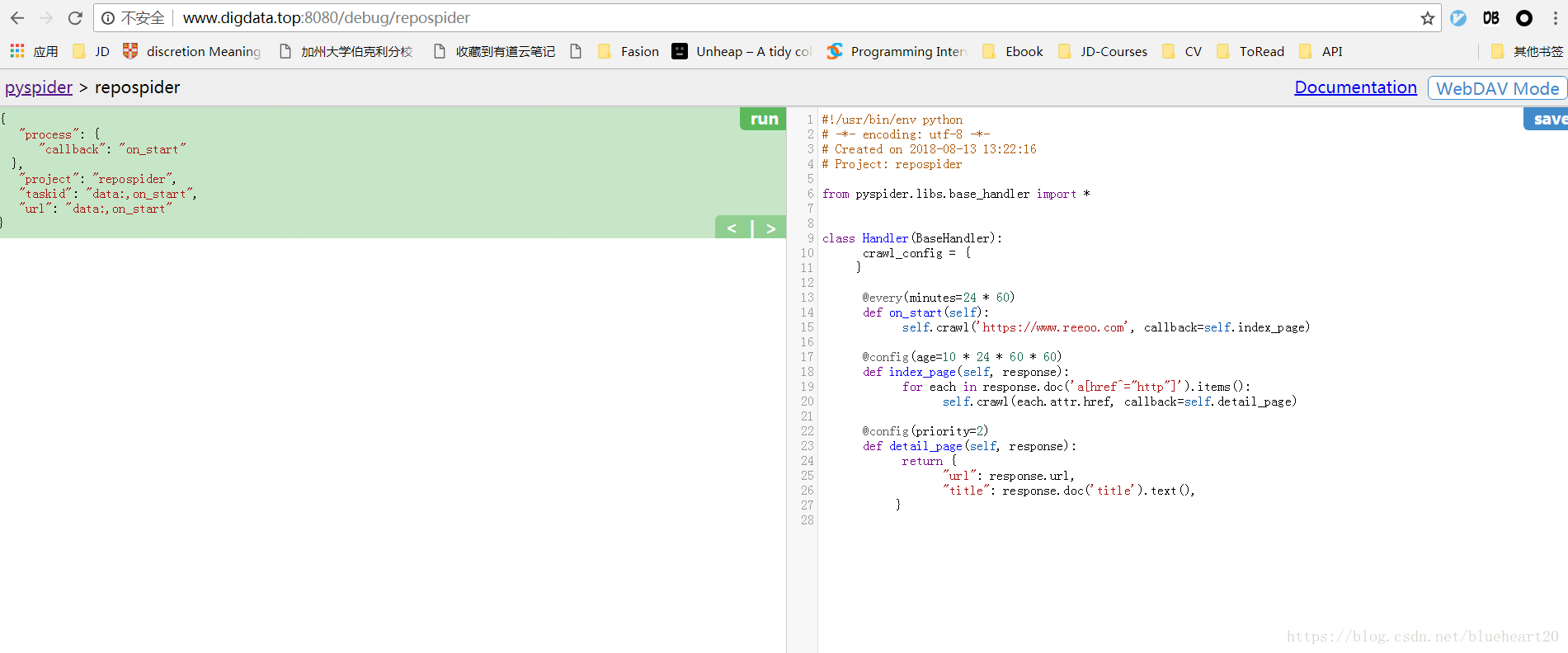
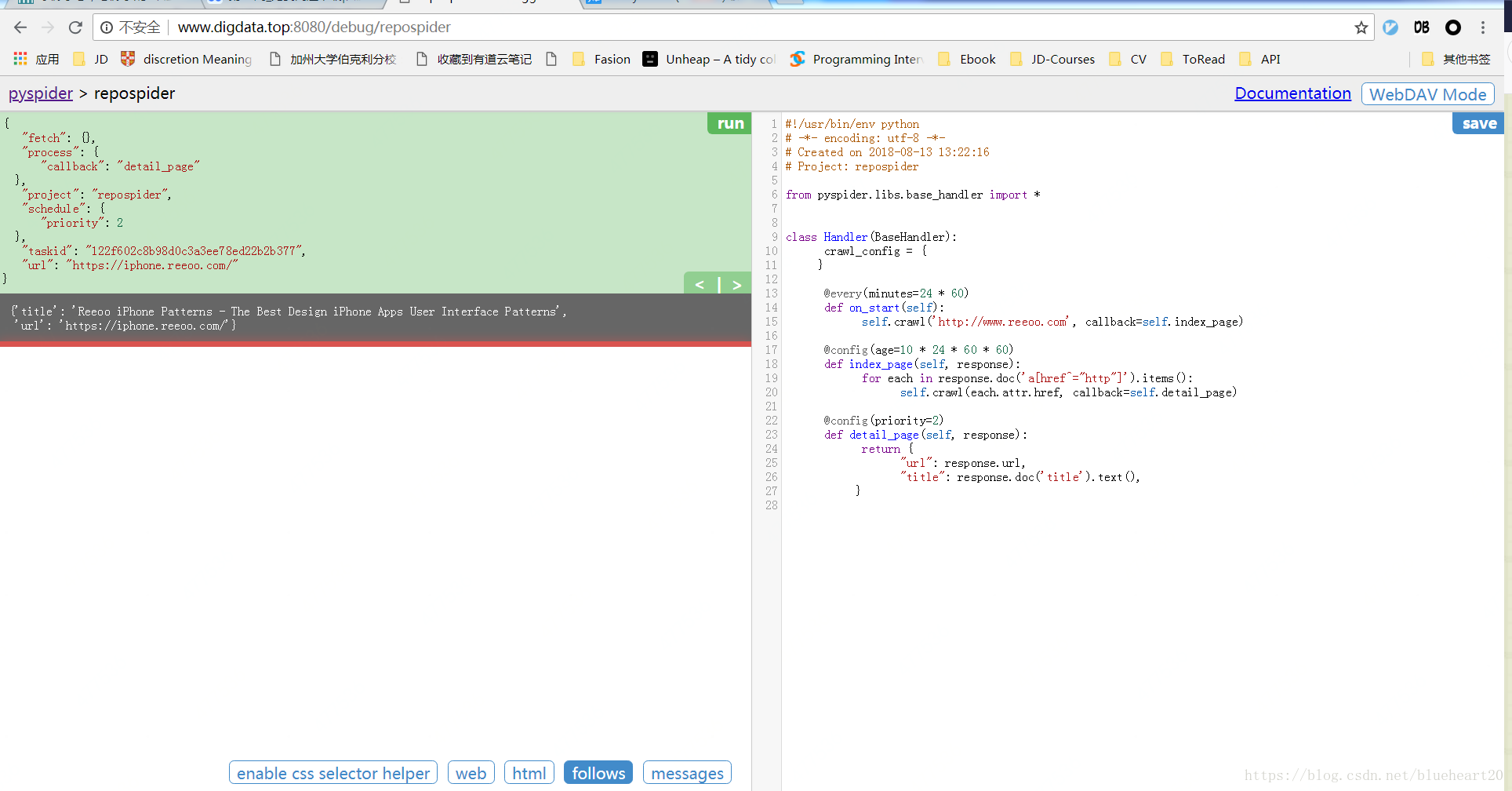
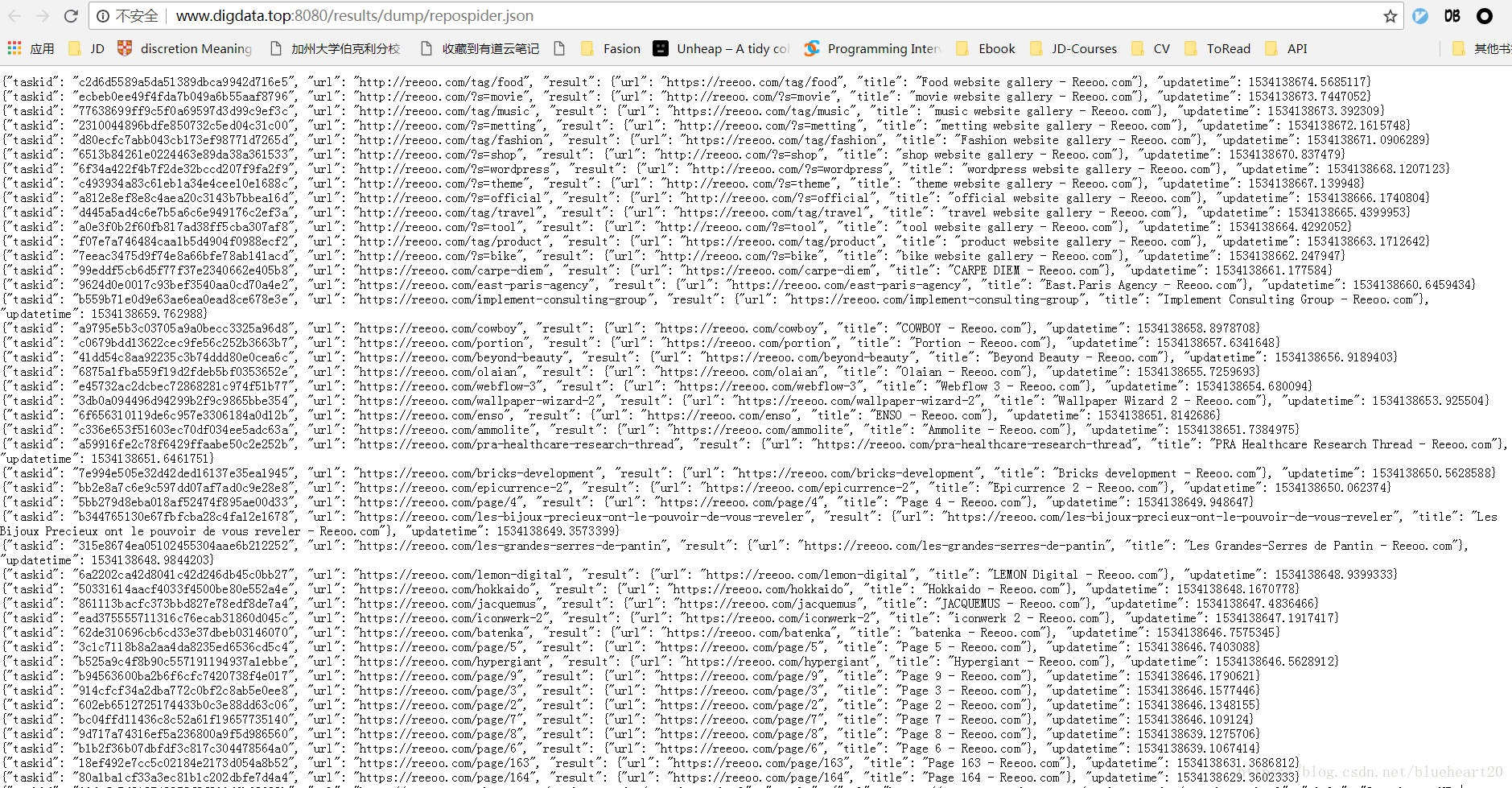
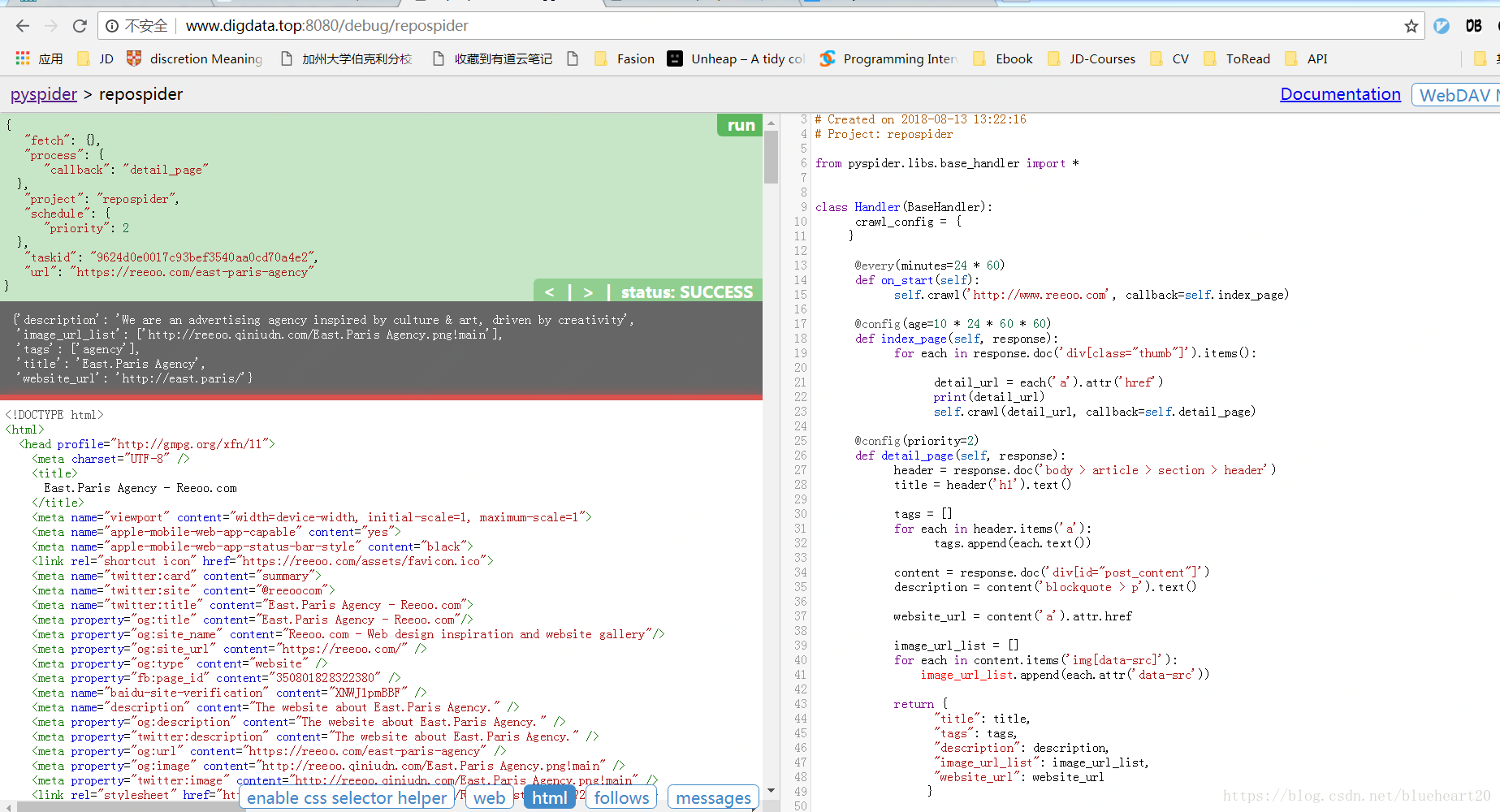
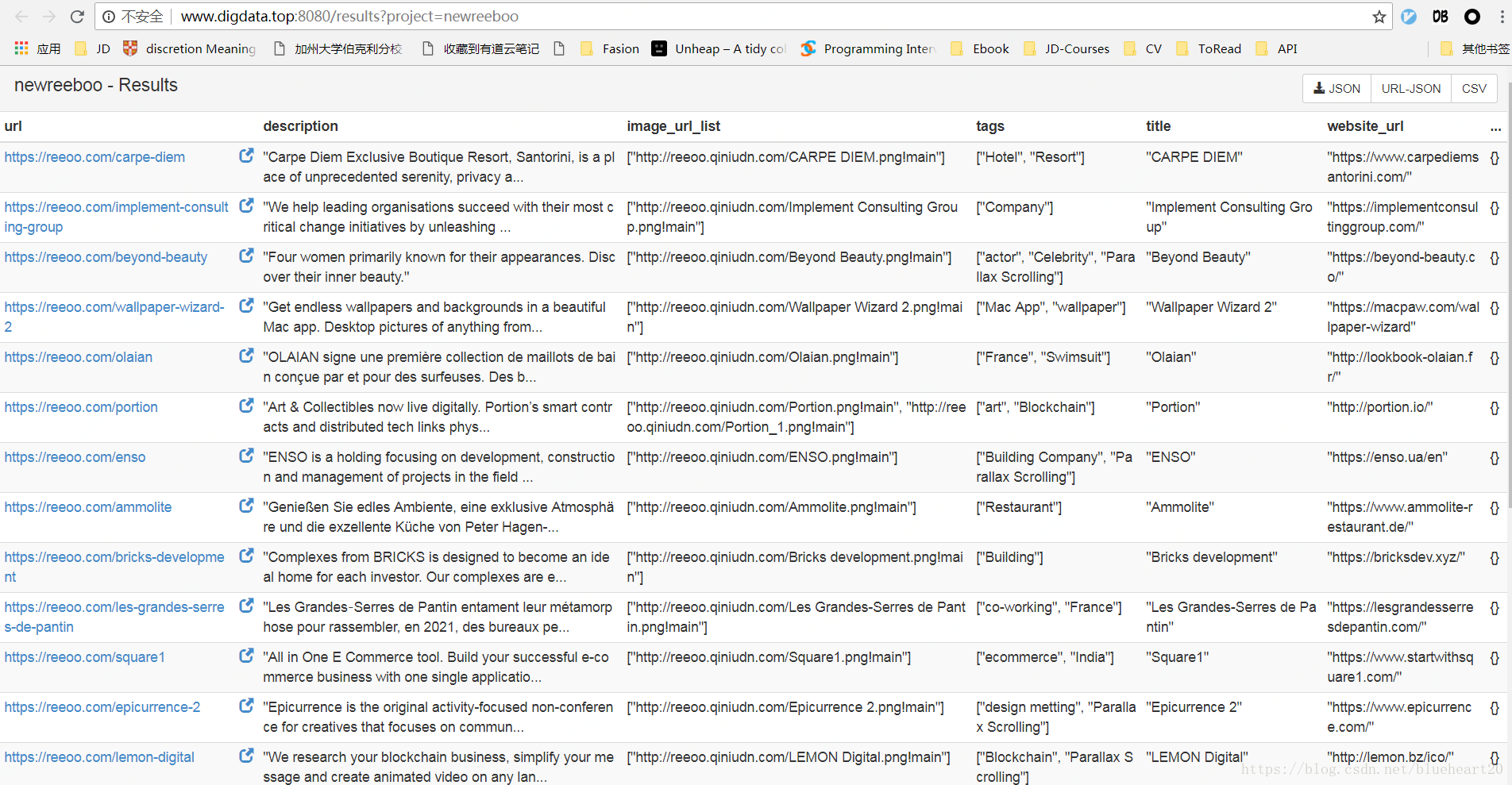
4, pyspider中的操作界面截图 Case2
代码示例如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-08-13 13:22:16
# Project: repospider
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.reeoo.com', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('div[class="thumb"]').items():
detail_url = each('a').attr('href')
print(detail_url)
self.crawl(detail_url, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
header = response.doc('body > article > section > header')
title = header('h1').text()
tags = []
for each in header.items('a'):
tags.append(each.text())
content = response.doc('div[id="post_content"]')
description = content('blockquote > p').text()
website_url = content('a').attr.href
image_url_list = []
for each in content.items('img[data-src]'):
image_url_list.append(each.attr('data-src'))
return {
"title": title,
"tags": tags,
"description": description,
"image_url_list": image_url_list,
"website_url": website_url
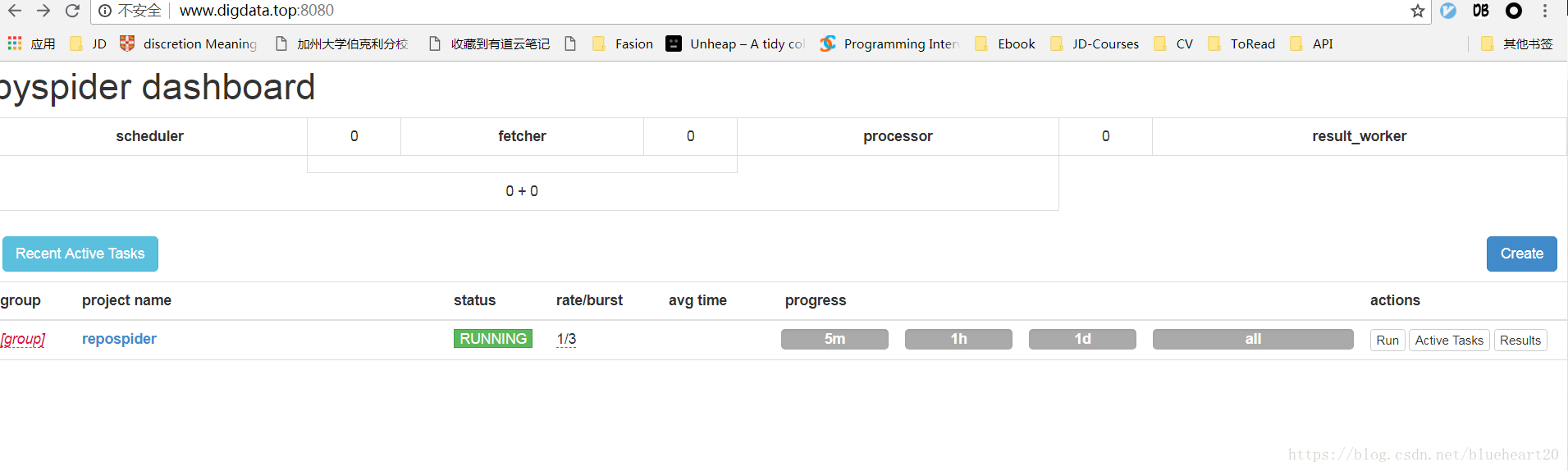
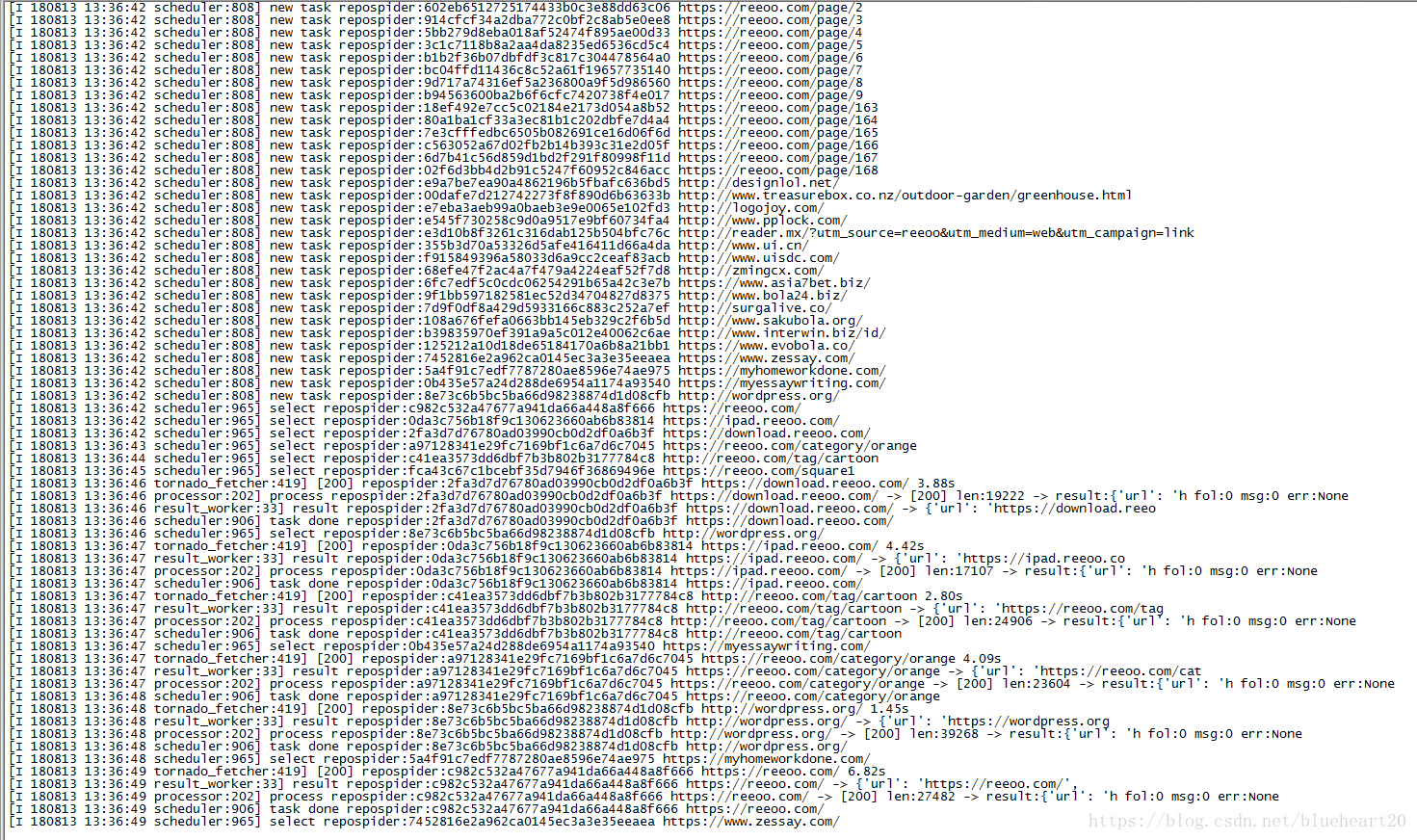
}运行的界面截图: