环境准备
准备一个Centos6.9主机环境,用于克隆其他主机节点
网络配置
1 修改 网卡ip地址
vi /etc/sysconfig/network-script/ifcfg-eth0
其中 ipaddr 中 C类ip字段 跟VMnet8网卡有关
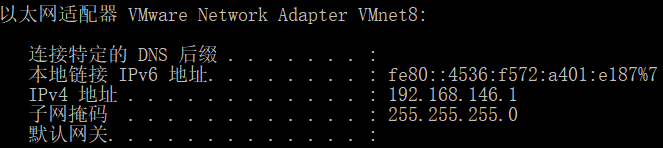
2 从新启动网络服务
service network restart3 查询网卡,确定网卡配置正确
ifconfig4 关闭防火墙
service iptables stop(临时关闭)
chkconfig iptables off (关闭开启自启)5 关闭SELinux 安全套件
vi /etc/selinux/config
6 关闭主机,添加虚拟物理双网卡

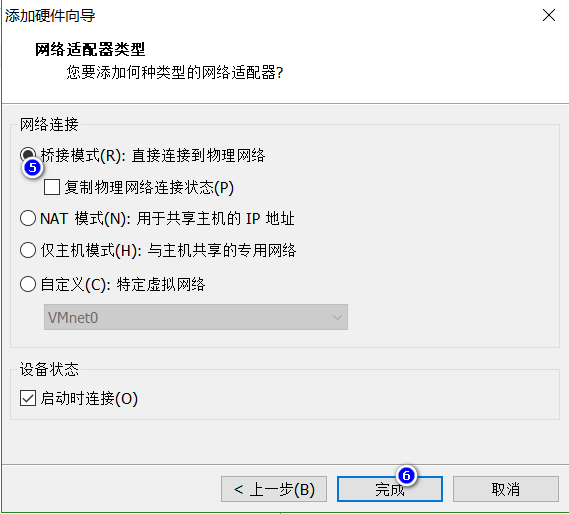
虚拟化网络设置,将主机内部ip桥接到外部能正常网络通信的网卡ip
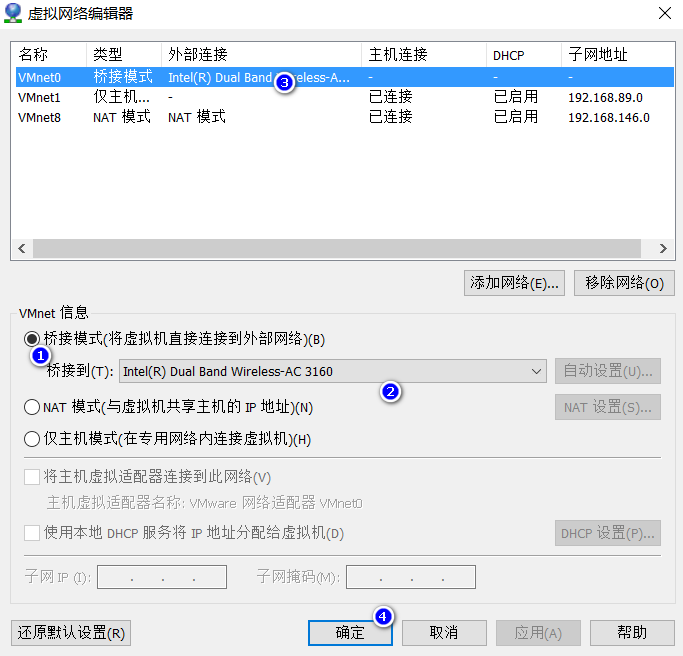
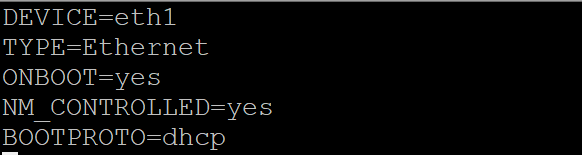
7 为Linux双网卡进行设置
cp /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/sysconfig/network-scripts/ifcfg-eth1
vi /etc/sysconfig/network-scripts/ifcfg-eth1
service network restart 重启网卡服务
ifconfig 查询网卡
ping www.baidu.com 测试能否ping通8 设置主机名
vi /etc/sysconfig/network
reboot 重启主机生效9 设置域名解析
window下识别主机
C:\Windows\System32\drivers\etc\hostslinux 下识别主机
vi /etc/hosts分别在linux中,window中,ping 主机名,测试是否配置正确
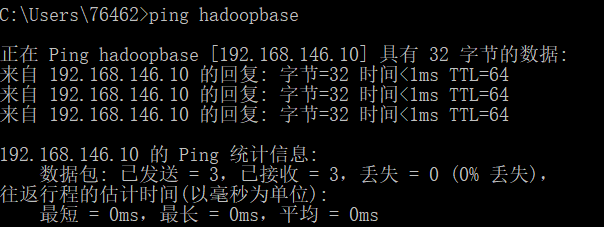
JDK安装
安装rz ftp快速上传工具
yum -y instll lrzsz
rz //使用时命令1 上传 jdk rpm 包
2 安装jdk
rpm -ivh jdk-7u71-linux-x64.rpm3 配置环境变量
vi .bash_profile | vi /etc/profile | vi .bashrc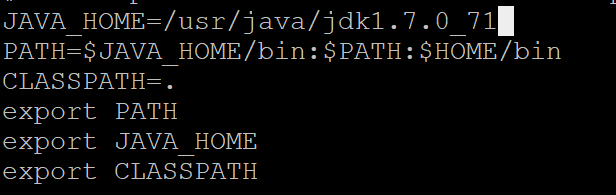
source .bash_profile //更新环境
java -version //查询java版本,确定是否安装成功集群搭建
为了不破坏主机环境,以备后续使用,因此需要克隆新的主机进行集群搭建
1 从环境主机克隆新机器
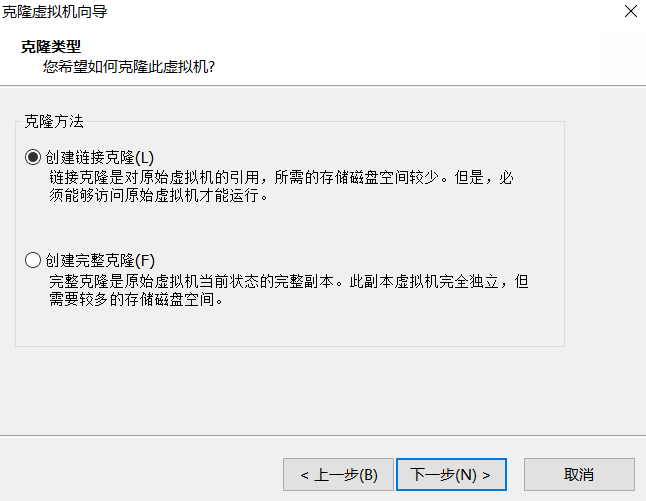
2 为新机器配置网卡
rm –rf /etc/udev/rules.d/70-persistence-net.rules 删除原主机的mac地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0 修改主机ip
reboot 重启机器
ifconfig 查询网卡是否正确3 修改集群中所有主机的主机名和DNS对应关系
一般我们都是修改一个主机 然后使用scp命令,进行远程服务间拷贝
scp /etc/hosts root@192.168.146.11:/etcHadoop安装
1 准备环境
参照上面
2 下载hadoop版本 2.5.2
http://archive.apache.org/dist/hadoop/core/
3 上传,解压 hadoop
//选择hadoop上传
rz
//解压文件到指定目录
tar -zxvf hadoop-2.5.2.tar.gz -C /opt/install/ 4 修改配置
a) etc/hadoop/hadoop-env.sh
//JAVA_HOME改为自己JDK安装的目录
export JAVA_HOME=/usr/java/jdk1.7.0_71 
b) etc/hadoop/core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/install/hadoop-2.5.2/data/tmp</value>
</property>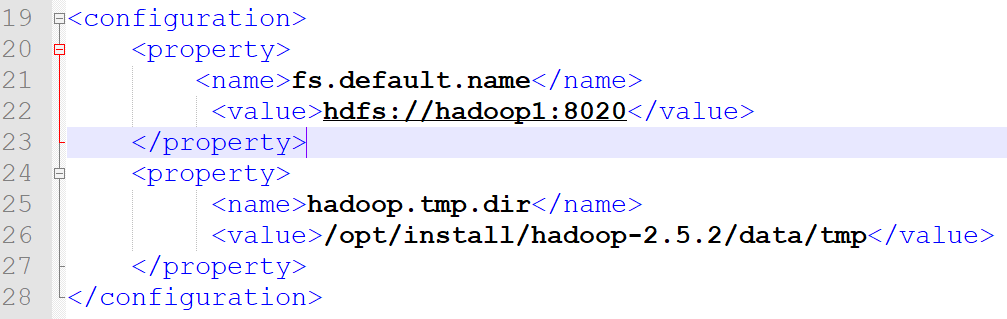
c) etc/hadoop/hdfs-site.xml
//存储数据块副本的个数
<property>
<name>dfs.replication</name>
<value>1</value>
</property>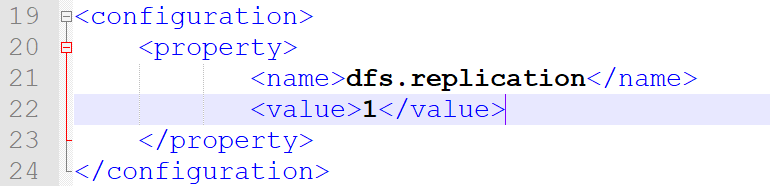
d) etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
e) etc/hadoop/mapred-site.xml.template
//改名
mv mapred-site.xml.template mapred-site.xml打开更名后的文件配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5 启动HDFS 还有Yarn
//格式化namenode 只执行一次(直接粘可能有问题)
bin/hdfs namenode –format
//启动namenode
sbin/hadoop-daemon.sh start namenode
//启动datanode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager jps 查询相关进程 确定是否启动成功
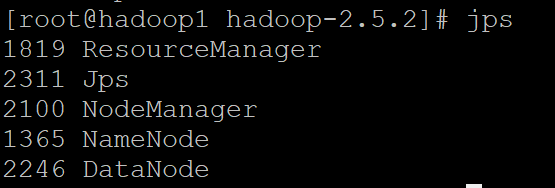
6 访问测试
Hdfs: http://hadoop1:50070
yarn: http://hadoop1:8088
7 定义脚本
为了下次启动方便,我们可以定义快速启动关闭脚本
启动脚本
hadoop-start.sh
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager关闭脚本
hadoop-stop.sh
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager注意: 新创建的脚本没有可执行权限, chmod 744 修改