引言
在机器学习领域,AUC值经常用来评价一个二分类模型的训练效果,对于许多机器学习或者数据挖掘的从业者或在校学生来说,AUC值的概念也经常被提起,但由于大多数时候我们都是借助一些软件包来训练机器学习模型,模型评价指标的计算往往被软件包所封装,因此我们常常会忽略了它们的具体意义,这在有些时候会让我们对于手头正在进行的任务感到困惑。笔者也曾遇到类似的问题,因此希望借由本文来梳理下AUC值的意义与计算方法,通过实际的例子帮助读者加深理解,同时给出了使用scikit-learn工具库计算AUC值的方法,供各位参考。
定义
AUC的全称是Area under the Curve of ROC,也就是ROC曲线下方的面积。这里出现了另一个概念,就是ROC曲线。那么ROC曲线是个什么东西呢?我们参看下维基百科上的定义:在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是一种坐标图式的分析工具,用于 (1) 选择最佳的信号侦测模型、舍弃次佳的模型。 (2) 在同一模型中设定最佳阈值。这个概念最早是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具。概括来说,可以把ROC曲线理解为一种用于统计分析的图表工具。
那么具体到机器学习的理论中,ROC曲线该怎么理解呢?首先,需要指出的是,ROC分析的是二元分类模型,也就是输出结果只有两种类别的模型,比如:(阳性/阴性)(有病/没病)(垃圾邮件/非垃圾邮件)。在二分类问题中,数据的标签通常用(0/1)来表示,在模型训练完成后进行测试时,会对测试集的每个样本计算一个介于0~1之间的概率,表征模型认为该样本为阳性的概率,我们可以选定一个阈值,将模型计算出的概率进行二值化,比如选定阈值=0.5,那么当模型输出的值大于等于0.5时,我们就认为模型将该样本预测为阳性,也就是标签为1,反之亦然。选定的阈值不同,模型预测的结果也会相应地改变。二元分类模型的单个样本预测有四种结果:
- 真阳性(TP):判断为阳性,实际也是阳性。
- 伪阳性(FP):判断为阴性,实际却是阳性。
- 真阴性(TN):判断为阴性,实际也是阴性。
- 伪阴性(FN):判断为阴性,实际却是阳性。
这四种结果可以画成2 × 2的混淆矩阵:
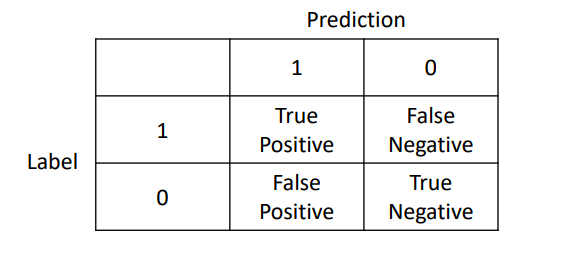
有了混淆矩阵,就可以定义ROC曲线了。ROC曲线将假阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。其中:
- TPR:在所有实际为阳性的样本中,被正确地判断为阳性的样本比率。
- FPR:在所有实际为阴性的样本中,被错误地判断为阳性的样本比率。
- TPR = TP / (TP + FN)
- FPR = FP / (FP + TN)
给定一个二分类模型和它的阈值,就可以根据所有测试集样本点的真实值和预测值计算出一个 (X=FPR, Y=TPR) 坐标点,这也就是绘制单个点的方法。那整条ROC曲线又该怎么画呢?具体方法如下:
在我们训练完一个二分类模型后,可以使用该模型对测试集中的全部样本点计算一个对应的概率值,每个值都介于0~1之间。假设测试集有100个样本点,我们可以对这100个样本的预测值从高到低排序,然后依次取每个值作为阈值,一旦阈值确定我们就可以绘制ROC曲线上的一个点,按照这种方法依次将100个点绘制出来,再将各个点依次连接起来,就得到了我们想要的ROC曲线!
然后再回到最初的问题,AUC值其实就是ROC曲线下方所覆盖的面积,当我们绘制出ROC曲线之后,AUC的值自然也就计算好啦。
示例
这里引用上海交大张伟楠老师机器学习课件中的例子来说明:
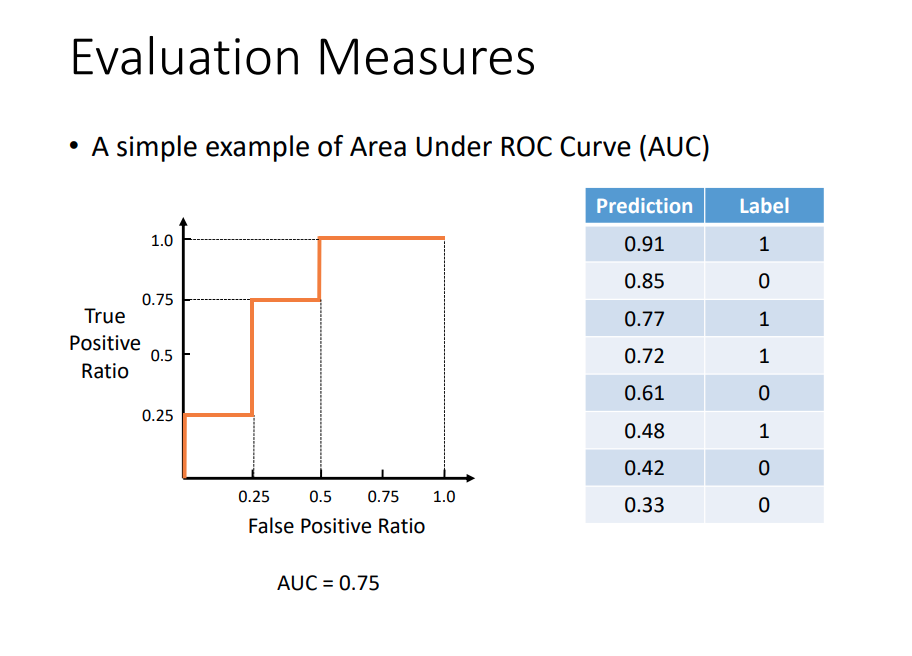
如上图所示,我们有8个测试样本,模型的预测值(按大小排序)和样本的真实标签如右表所示,绘制ROC曲线的整个过程如下所示:
- 令阈值等于第一个预测值0.91,所有大于等于0.91的预测值都被判定为阳性,此时TPR=1/4,FPR=0/4,所有我们有了第一个点(0.0,0.25)
- 令阈值等于第二个预测值0.85,所有大于等于0.85的预测值都被判定为阳性,这种情况下第二个样本属于被错误预测为阳性的阴性样本,也就是FP,所以TPR=1/4,FPR=1/4,所以我们有了第二个点(0.25,0.25)
- 按照这种方法依次取第三、四…个预测值作为阈值,就能依次得到ROC曲线上的坐标点(0.5,0.25)、(0.75,0.25)…(1.0,1.0)
- 将各个点依次连接起来,就得到了如图所示的ROC曲线
- 计算ROC曲线下方的面积为0.75,即AUC=0.75
代码
在清楚了AUC值的计算原理后,我们再来看看如何在代码中实现它。通常很多的机器学习工具都封装了模型指标的计算,当然也包括AUC值。这里我们来一起看下scikit-learn中AUC的计算方式,如下所示:
>>> import numpy as np
>>> from sklearn.metrics import roc_auc_score
>>> y_true = np.array([0, 0, 1, 1])
>>> y_scores = np.array([0.1, 0.4, 0.35, 0.8])
>>> roc_auc_score(y_true, y_scores)
0.75可以看出,使用scikit-learn工具提供的roc_auc_score函数计算AUC值相当简单,只需要提供样本的实际标签和预测值这两个变量即可,大大方便了我们的使用,真心感谢这些开源软件的作者们!
总结
看到这里的小伙伴们是不是对AUC值的概念有了更好的理解呢。总的来说,AUC值就是一个用来评价二分类模型优劣的常用指标,AUC值越高通常表明模型的效果越好,在实际使用中我们可以借助软件包的相应函数进行快速计算。如果各位还有一些问题或者是对文章中的某些部分有疑问,欢迎在评论区讨论。