Akka集群支持去中心化的基于P2P的集群服务,没有单点故障(SPOF)问题,它主要是通过Gossip协议来实现。对于集群成员的状态,Akka提供了一种故障检测机制,能够自动发现出现故障而离开集群的成员节点,通过事件驱动的方式,将状态传播到整个集群的其它成员节点。
集群概念
节点(node):集群中的逻辑成员。允许一台物理机上有多个节点。由元组hostname:port:uid唯一确定。
集群(cluster):由成员关系服务构建的一组节点。
领导(leader):集群中唯一扮演领导角色的节点。
种子节点(seed node):作为其他节点加入集群的连接点的节点。实际上,一个节点可以通过向集群中的任何一个节点发送Join(加入)命令加入集群。
这里以Akka官网提供的成员状态状态图为例,如图1所示。
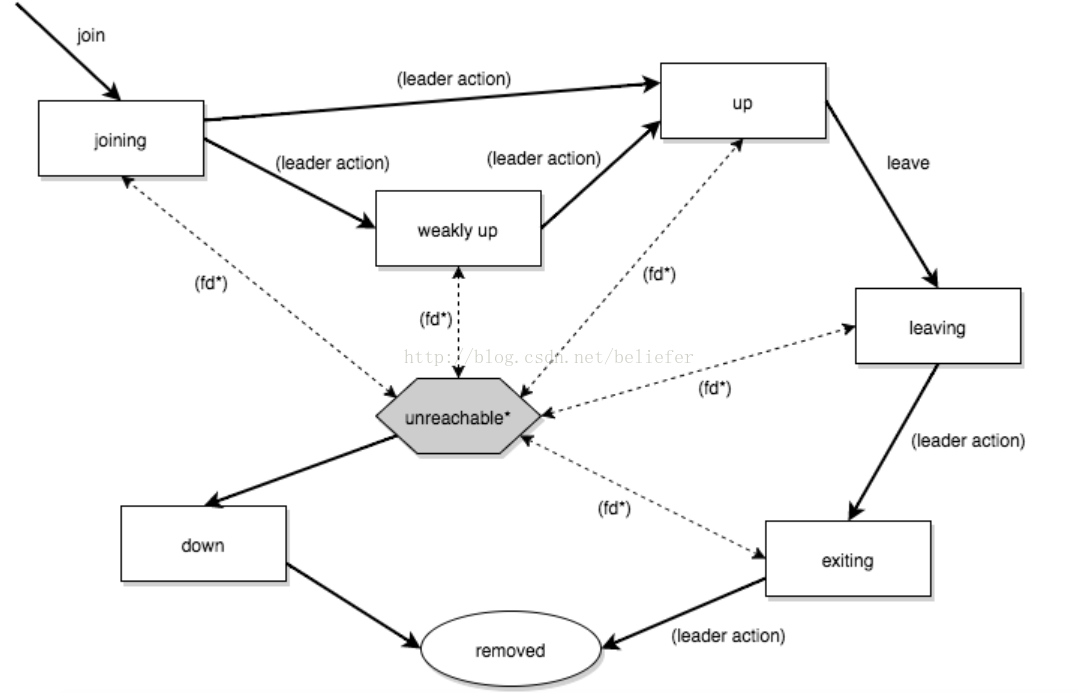
图1展示了状态转换的两个因素:动作和状态。
状态
joining:节点正在加入集群时的状态。
weekly up:配置了akka.cluster.allow-weakly-up-members=on时,启用的状态。
up:集群中节点的正常状态。
leaving/exiting:优雅的删除节点时,节点的状态。
down:标记为已下线的状态。
removed:墓碑状态,表示已经不再是集群的成员。
动作
join:加入集群。
leave:告知节点优雅的离开集群。
down:标记集群为已下线。
配置
本节将要展示构建集群所需要的最基本的配置, application.conf文件的内容如下:
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 2551
}
}
cluster {
seed-nodes = [
"akka.tcp://[email protected]:2551",
"akka.tcp://[email protected]:2552"
]
# auto downing is NOT safe for production deployments.
auto-down-unreachable-after = 10s
# Disable legacy metrics in akka-cluster. metrics 指标
metrics.enabled=off
}
} 首先任何一个集群都需要种子节点,作为基本的加入集群的连接点。本例中以我本地的两个节点(分别监听2551和2552端口)作为种子节点。无论配置了多少个种子节点,除了在seed-nodes中配置的第一个种子节点需要率先启动之外(否则其它种子节点无法初始化并且其它节点也无法加入),其余种子节点都是启动顺序无关的。第一个节点需要率先启动的另一个原因是如果每个节点都可以率先启动,那么有可能造成一个集群出现几个种子节点都启动并且加入了自己的集群,此时整个集群实际上分裂为几个集群,造成孤岛。当你启动了超过2个以上的种子节点,那么第一个启动的种子节点是可以关闭下线的。如果第一个种子节点重启了,它将不会在自己创建集群而是向其它种子节点发送Join消息加入已存在的集群。
注意:除了akka.remote.netty.tcp.port配置项指定的端口不同,所有加入集群节点的application.conf可以完全一样。如果akka.remote.netty.tcp.port未指定,那么Akka会为你随机选择其他未占用的端口。
集群监听器
创建一个简单的集群监听器SimpleClusterListener(实际上是一个Actor,因为继承了UntypedActor),它向集群订阅MemberEvent(成员事件)和UnreachableMember(不可达成员)两种消息,来对集群成员进行管理(打印)
Cluster cluster = Cluster.get(getContext().system());
public void preStart() {
cluster.subscribe(getSelf(),
ClusterEvent.initialStateAsEvents(),
MemberEvent.class,
UnreachableMember.class);
}
@Override
public void onReceive(Object message) {
if (message instanceof MemberUp) { //ClusterEvent.**
MemberUp mUp = (MemberUp) message;
log.info("Member is Up: {}", mUp.member());
} else if (message instanceof UnreachableMember) { //ClusterEvent.UnreachableMember
UnreachableMember mUnreachable = (UnreachableMember) message;
log.info("Member detected as unreachable: {}", mUnreachable.member());
} else if (message instanceof MemberRemoved) { //ClusterEvent.**
MemberRemoved mRemoved = (MemberRemoved) message;
log.info("Member is Removed: {}", mRemoved.member());
} else if (message instanceof MemberEvent) { //ClusterEvent.**
// ignore
} else {
unhandled(message);
}
} 在 21、聊聊akka(一)使用及集群调用(负载)中集群启动日志.
各个节点的状态迁移信息,第一个种子节点正在加入自身创建的集群时的状态时JOINING,由于第一个种子节点将自己率先选举为Leader,因此它还将自己的状态改变为Up。后面它还将第二个种子节点和第三个节点从JOINING转换到Up状态。
关闭2553,其状态首先被标记为Down,最后被转换为Removed。
指定集群中的角色
roles = [client] //服务消费端
roles = [backend] //服务提供端
TransformationMessages.java
/**
* 服务提供方向服务调用方注册
*/
public static final int BACKEND_REGISTRATION = 1;MyAkkaClusterServer.java
在preStart方法中订阅了集群的MemberUp事件,自然会受到 onReceive 方法中的 :
else if (message instanceof ClusterEvent.MemberUp) {
ClusterEvent.MemberUp mUp = (ClusterEvent.MemberUp) message;
register(mUp.member());
}
/**
* 如果是客户端角色,则向客户端注册自己的信息。客户端收到消息以后会将这个服务端存到本机服务列表中
*/
void register(Member member) {
if (member.hasRole("client"))
getContext().actorSelection(member.address() + "/user/myAkkaClusterClient").tell(BACKEND_REGISTRATION, getSelf());
}actorSelection
ActorSelection greeter = system.actorSelection("akka.tcp://MySystem@machine2:2552/user/greeter");上面的几行代码简单展示了akka中的分布式环境中不同机器节点之间actor的相互通信方式,可以看出和Erlang很类似,即屏蔽底层节点之间的通信细节,然后提供简单API接口。
actorOf / actorSelection / actorFor的区别:
actorOf 创建一个新的actor,创建的actor为调用该方法所属的context的直接子actor。
actorSelection 查找现有actor,并不会创建新的actor。
actorFor 查找现有actor,不创建新的actor,已过时。
一般做法:
getContext().actorSelection(member.address() + "/user/myAkkaClusterClient")这里的myAkkaClusterClient 为 member 服务的首字母小写.
ActorSystem.actorSelection或ActorContext.actorSelection,可在任何角色内部通过context.actorSelection得到该对象的引用。在ActorSystem中,一个角色选择就像产生了一个它的双胞胎兄弟,而不是从启动它的角色所在角色树的根查找。路径元素中包含两个点(”..”)可以用来访问父角色。你可以像下面的例子一样向它的兄弟发送一条消息:
context.actorSelection(“../serviceA”) ! msg
通常情况下也可以通过绝对路径在上下文中进行查找:
context.actorSelection(“/user/serviceA”) ! msg
它们都能正常的工作。
客户端
客户端除了监听端口不同外,也需要增加akka.cluster.roles配置项,我们指定为client。
@Override
public void onReceive(Object message) {
if ((message instanceof TransformationMessages.TransformationJob) && backends.isEmpty()) {//无服务提供者
TransformationMessages.TransformationJob job = (TransformationMessages.TransformationJob) message;
getSender().tell(
new TransformationMessages.JobFailed("Service unavailable, try again later", job),
getSender());
} else if (message instanceof TransformationMessages.TransformationJob) {
TransformationMessages.TransformationJob job = (TransformationMessages.TransformationJob) message;
/**
* 这里在客户端业务代码里进行负载均衡操作。实际业务中可以提供多种负载均衡策略,并且也可以做分流限流等各种控制。
*/
jobCounter++;
backends.get(jobCounter % backends.size()).forward(job, getContext());
} else if (message instanceof Integer && BACKEND_REGISTRATION == (int)message) { //服务提供方的注册信息
getContext().watch(getSender());//这里对服务提供者进行watch
backends.add(getSender());
} else if (message instanceof Terminated) {
Terminated terminated = (Terminated) message;
backends.remove(terminated.getActor()); //移除服务提供者
} else {
unhandled(message);
}
}持久化与快照
持久化 的目的,同存储数据,来记录历史操作,及事故补偿或会滚 .
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-persistence_2.11</artifactId>
<version>2.4.16</version>
</dependency>
<dependency>
<groupId>org.iq80.leveldb</groupId>
<artifactId>leveldb</artifactId>
<version>0.7</version>
</dependency>
<dependency>
<groupId>org.fusesource.leveldbjni</groupId>
<artifactId>leveldbjni-all</artifactId>
<version>1.8</version>
</dependency>
有关Akka的日志持久化和快照持久化的配置如下:
# 持久化相关
akka.persistence.journal.plugin = "akka.persistence.journal.leveldb" //akka.persistence.journal.inmem
akka.persistence.journal.leveldb.dir = "target/example/journal"
akka.persistence.journal.leveldb.native = false //本地并没有安装leveldb,所以这个属性置为false
akka.persistence.snapshot-store.plugin = "akka.persistence.snapshot-store.local"日志插件使用了leveldb,leveldb的存储目录为当前项目编译路径下的example/journal路径下。快照插件使用了local,存储路径与前者相同。
参看 https://blog.csdn.net/beliefer/article/details/53925622
https://segmentfault.com/a/1190000010309436
1.akka-persistence-sql-async: 支持MySQL和PostgreSQL,另外使用了全异步的数据库驱动,提供异步非阻塞的API,我司用的就是它的变种版,6的飞起。
2.akka-persistence-cassandra: 官方推荐的插件,使用写性能very very very fast的cassandra数据库,是几个插件中比较流行的一个,另外它还支持persistence query。
3.akka-persistence-redis: redis应该也很符合Akka persistence的场景,熟悉redis的同学可以使用看看。
4.akka-persistence-jdbc: 怎么能少了jdbc呢?不然怎么对的起java爸爸呢,支持scala和java哦。
https://github.com/okumin/akka-persistence-sql-async
https://github.com/hootsuite/akka-persistence-redis
https://github.com/krasserm/akka-persistence-cassandra
https://github.com/dnvriend/akka-persistence-jdbc
批量持久化
上面说到我司用的是akka-persistence-sql-async插件,所以我们是将事件和快照持久化到数据库的,一开始我也是像上面demo一样,每次事件都会持久化到数据库,但是后来在性能测试的时候,因为本身业务场景对数据库的压力也比较大,在当数据库到达每秒1000+的读写量后,另外说明一下使用的是某云数据库,性能中配以上,发现每次持久化的时间将近要15ms,这样换算一下的话Actor每秒只能处理60~70个需要持久化的事件,而实际业务场景要求Actor必须在3秒内返回处理结果,这种情况下导致大量消息处理超时得不到反馈,另外还有大量的消息得不到处理,导致系统错误暴增,用户体验下降,既然我们发现了问题,那么我们能不能进行优化呢?事实上当然是可以,既然单个插入慢,那么我们能不能批量插入呢,Akka persistence为我们提供了persistAll方法.
https://github.com/godpan/akka-demo