本文参与「少数派读书笔记征文活动」https://sspai.com/post/45653
参考文章:https://www.cnblogs.com/PandaBamboo/p/3261646.html
组合数据类型
1.集合类型
- 多个元素的无序组合,元素之间无序,且每个元素唯一,集合元素不可更改
- 集合用{}表示,元素间用逗号隔开
- 建立集合类型用{}或set()
- 建立空集合必须用set(),set()最多只能包含一个参数
A={"python",123,("python",123)}->{123,'python',('python',123)} #顺序不确定(本就为无序数据类型)
B=set("pypy123") ->{'1','p','2','3','y'} #顺序不确定
备注:非可变类型(整数,浮点数,复数,字符串等)
- 集合间操作:并/差/交/补(操作后均返回一个新集合)
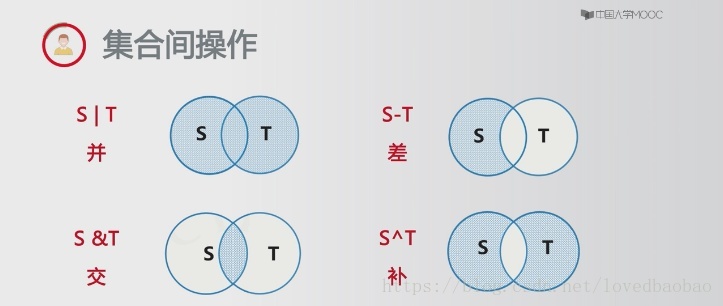
补充(操作符):
| 操作符及应用 | 描述 |
| S<=T或S<T | 返回True或False,判断S和T的子集关系 |
| S>=T或S>T | 返回True或False,判断S和T的包含关系 |
"p" in {"p","y",123}
{"p","y"} >={"p","y",123}->True
->False
补充(增强操作符):
| 操作符及应用 | 描述 |
| S | =T | 更新集合S,包含在集合S和T中的所有元素 |
| S - =T | 更新集合S,包含在集合S但不在T中的元素 |
| S & =T | 更新集合S,包含同时在集合S和T中的元素 |
| S ^ =T | 更新集合S,包含集合S和T中的非相同元素 |
A={"p","y",123}
B=set("pypy123")
print(A-B)
print(B-A)
print(B&A)
print(A|B)
print(A^B) #在A中也在B中,但不是他们共有的->{123}
->{'2','3','1'}
->{'p','y'}
->{'1','p','2','3','y',123}
->{'2','3',123,'1'}
- 集合处理方法(增加、删除、清空、取出、个数、拷贝、判断、转换)
| 操作函数或方法 | 描述 |
| S.add(x) | 如果x不在集合S中,将x增加到S |
| S.discard(x) | 移除S中元素x,如果x不在集合S中,不报错 |
| S.remove(x) | 移除S中元素x,如果x不在集合S中,产生KeyError异常 |
| S.clear() | 移除S中所有元素 |
| S.pop() | 随机返回S的一个元素,更新S,若S为空产生KeyError异常 |
| S.copy() | 返回集合S的一个副本 |
| len(S) | 返回集合S的元素个数 |
| x in S | 判断S中元素x(True/False) |
| x not in S | 判断S中元素x(True/False) |
| set(x) | 将其他类型变量x变为集合类型 |
# TestSet
A = {'p', 'y', 123}
try:
while True:
print(A.pop(), end="") # 当A集合中元素取完,产生异常,退出无限循环
except:
pass # 不做任何事情,一般用做占位语句,保持程序结构的完整性
print("\n{}".format(A))
->123py
->set()
数据去重:
ls=["p","p","y","y",123]
s=set(ls) #将列表转换为结合集合,利用了集合无重复元素的特点
print(s)->{'y','p',123}
lt=list(s) #再将集合类型转变回列表类型
print(lt)->['y','p',123]
2.序列类型
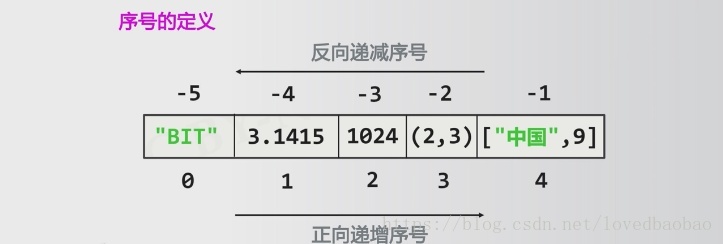
是具有先后关系的一组元素;序列是一维元素向量,元素类型可以不同;元素间由序号引导,通过下标访问序列的特定元素
注意:序列是一个基类类型(基础的数据结构),一般不直接使用,而是使用它的衍生类型,所以序列的所有操作在其衍生类型中都是适用的;同时各衍生类型又有它们自己特殊的操作能力。
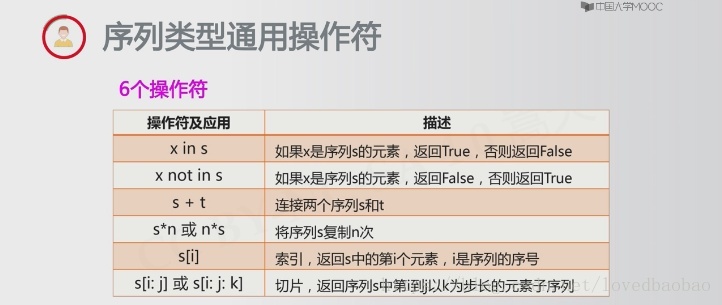
序列类型通用函数和方法:
| 函数和方法 | 描述 |
| len(s) | 返回序列s的长度 |
| min(s) | 返回序列s的最小元素,s中元素需要可比较 |
| max(s) | 返回序列s的最大元素,s中元素需要可比较 |
| s.index(x)或s.index(x,i,j) | 返回序列s从i开始到j位置中第一次出现元素x的位置 |
| s.count(x) | 返回序列s中出现x的总次数 |
(1)元组类型(非可变数据类型,一旦创建就不能修改,因此没有特殊操作)
- 使用()或tuple()创建,元素间用逗号,分隔
- 可以使用或不使用小括号(函数返回多元素时,其实就是返回了一个元组类型)
creature="cat","dog","tiger","human"
print(creature)
color=(0x001100,"blue",creature)
print(color)
print(creature[::-1]) #反向切片,生成一个新的元组
print(color[-1][2])->('cat', 'dog', 'tiger', 'human')
->(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
->('human', 'tiger', 'dog', 'cat')
->tiger
(2)列表类型(可变数据类型,创建后可以随意修改)
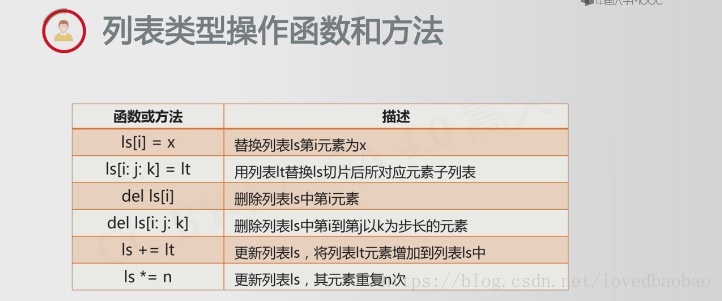
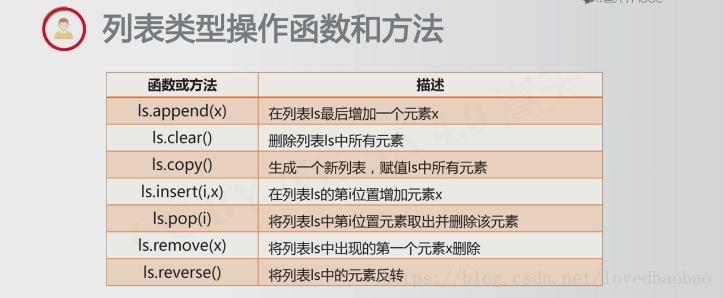
- 使用[]或list()创建,元素间用逗号,分隔
- 各元素可以不同,且无长度限制
ls=["cat","dog","tiger",1024]
lt=ls #[]真正创建一个列表,赋值仅传递引用
print(lt)->['cat', 'dog', 'tiger', 1024]
ls=["cat","dog","tiger",1024,(1,2,3)]
ls[1:2]=[1,2,3,4]
#ls[1:2]=(1,2,3,4) 输出结果一样
print(ls)
del ls[::3]
print(ls)
print(ls*2)->['cat', 1, 2, 3, 4, 'tiger', 1024,(1,2,3)]
->[1, 2, 4, 'tiger', (1, 2, 3)] #从第一个元素开始删
->[1, 2, 4, 'tiger', (1, 2, 3), 1, 2, 4, 'tiger', (1, 2, 3)]
#定义空列表
lt=list()
#lt=[]
#向lt新增5个元素
lt+=["zhangsan","lisi","wangermazi",0xFFFF,("你好",1),2]
# lt.append('zhangsan') #一次只能添加一个元素
# lt.append('lisi')
# lt.append('wangermazi')
# lt.append(0xFFFF)
# lt.append(("你好",1))
# lt.append(2)
print(lt)
#修改lt中第2个元素
lt[2]="王二麻子" #['zhangsan', 'lisi', '王二麻子', 65535, ('你好', 1), 2]
#lt[2:3]="王二麻子" ['zhangsan', 'lisi', '王', '二', '麻', '子', 65535, ('你好', 1), 2]
print(lt)
#向lt中第2个位置增加一个元素
lt.insert(2,555)
print(lt)
#从lt中第1个位置删除一个元素
del lt[1]
#lt.remove("zhangsan") #函数参数不能为下标
print(lt)
#删除lt中第1-3位置元素
del lt[1:4]
print(lt)
#判断lt中是否包含数字0
print(0 in lt)
#向lt新增数字0
lt.append(0)
print(lt)
#返回数字0所在lt中的索引
print(lt.index(0))
#lt的长度
print(len(lt))
#lt中最大元素
del lt[1]
lt[0]=9
print(max(lt)) #比较符号>不能用于不同元素之间的比较,str和int也不行
#清空lt
lt.clear()
print(lt)输出:
['zhangsan', 'lisi', 'wangermazi', 65535, ('你好', 1), 2]
['zhangsan', 'lisi', '王二麻子', 65535, ('你好', 1), 2]
['zhangsan', 'lisi', 555, '王二麻子', 65535, ('你好', 1), 2]
['zhangsan', 555, '王二麻子', 65535, ('你好', 1), 2]
['zhangsan', ('你好', 1), 2]
False
['zhangsan', ('你好', 1), 2, 0]
3
4
9
[]
切片赋值探究:
test_li=['a','b','c','d','e','f']
print(test_li)
li_id=id(test_li)
print(li_id) #观察列表id
test_li[1:4]=[1,2] #对切片进行赋值(不对等)
print(test_li)
li_id=id(test_li)
print(li_id) #此时id没有变化,说明是在原对象上进行修改输出:
['a', 'b', 'c', 'd', 'e', 'f']
48629680
['a', 1, 2, 'e', 'f']
48629680
listOfRows=[[1,2,3,4],[5,6,7,8],[9,10,11,12]]
list_buff=listOfRows
li_id2=id(listOfRows)
print(li_id2)
li_id2=id(list_buff)
print(li_id2) #两者id相同,说明引用了同一个对象
listOfRows=[ [ row[0],row[3],row[2] ] for row in listOfRows ]
print(listOfRows) #使用列表推导产生的结果符合预期
print(list_buff) #list_buff没有改变
li_id3=id(listOfRows)
print(li_id3)
li_id3=id(list_buff)
print(li_id3) #两者id不同,说明listOfRows绑定了一个新的对象输出:
49017920
49017920
[[1, 4, 3], [5, 8, 7], [9, 12, 11]]
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
49013344
49017920
#直接使用"listOfRows="的话,产生了一个新的对象,接下来试试listOfRows[:]=
listOfRows=[[1,2,3,4],[5,6,7,8],[9,10,11,12]]
list_buff=listOfRows
li_id2=id(listOfRows)
print(li_id2)
li_id2=id(list_buff)
print(li_id2) #两者id相同,说明引用了同一个对象
listOfRows[:]=[ [ row[0],row[3],row[2] ] for row in listOfRows ]
print(listOfRows) #使用列表推导产生的结果符合预期
print(list_buff) #list_buff同样改变,因为两者绑定了同一对象
li_id3=id(listOfRows)
print(li_id3)
li_id3=id(list_buff)
print(li_id3) #两者相同且没有发生变化,说明切片赋值是在原对象上修改输出:
49020200
49020200
[[1, 4, 3], [5, 8, 7], [9, 12, 11]]
[[1, 4, 3], [5, 8, 7], [9, 12, 11]]
49020200
49020200
序列类型应用场景
元组用于元素不改变的应用场景(数据保护)
列表更加灵活,是最常用的序列类型
最主要的作用:表示一组有序数据,进而操作它们
实例1.计算基本统计值
# CalStatisticsV1.py
# 获取用户不定长度的输入
def getNum():
nums = []
iNumStr = input("请输入数字(回车退出):")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(回车退出):")
return nums
# 计算平均值
def mean(numbers):
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
# 计算标准差
def dev(numbers, mean):
sdev = 0.0
for num in numbers:
sdev = sdev + (num - mean) ** 2
return pow(sdev / (len(numbers)-1), 0.5) #样本标准差
#return pow(sdev / len(numbers), 0.5) 总体标准差
# 计算中位数
def median(numbers):
sorted(numbers) # 列表排序
size = len(numbers)
if size % 2 == 0: # 偶数
med = (numbers[size // 2 - 1] + numbers[size // 2]) / 2
else:
med = numbers[size // 2]
return med
numbers=getNum()
m=mean(numbers)
print("平均值:{:.2},方差:{:.2},中位数:{}.".format(m,dev(numbers,m),median(numbers)))
运行结果:
请输入数字(回车退出):1
请输入数字(回车退出):2
请输入数字(回车退出):3
请输入数字(回车退出):4
请输入数字(回车退出):5
请输入数字(回车退出):6
请输入数字(回车退出):7
请输入数字(回车退出):8
请输入数字(回车退出):9
请输入数字(回车退出):
平均值:5.0,方差:2.7,中位数:5.
(3)字符串类型
3.字典类型(映射:是一种键【索引】和值【数据】的对应)


- 序列类型由0...N整数作为数据的默认索引
- 映射类型则由用户为数据定义索引
- 键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号:表示
d = {"中国": "北京", "美国": "华盛顿", "法国": "巴黎"}
print(d)
print(d["中国"]) # 利用[]获取数据值
#定义空字典
de = {};print(type(de)) # 表示空字典,不是空集合Set
#向de新增2个键值对元素
de["a"]=1
de["b"]=2
print(de)
#修改第2个元素
de["b"]=3
#de[2]=["BeiJing"] 字典无序,所以第二个元素即"b"
print(de)
#判断字符"c"是否是de的键
print("c"in de)
#计算de的长度
print(len(de))
#清空de
de.clear()
print(de)
print()
print("中国" in d)
print(d.keys())
print(d.values())
print(d.items()) #得出的结果可以利用for循环遍历,但不可用作列表操作
print()
print(d.get("中国","伊斯兰堡")) #"伊斯兰堡为默认值default"
print(d.get("巴基斯坦","伊斯兰堡"))
print(d.popitem()) #随机获取键值对
print()
输出:
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
北京
<class 'dict'>
{'a': 1, 'b': 2}
{'a': 1, 'b': 3}
False
2
{}
True
dict_keys(['中国', '美国', '法国'])
dict_values(['北京', '华盛顿', '巴黎'])
dict_items([('中国', '北京'), ('美国', '华盛顿'), ('法国', '巴黎')])
北京
伊斯兰堡
('法国', '巴黎')
Jieba库(优秀的中文分词第三方库)
中文文本需要通过分词获得单个的词语
原理:
利用一个中文词库,确定汉字之间的关联概率;
汉字间概率大的组成词组,形成分词结果;
除了jieba库自带词库,用户可添加自定义词组;
三种分词模式:
(1)精确模式:把文本精确的切分开,不存在冗余单词(最常用)
(2)全模式:把文本中所有可能的词语都扫描出来,有冗余
(3)搜索引擎模式:在精确模式的基础上,对长词再次切分,变成更短的词语
常用函数:lcut(s)、lcut(s,cut_all=True)、lcut_for_search(s)、add_word(s)
import jieba
#精确模式
strlist=jieba.lcut("中国是一个伟大的国家")
print(strlist)
#全模式
strlist=jieba.lcut("中国是一个伟大的国家",cut_all=True)
print(strlist)
#搜索引擎模式
strlist=jieba.lcut_for_search("中华人民共和国是伟大的")
print(strlist)
#添加新词
jieba.add_word("黄鼠狼语言") #向词库添加新词输出:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\WYQWE_~1\AppData\Local\Temp\jieba.cache
Loading model cost 5.282 seconds.
Prefix dict has been built succesfully.
['中国', '是', '一个', '伟大', '的', '国家']
['中国', '国是', '一个', '伟大', '的', '国家']
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']
实例2.文本词频统计
哈姆雷特文本下载地址:https://python123.io/resources/pye/hamlet.txt
三国演义文本下载地址:https://python123.io/resources/pye/threekingdoms.txt
- 英文文本——哈姆雷特(HAMLET)
注意:大小写,逗号,冒号等特殊符号(需进行"噪音处理")
#CalHamletV1.py
#得到"规范化"文本
def getText():
txt=open("../data/hamlet.txt","r").read() #以只读形式打开文本文件
txt=txt.lower() #全部小写
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~': #用空格逐一代替所有其他特殊符号
txt=txt.replace(ch," ")
return txt
hamletTxt=getText()
words=hamletTxt.split() #split方法默认采用空格将字符串进行分割,并使用列表形式返回
counts={}
for word in words:
counts[word]=counts.get(word,0)+1 #如果原词典中不存在对应单词,则返回值value=0
#print(counts.items()) #未排序
#利用列表类型的sort方法排序(也可使用sorted(所有可迭代序列)方法,返回一个新的list)
"""
list.sort(cmp=None,key=None,reverse=False) ——list本身被修改
-cmp:可选参数,若指定了该参数会使用该参数的方法进行排序
-key:确定、选择用来进行比较的元素
-reverse:True降序;False升序
"""
items=list(counts.items())
items.sort(key=lambda y:y[1],reverse=True) #取列表中每个元素索引为1的值为key值进行降序排列
#print(items)
#列出出现频率最高的10个单词
for i in range(10):
word,count=items[i] #自动分开赋值
print("{0:<10}{1:>5}".format(word,count)) #单词左对齐宽度10;次数右对齐宽度5输出:
the 1138
and 965
to 754
of 669
you 550
i 542
a 542
my 514
hamlet 462
in 436
- 中文文本——三国演义(ThreeKingdoms)
注意:利用jieba中文分词(特殊符号一起被处理掉)
版本1(统计出的高频词汇中包含了非姓名词语和“冗余”姓名词语):
#CalThreeKingdomV1.py
#词汇频率计算
import jieba
txt=open("../data/threekingdoms.txt","r",encoding="utf-8").read()
words=jieba.lcut(txt) #分词处理,返回列表
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items()) #若list(counts)只返回key值列表
#print(items) #未排序
items.sort(key=lambda y:y[1],reverse=True)
#print(items) #已排序
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
输出:
曹操 953
孔明 836
将军 772
却说 656
玄德 585
关公 510
丞相 491
二人 469
不可 440
荆州 425
版本2(完善版,得到人物出镜率Top20)
#CalThreeKingdomV2.py
#姓名频率计算
import jieba
txt=open("../data/threekingdoms.txt","r",encoding="utf-8").read() #utf-8编码方式打开文本
excludes={"将军","却说","荆州","二人","不可","不能","如此","商议","如何","主公","军士","左右","军马","引兵","次日","大喜"\
,"天下","东吴","于是","今日","不敢","魏兵","陛下","一人","都督","人马","不知","汉中","只见","众将","后主","蜀兵"\
,"上马","大叫","太守","此人","夫人","先主","后人","背后","城中","天子","一面","何不","大军","忽报","先生","百姓"\
,"何故","然后","先锋","不如","赶来","原来","令人","江东","下马","喊声","正是","徐州","忽然","因此","成都","不见"\
,"未知","大败","大事","之后","一军","引军","起兵","军中","接应","进兵","大惊","可以","以为","大怒","不得","心中"\
,"下文","一声","追赶"} #通过不断运行CalThreeKingdomV1和此文件,排除Top20中非姓名的词语
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
#通过不断运行CalThreeKingdomV1和此文件,将指向同一人物的词语"归一化"
elif word=="诸葛亮" or word=="孔明曰":
rword="孔明"
elif word=="关公" or word=="云长":
rword="关羽"
elif word=="玄德" or word=="玄德曰":
rword="刘备"
elif word=="孟德" or word=="丞相":
rword="曹操"
else:
rword=word
counts[rword]=counts.get(rword,0)+1
for word in excludes: #删除非姓名词汇
del counts[word]
items=list(counts.items())
items.sort(key=lambda y:y[1],reverse=True)
for i in range(20):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))输出:
曹操 1451
孔明 1383
刘备 1252
关羽 784
张飞 358
吕布 300
赵云 278
孙权 264
司马懿 221
周瑜 217
袁绍 191
马超 185
魏延 180
黄忠 168
姜维 151
马岱 127
庞德 122
孟获 122
刘表 120
夏侯惇 116
(PS:三国演义中出镜率最高的居然是曹操,惊讶!而且孙权的出镜率相比之下好没存在感呀。。。)