本文介绍与一下Python对Excel文件的基本操作。
主要介绍两个模块xlrd和xlwt模块,这两个模块是针对Excel97-2003工作簿的,如果要操作Excel 2007及以上,需要使用openpyxl模块。并且xlwt模块只能创建一个新的工作簿,然后进行写操作,如果要对已经存在的工作簿进行操作,需要使用xlutils模块。
一个Excel文件,就是一个“工作簿”,一个“工作簿”里面可以包含多个“工作表(sheet)”
一、使用xlrd模块对文件进行读操作
假设我们的表如下,是一个“农村居民家庭人均纯收入和农村居民家庭人均消费情况”的表格。后缀为.xls。里面包含两个工作表,“各省市”和“测试表”。
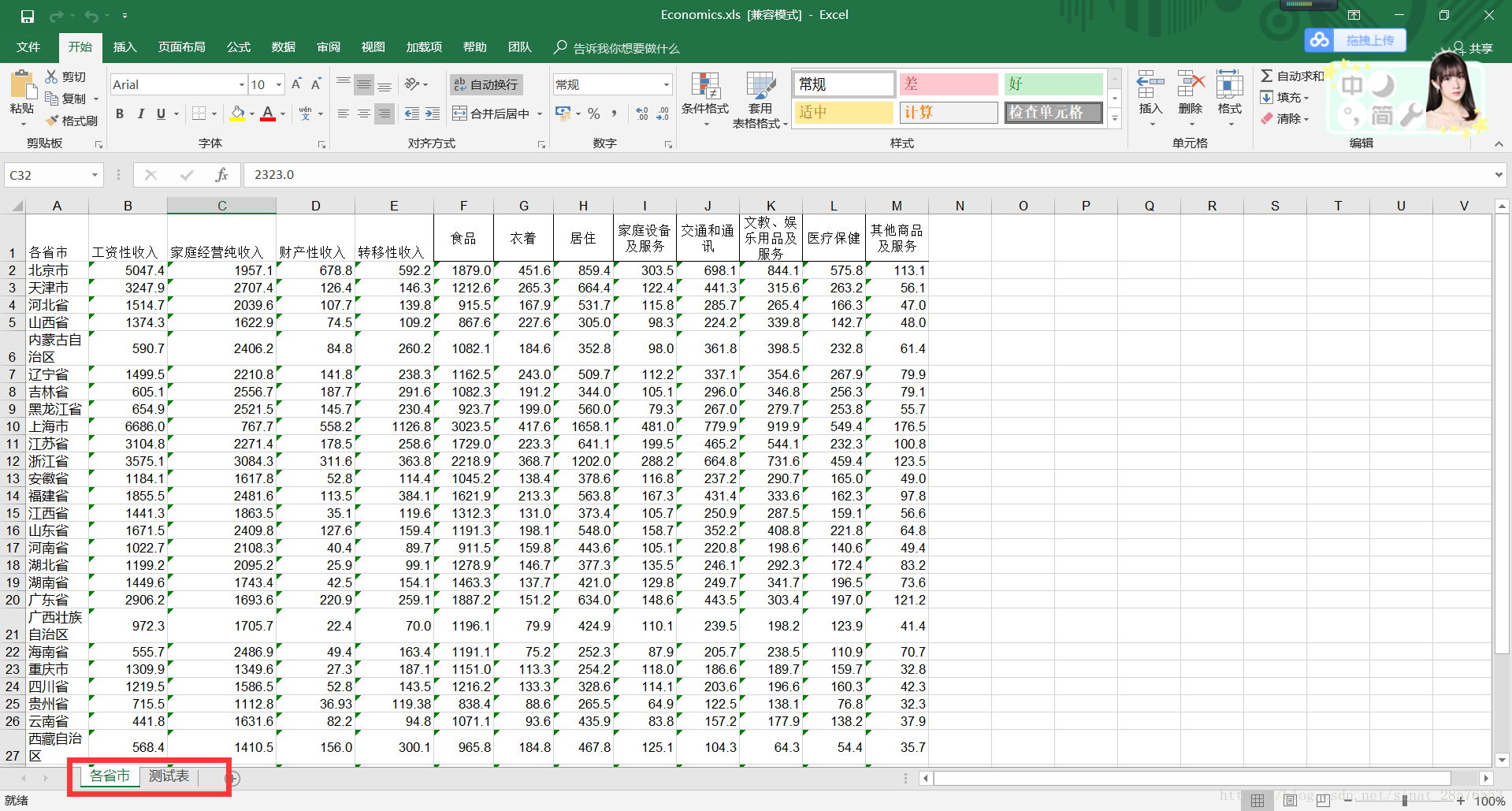
import xlrd #引入模块
#打开文件,获取excel文件的workbook(工作簿)对象
workbook=xlrd.open_workbook("DataSource/Economics.xls") #文件路径
'''对workbook对象进行操作'''
#通过sheet索引获得sheet对象
sheet0=workbook.sheet_by_index(0)
print(sheet0) #<xlrd.sheet.Sheet object at 0x000001B98D99CFD0>
#通过sheet名获得sheet对象
sheet0=workbook.sheet_by_name("各省市")
print(sheet0) #<xlrd.sheet.Sheet object at 0x000001B98D99CFD0>
#获取所有sheet的名字
name=workbook.sheet_names()
print(name) #['各省市', '测试表'] 输出所有的表名,以列表的形式
#由上可知,workbook.sheet_names() 返回一个list对象,可以对这个list对象进行操作
sheet0_name=workbook.sheet_names()[0] #通过sheet索引获取sheet名称
print(sheet0_name) #各省市
'''对sheet对象进行操作'''
name=sheet0.name #获取表的姓名
print(name) #各省市
nrows=sheet0.nrows #获取该表总行数
print(nrows) #32
for i in range(nrows): #循环打印每一行
print(sheet0.row_values(i)) #以列表形式读出,列表中的每一项是str类型
#['各省市', '工资性收入', '家庭经营纯收入', '财产性收入', ………………]
#['北京市', '5047.4', '1957.1', '678.8', '592.2', '1879.0,…………]
ncols=sheet0.ncols #获取该表总列数
print(ncols) #13
col_data=sheet0.col_values(0) #获取第一列的内容
print(col_data)
#通过坐标读取表格中的数据
cell_value1=sheet0.cell_value(0,0)
cell_value2=sheet0.cell_value(1,0)
print(cell_value1) #各省市
print(cell_value2) #北京市
cell_value1=sheet0.cell(0,0).value
print(cell_value1) #各省市
cell_value1=sheet0.row(0)[0].value
print(cell_value1) #各省市
二、使用xlwt模块对文件进行写操作
# 导入xlwt模块
import xlwt
#创建一个Workbook对象,相当于创建了一个Excel文件
book=xlwt.Workbook(encoding="utf-8",style_compression=0)
'''
Workbook类初始化时有encoding和style_compression参数
encoding:设置字符编码,一般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。默认是ascii。
style_compression:表示是否压缩,不常用。
'''
# 创建一个sheet对象,一个sheet对象对应Excel文件中的一张表格。
sheet = book.add_sheet('test01', cell_overwrite_ok=True)
# 其中的test是这张表的名字,cell_overwrite_ok,表示是否可以覆盖单元格,其实是Worksheet实例化的一个参数,默认值是False
# 向表test中添加数据
sheet.write(0, 0, '各省市') # 其中的'0-行, 0-列'指定表中的单元,'各省市'是向该单元写入的内容
sheet.write(0, 1, '工资性收入')
#也可以这样添加数据
txt1 = '北京市'
sheet.write(1,0, txt1)
txt2 = 5047.4
sheet.write(1, 1, txt2)
#添加第二个表
sheet2=book.add_sheet("test02",cell_overwrite_ok=True)
sheet2.write(0, 0, '各省市')
sheet2.write(0, 1, '工资性收入')
Province=['北京市', '天津市', '河北省', '山西省', '内蒙古自治区', '辽宁省',
'吉林省', '黑龙江省', '上海市', '江苏省', '浙江省', '安徽省', '福建省',
'江西省', '山东省', '河南省', '湖北省', '湖南省', '广东省', '广西壮族自治区',
'海南省', '重庆市', '四川省', '贵州省', '云南省', '西藏自治区', '陕西省', '甘肃省',
'青海省', '宁夏回族自治区', '新疆维吾尔自治区']
Income=['5047.4', '3247.9', '1514.7', '1374.3', '590.7', '1499.5', '605.1', '654.9',
'6686.0', '3104.8', '3575.1', '1184.1', '1855.5', '1441.3', '1671.5', '1022.7',
'1199.2', '1449.6', '2906.2', '972.3', '555.7', '1309.9', '1219.5', '715.5', '441.8',
'568.4', '848.3', '637.4', '653.3', '823.1', '254.1']
Project=['各省市', '工资性收入', '家庭经营纯收入', '财产性收入', '转移性收入', '食品', '衣着',
'居住', '家庭设备及服务', '交通和通讯', '文教、娱乐用品及服务', '医疗保健', '其他商品及服务']
#填入第一列
for i in range(1, len(Province)):
sheet2.write(i, 0, Province[i-1])
#填入第二列
for i in range(1,len(Income)):
sheet2.write(i,1,Income[i-1])
#填入第一行
for i in range(2,len(Project)):
sheet2.write(0,i,Project[i])
# 最后,将以上操作保存到指定的Excel文件中
book.save('test1.xls') 执行后的结果如下:
第一张sheet:
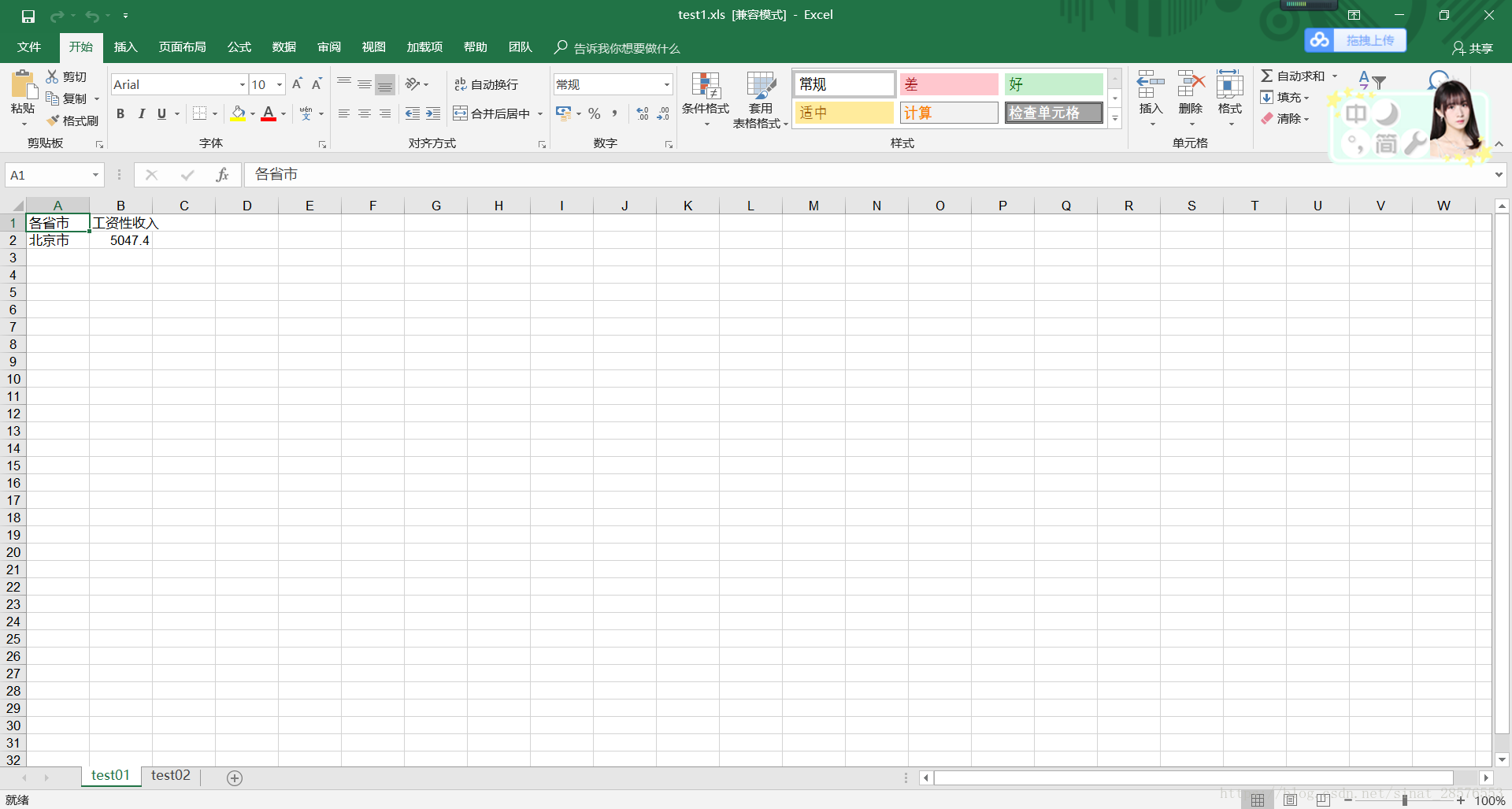
第二张sheet:
