关于k8s网络,我们通常有以下问题需要回答:
- k8s的网络模型是什么
- Docker背后的网络基础是什么
- Docker自身的网络模型和局限
- k8s的网络组件之间是怎么通信的
- 外部如何访问k8s的集群
- 有哪些开源的组件支持k8s的网络模型
接下来的内容,就对以上问题的答案进行深入探究。
1、k8s网络模型
Kubernetes 网络模型设计的一个基础原则是:每个 Pod 都拥有一个独立的 IP 地址,而且假定所有 Pod 都在一个可以直接连通的、扁平的网络空间中。所以不管它们是否允许在同一个 Node(宿主机)中,都要求它可以直接通过对方的 IP 进行访问。
设计这个原则的原因是,用户不需要额外考虑如何建立 Pod 之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
实际上在 Kubernetes 的世界里,IP 是以 Pod 为单位进行分配的。一个 Pod 内部的所有容器共享一个网络堆栈(实际上就是一个网络命名空间,包括它们的 IP 地址、网络设备、配置等都是共享的)。按照这个网络原则抽象出来的
一个 Pod 一个 IP 的设计模型也被称作 IP-per-Pod 模型。
由于 Kubernetes 的网络模型假设 Pod 之间访问时使用的是对方 Pod 的实际地址,所以一个 Pod 内部的应用程序看到的自己的 IP 地址和端口与集群内其他 Pod 看到的一样。它们都是 Pod 实际分配的 IP 地址(从 docker0 上分配的)。将 IP 地址和端口在 Pod 内部和外部都保持一致,可以不使用 NAT 来进行转换,地址空间也自然是平的。Kubernetes 的网络之所以这么设计,主要原因就是可以兼容过去的应用。当然,我们使用 Linux 命令 “ip addr show” 也能看到这些地址,和程序看到的没有什么区别。所以这种 IP-per-Pod 的方案很好的利用了现有的各种域名解析和发现机制。
一个 Pod 一个 IP 的模型还有另外一个含义,
那就是同一个 Pod 内的不同容器将会共享一个网络命名空间,也就是说同一个 Linux 网络协议栈。这就意味着同一个 Pod 内的容器可以通过 localhost 来连接对方的端口。这种关系和同一个 VM 内的进程之间的关系是一样的,看起来 Pod 内的容器之间的隔离性降低了,而且
Pod 内不同容器之间的端口是共享的,没有所谓的私有端口的概念了。如果你的应用必须要使用一些特定的端口范围,那么你也可以为这些应用单独创建一些 Pod。反之,对这些没有特殊需要的应用,这样做的好处是 Pod 内的容器是共享部分资源的,通过共享资源互相通信显然更加容易和高效。针对这些应用,虽然损失了可接受范围内的部分隔离性,但也是值得的。
IP-per-Pod 模式和
Docker 原生的通过动态端口映射方式实现的多借点访问模式有什么区别呢?
主要区别是后者的动态端口映射会引入端口管理的复杂性,而且访问者看到的 IP 地址和端口与服务提供者实际绑定的不同(因为 NAT 的缘故,它们都被映射成新的地址和端口了),这也会引起应用配置的复杂化,因为在端口映射情况下,服务自身很难知道自己对外暴露的真实的服务 IP 和端口。而外部应用也无法通过服务所在容器的私有 IP 地址和端口来访问服务。
总的来说,IP-per-Pod 模型是一个简单的兼容性较好的模型。从该模型的网络的端口分配、域名解析、服务发现、负载均衡、应用配置和迁移等角度来看,Pod 都能被看作一台独立的"虚拟机" 和"物理机"。
按照这个网络抽象原则,Kubernetes 对网络有什么前提和要求呢?
Kubernetes 对集群的网络有如下要求。
(1)所有容器都可以在不用 NAT 的方式下同别的容器通信。
(2)所有节点都可以在不用 NAT 的方式下同所有容器通信,反之亦然。
(3)容器的地址和别人看到的地址是同一个地址。
这些基本的要求意味着并不是只有两台机器运行 Docker,Kubernetes 就可以工作了。具体的集群网络实现必须保障上述基本要求,原生的 Docker 网络目前还不能很友好地支持这些要求。
实际上,这些对网络模型的要求并没有降低整个网络系统的复杂度。如果你的程序原来在 VM 上运行,而那些 VM 拥有独立 IP,并且它们之间可以直接透明地通信,那么 Kubernetes 的网络模型就和 VM 使用的网络模型是一样的。所以使用这种模型可以很容易地将已有的应用程序从 VM 或物理机迁移到容器上。
当然,谷歌设计 Kubernetes 的一个主要运行基础就是其云环境GCE(Google Compute Engine),在 GCE 下这些网络要求都是默认支持的。另外,常见的其他公有云服务商如亚马逊等,在它们的公有云计算环境下也是默认支持这个模型的。
由于部署私有云的场景会更普遍,所以在私有云中运行 Kubernetes 和 Docker 集群之前,就需要自己搭建出符合 Kubernetes 要求的网络环境。
现在的开源世界有很多开源组件可以帮助我们打通 Docker 容器和容器之间的网络,实现 Kubernetes 要求的网络模型。当然每种方案都有适合的场景,要根据自己的实际需要进行选择。
2、Docker的网络基础
Docker 本身的技术依赖于近年 Linux 内核虚拟化技术的发展,所以 Docker 对Linux内核的特性有很强的依赖。
Docker使用到的与Linux网络有关的主要技术包括以下几种:
- Network Namespace
- Veth设备对
- Iptables/Netfilter
- 网桥
- 路由
2.1 网络的命名空间
为了支持网络协议栈的多个实例,Linux 在网络栈中引入了命名空间(Network Namespace),这些独立的协议栈被隔离到不同的命名空间中。处于不同命名空间的网络栈是完全隔离的,彼此之间无法通信,就好像两个 “平行宇宙”。通过这种对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。 Docker 也正是利用了网络的命名空间特性,实现了不同容器之间网络的隔离。
在 Linux 的网络命名空间内可以有自己独立的路由表及独立的 iptables/Netfilter 设置来提供包转发、NAT 及 IP 包过滤等功能。
为了隔离出独立的协议栈,需要纳入命名空间的元素有进程、套接字、网络设备等。进程创建的套接字必须属于某个命名空间,套接字的操作也需要在命名空间内进行。同样,网络设计也必须属于某个命名空间。因为网络设备属于公共资源,所以可以通过修改属性实现在命名空间之间移动。当然,是否允许移动和设备的特征有关。
让我们稍微深入 Linux 操作系统内部,看它是如何实现网络命名空间的,这也会对理解后面的概念有帮助。
2.1.1 网络命名空间的实现
Linux 的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须修改为协议栈私有。最好的办法就是让这些全局变量称为一个 Net Namespace 全量的成员,然后为协议栈的函数调用加入一个 Namespace 参数。这就是 Linux 实现网络命名空间的核心。
同时,为了保证对自己开发的应用程序及内核代码的兼容性,内核代码隐式地使用了命名空间内的变量。我们的程序如果没有对命名空间的特殊要求,那么不需要写额外的代码,网络命名空间对应用程序而言是透明的。
在建立了新的网络命名空间,并将某个进程关联到这个网络命名空间后,就出现了类似于下图的内核数据结构,所有网络栈变量都放入了网络命名空间的数据结构中。这个网络命名空间是数据它的进程组素有的,和其他进程组不冲突。

新生成的私有命名空间只有回环 lo 设备(而且是停止状态),其他设备默认都不存在,如果我们需要,则要一一手工建立。Docker 容器中的各类网络栈设备都是 Docker Daemon 在启动时自动创建和配置的。
所有的网络设备(物理的或虚拟接口、桥等在内核里叫做 Net Device)都只能属于一个命名空间。当然,通常物理的设备(连接实际硬件的设备)只能关联到 root 这个命名空间中。虚拟的网络设备(虚拟的以太网接口或者虚拟接口对)则可以被创建并关联到一个给定的命名空间中,并且可以在这些命名空间之间移动。
前面提到,由于命名空间代表的是一个独立的协议栈,所以它们之间是相互隔离的,彼此无法通信,在协议栈内部都看不到对方。那么这有没有办法打破这种限制,让处于不同命名空间的网络互相通信,甚至和外部的网络进行通信呢?答案就是 “Veth 设备对”。Verh 设备对 的一个主要作用就是打通互相看不到的协议栈之间的堡垒,它就像一个管子,一端连接着这个网络命名空间的协议栈,一端连接另一个命名空间的协议栈。所以如果想在两个命名空间之间进行通信,就必须有一个 Veth 设备对。
2.1.2 网络命名空间操作
下面举例一些网络命名空间的操作。
可以使用 Linux iproute2 系列配置工具中的 IP 命令来操作网络命名空间。注意,这个命令需要由 root 用户运行。
创建一个命名空间:
$ ip netns add <name>
在命名空间内执行命令:
$ ip netns exec <name> <command>
如下想执行多个命令,则可以先进入内部的 sh,然后执行:
$ ip netns exec <name> bash
之后就是在新的命名空间内进行操作了。退出到外面的命名空间时,请输入 “exit”。
2.1.3 网络命名空间的一些技巧
操作网络命名空间时的一些实用技巧如下:
- 可以在不同的网络命名空间之间转移设备,如下面会提到的 Veth 设备对的转移。因为一个设备只能属于一个命名空间,所以转移后在这个命名空间内就看不到这个设备了。具体哪些设备能够转移到不同的命名空间呢?在设备里面有一个重要的属性:NETIF_F_ETNS_LOCAL,如果这个属性为 “on”,则不能转移到其他命名空间内。
- Veth 设备属于可以转移的设备,而很多其他设备如 lo 设备、vxlan 设备、ppp 设备、bridge 设备等都是不可以转移的。
将无法转移的设备移动到别的命名空间的操作,则会得到无效参数的错误提示。
$ ip link set br0 netns ns1
RENETLINK answers: Invalid argument
如何知道这些设备是否可以转移呢?可以使用 ethtool 工具查看:
$ ethtool -k br0
netns-local: on [fixed]
netns-local 的值是 on,就说明不可以转移,否则可以。
2.2 Veth设备对
引入 Veth 设备对是为了在不同的网络命名空间之间进行通信,利用它可以直接将两个网络命名空间连接起来。由于要连接两个网络命名空间,所以 Veth 设备都是成对出现的,很像一对以太网卡,并且中间有一根直连的网线。既然是一对网卡,那么将其中一端称为另一端的 peer。在 Veth 设备的一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作。
整个 Veth 的实现非常简单,有兴趣的可以参考代码 “drivers/net/veth.c” 的实现。

Veth 设备对的操作命令
接下来看看如何创建 Veth 设备对,如果连接到不同的命名空间,并设置它们的地址,让它们通信。
创建 Veth 设备对:
$ ip link add veth0 type veth peer name veth1
创建后,可以查看 Veth 设备对的信息。使用下面的命令查看所有网络接口:
$ ip link show
...
21: vetn1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 9a:34:2f:43:57:c1 brd ff:ff:ff:ff:ff:ff
22: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether be:0f:f6:97:6d:77 brd ff:ff:ff:ff:ff:ff
...
有了两个设备生成,一个是 veth0,它的 peer 是 veth1。
现在这两个设备都在自己的命名空间内,那怎么能行呢?如果将 Veth 看做两个头的网线,那么将另一个头甩给另一个命名空间把:
$ ip netns add netns1
$ ip link set veth1 netns netns1
这是可在外面这个命名空间内看两个设备的情况:
$ ip link show
...
7: vboxnet0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 0a:00:27:00:00:00 brd ff:ff:ff:ff:ff:ff
...
只剩一个 veth0 设备了,已经看不到另一个设备了,另一个设备已经转移到另一个网络命名空间了。
在 netns1 网络命名空间中可以看到 veth1 设备了,符合预期
$ ip netns exec netns1 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
23: veth1@if24: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 0e:61:65:ec:6a:69 brd ff:ff:ff:ff:ff:ff link-netnsid 0
现在看到的结果是,两个不同的命名空间各自有一个 Veth 的 “网线头”,各显示一个 Device(在 Docker 的实现里面,它除了将 Veth 放入容器内,还将它的名字改成了 eth0,简直以假乱真,你以为它是一个本地网卡么)。
现在可以通信了么?不行,因为它们还没有任何地址,现在来给它们分配 IP 地址把:
$ ip netns exec netns1 ip addr add 10.1.1.1/24 dev veth1
$ ip addr add 10.1.1.2/24 dev veth0
再启动它们:
$ ip netns exec netns1 ip link set dev veth1 up
$ ip link set dev veth0 up
现在两个网络命名空间可以互相通信了:
$ ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.060 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.056 ms
^C
--- 10.1.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1006ms
rtt min/avg/max/mdev = 0.056/0.058/0.060/0.002 ms
$ ip netns exec netns1 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.068 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.058 ms
64 bytes from 10.1.1.2: icmp_seq=3 ttl=64 time=0.059 ms
^C
--- 10.1.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.058/0.061/0.068/0.010 ms
至此,两个网络命名空间之间就完全通了。
至此就能够理解 Veth 设备对的原理和用法了。在 Docker 内部,Veth 设备对也是联系容器到外面的重要设备,离开它是不行的。
Veth 设备对如何查看对端
在操作 Veth 设备对时有一些实用技巧,如下所示。
一旦将 Veth 设备对的 peer 端放入另一个命名空间,我们在本命名空间内就看不到她了。那么我们怎么知道这个 Veth 对的对端在哪里呢,也就是说它到底连接到哪个别名的命名空间呢?可以使用 ethtool 工具来查看(当网络命名空间特别多时,这可不是一件很容易的事情)。
首先在一个命名空间中查询 Veth 设备对端接口在设备列表中的序列号:
$ ip netns exec netns1 ethtool -S veth1
NIC statistics:
peer_ifindex: 117
得知另一端的接口设备的序列号是 117,再到另一个命名空间中查看序列号 117 代表什么设备:
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 00:16:3e:06:a2:b3 brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:a5:6f:64:06 brd ff:ff:ff:ff:ff:ff
...
117: veth0@if116: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 9a:c9:43:a7:42:a4 brd ff:ff:ff:ff:ff:ff link-netnsid 2
现在找到了下标为 117 的设备了,它就是 Veth0,它的另一端自然就是另一个命名空间中的 veth1 了,因为他们互为 peer。
3、 网桥
Linux 可以支持很多不同的端口,这些端口之间可以进行通讯,这就是网桥的功能,网桥是一个二层网络设备,可以解析收发的报文,读取目标 MAC 地址的信息,和自己记录的 MAC 表结合,来决策报文的转发端口。为了实现这些功能,网桥会学习源 MAC 地址(二层网桥转发的依据就是 MAC 地址)。在转发报文的时候,网桥只需要向特定的网络接口进行转发,从而避免不必要的网络交互。如果它遇到一个自己从未学习到的地址,就无法知道这个报文应该从哪个网口设备转发,于是只好将报文广播给所有的网络设备端口(报文来源的端口除外)。
在实际网络中,网络拓扑不可能永久不变,如果设备移动到一个端口上,而它没用发送任何数据,那么网桥设备就无法范知道这个变化,结果网桥还是向原来的端口转发数据包,在这种情况下数据就会丢失,所以网络还要对学习到的 MAC 地址表加上超时时间(默认为5 分钟)。如果网桥收到了对应端口 MAC 地址返回的包,则重设超时时间,否则过了超时时间后,就认为这个设备已经不在那个端口上了,就会重新发送广播。
在 Linux 的内部网络栈里面实现的网桥设备,作用和上面的描述相同。过去 Linux 主机一般都是只有一个网卡,对于接收到的报文,要不转发,要不丢弃。运行着 Linux 内核的机器本身更就是一台主机,有可能是网络报文的目的地,其收到的报文除了转发和丢弃,还可能被发送到网络协议栈的上层(网络层),从而被自己(这台主机本身的协议栈)消化,所以我们
既可以把网桥看做一个二层设备,也可以看作一个三层设备。
3.1 Linux 网桥的实现
Linux 内核时通过一个虚拟的网桥设备(Net Device)来实现桥接的。这种虚拟设备可以绑定若干个以网络桥接设备,从而将它们桥接起来。如下图,这种 Net Device 网桥和普通的设备不同,最明显的一个特性是它还可以有一个 IP 地址。

上图中,网桥设备 br0 绑定了 eth0 和 eth1.对于网络协议栈的上层来说,只看得到 br0。因为桥接是在数据链路层实现的,上层不需要关心网桥的细节,于是协议栈上层需要发送的报文被送到 br0,网桥设备的处理代码判断报文被转发到 eth0 还是 eth1,或者两者皆转发;反过来,从 eth0 或者从 eth1 接收到的报文被提交给网桥的处理代码,在这里会判断报文应该被转发、丢弃还是提交到协议栈上层。
而有时 eth0、eth1 也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收,从而绕过网桥。
网桥的常用操作命令
Docker 自动完成了对网桥的创建和维护。为了进一步理解网桥,下面举几个常用的网桥操作例子,对网桥进行手工操作:
新增一个网桥设备:
$ brctl addbr xxx
之后可以为网桥增加网口,在 Linux 中,一个网口其实就是一个物理网卡。将物理网卡和网桥连接起来:
$ brctl addif xxx ethx
网桥的物理网卡作为一个网口,由于在链路层工作,就不在需要 IP 地址了,这样上面的 IP 地址自然失效:
$ ifconfig ethx 0.0.0.0
给网桥配置一个 IP 地址:
$ ifconfig brxxx xxx.xxx.xxx.xxx
这样网桥就有了一个 IP 地址,而连接到上面的网卡就是一个纯链路层设备了。
3.2 Iptables/Netfilter
我们知道,Linux 网络协议栈非常高效,同时比较复杂。如果我们希望在数据的处理过程中对关心的数据进行一些操作该怎么做呢?Linux 提供了一套机制来为客户端实现自定义的数据包处理过程。
在 Linux 网络协议栈中有一组回调函数挂节点,通过这些挂载点挂接的钩子函数可以再 Linux 网络栈处理数据包的过程中对数据包进行一些操作,如过滤、修改、丢弃等,整个挂接点数据叫做 Netfiler 和 Iptables。
Netfilter 负责在内核中执行各种挂接的规则,运行在内核模式中;而 Iptables 是在用户模式下运行的进程,负责协助维护内核中 Netfilter 的各种规则表,通过二者的配合来实现整个 Linux 网络协议栈中灵活的数据包处理机制。
Netfilter 可以挂接的规则有5个:

规则表 Table
这些挂接点能挂接的规则也分不同的类型(也就是规则表),我们可以在不同类型的 Table 中加入我们的规则,目前主要支持的 Table 类型为:
- RAW;
- MANGLE;
- NAT
- FILTER
优先级最高的是 RAW,最低的是 FILTER。
在实际应用中,不同的挂接点需要的规则类型通常不同,例如,在 Input 的挂接点上明显不需要 FILTER 过滤规则,因为根据目标地址,已经选择好本机的上层协议栈了,所以无需挂接 FILTER 过滤规则。目前
Liunx 系统支持不同的挂接点能挂接的规则如图:

当 Linux 协议栈的数据处理运行到挂接点时,它会一次调用挂接点上所有的挂钩函数,直到数据包的处理结果明确的接受或拒绝。
处理规则
每个规则的特性都分为以下几个部分:
- 表类型(准备干什么事情);
- 什么挂接点(什么时候起作用);
- 匹配的参数是什么(针对什么样的数据包);
- 匹配后有什么动作(匹配后具体的操作是什么)。
(1)匹配的参数
匹配的参数用于对数据包或者 TCP 数据连接的状态进行匹配,当有多个条件存在时,他们一起起作用,来达到只针对某部分数据进行修改的目的,常见参数有:
- 流入、流出的网络接口;
- 来源、目的地址;
- 协议类型;
- 来源、目的端口。
(2)匹配后的动作
一旦有数据匹配上,就会执行相应的动作。动作类型既可以是标准的预定义的几个动作,也可以是自定义的模块注册的动作,或者是新的规则链,以便更好的组织一组动作。
Iptables 命令
Iptables 命令用于协助用户维护各种规则,我们在使用 Docker、Kubernetes 的过程中,通常都回去查看相关的 Netfilter 配置。
查看系统的规则方法:
- iptables-save:按照命令的方式打印 Iptables 的内容。
- iptables-vnL:以格式显示 Netfilter 表的内容。
3.3 路由
Linux 系统包含一个完整的路由功能,当 IP 层在处理数据发送或者转发的时候,会使用路由表来决定发往哪里。通常情况下,如果主机与目的主机直接相连,那么主机可以直接发送 IP 报文到目的主机,这个过程比较简单。例如,通过点对点的链接或通过网络共享,如果主机与目的主机没用直接相连,那么主机会将 IP 报文发送给默认的路由,然后由路由器来决定往哪发送 IP 报文。
路由功能有 IP 层维护的一张路由表来实现。当主机接收到的数据报文时,它用此表来决策接下来应该做什么操作。当从网络侧接受到数据报文时,IP 层首先会检查报文的 IP 地址是否与主机自身的地址相同,如果数据报文中的 IP 地址是主机自身的地址,那么报文将被发送到传输层相应的协议中去。如果报文中的 IP 地址不是主机自身的地址,并且主机配置了路由功能,那么报文将被战法,否则,报文将被丢弃。
路由表中的数据一般是以条目形式存在的。
一个典型的路由表条目通常包含以下重要的条目项:
- (1)目的 IP 地址:此字段表示目标的 IP 地址。这个 IP 地址可以是某台主机的地址,也可以是一个网络地址,如果这条目包含的一个主机地址,那么它的主机 ID 将被标记为非零;如果这条目包含的是一个网络地址,那么它的主机 ID 被标记为零。
- (2)下一条路由器的 IP 地址:为什么采用 下一个 的说法呢,是因为下一个路由器并不总是最终的目的路由器,它很可能是一个中间的路由器。条目给出下一个路由器的地址用来转发从相应接口接手到的 IP 数据报文。
- (3)标志:这个字段提供了另一组重要信息,例如目的 IP 地址是一个主机地址还是一个网络地址,此外,从标志中可以得知下一个路由器是一个真实路由器还是一个直接相连的路由器。
- (4)网络接口范围:为一些数据报文的网络接口范围,该范围将于报文一起被转发。
在通过路由表转发时,如果任何条目的第一个字段完全匹配目的 IP 地址(主机)或部分匹配条目的 IP地址(网络),那么它将指示下一个路由器的 IP 地址。这是一个重要的信息,因为这些信息直接告诉主机(具备路由功能的)数据包应该转发到哪个“下一个路由器”去。而条目中的所有其他字段将提供更多的辅助信息来为路由转发做决定。
如果没有找到一个完全匹配的IP,那么就接着搜索相匹配的网络 ID,如果找到,那么该数据报文会被转发到指定的路由器上。可以看出,网络上的所有主机都通过这个路由表中的单个条目进行管理。
如果上述两个条件都不匹配,那么该数据报文将被转发到一个默认路由上。如果上述操作失败,默认路由也不存在,那么该数据报文最终无法被转发。任务无法投递的数据报文都将产生一个 ICMP 主机不可达或者 ICMP 网络不可达的错误,并将此错误返回给生成此数据报文的应用程序。
路由表的创建
Linux 的路由表至少包括两个表(当启用策略路由的时候,还会有其他表):一个是 LOCAL,另一个是 MAIN。
在 LOCAL 表中会包含所有的本机设备地址。LOCAL 路由表是配置网络设备地址时自动创建的。LOCAL 表用于提供 Linux 协议栈识别本机地址,以及进行本地各个不同网络接口之间的数据转发。
可以通过下面的命令进行查看 LOCAL 表的内容:
$ ip route show table local type local
127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
172.17.0.1 dev docker0 proto kernel scope host src 172.17.0.1
192.168.130.11 dev em1 proto kernel scope host src 192.168.130.11
MAIN 表用于各类网络 IP 地址的转发,它的建立即可以使用静态配置生成,也可以使用动态路由发现协议生成。动态路由发现协议一般使用组播功能来通过发送路由发现数据,动态的交换和获取网络的路由信息,并更新到路由表中。
Linux 下支持路由发现协议的开源软件有很多,常用的有 Quagga、Zebra 等。
路由表的查看
查看路由表的信息:
$ ip r
default via 192.168.130.1 dev em1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.130.0/24 dev em1 proto kernel scope link src 192.168.130.11 metric 100
上面的例子代码中,源地址是 192.168.130.11 是本机地址,目标地址是 192.168.130.0/24 网段的数据,通过对应的 em1设备发送出去。
Netstat -rn 是另外一个查看路由表额工具:
$ netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
0.0.0.0 192.168.130.1 0.0.0.0 UG 0 0 0 em1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.130.0 0.0.0.0 255.255.255.0 U 0 0 0 em1
在它显示的信息中,如果标志是 U,则说明是可达路由;如果标志是 G,则说明这个网络接口连接的是网关,否则说明是直连主机。
3.4 Docker 的网络实现
标准的 Docker 支持一下 4 类网络模式。
- host 模式:使用 --net=host 指定。
- container 模式:使用 --net=container:NAME_or_ID 指定。
- none 模式:使用 --net=none 指定。
- bridge 模式:使用 --net=bridge 指定,为默认设置。
在 Kubernetes 管理模式下,通常只会使用 bridge 模式。
在 bridge 模式下,Docker Daemon 第 1 次启动时会创建一个虚拟的网桥,默认的名字是 docker0,然后按照 RPC1918 的模型,在私有网络空间中给这个网桥分配一个子网。针对由 Docker 创建出来的每一个容器,都会创建一个虚拟的以太网设备(Veth 设备对),其中一端关联到网桥上,另一端使用 Linux 的网络命名空间技术,映射到容器内的 eth0 设备,然后从网桥的地址段内给 eth0 接口分配一个 IP 地址。
如下图,就是 Docker 的默认桥接网络模型。

其中 ip1 是网桥的 IP 地址,Docker Daemon 会在几个备选地址段给它选择一个,通常是 172 开头的一个地址。这个地址和主机的 IP 地址是不重叠的。ip2 是 Docker 给启动容器时,在这个网址段随机选择的一个没有使用的 IP 地址,Docker 占用它并分配给了被启动的容器。相应的 MAC 地址也根据这个 IP 地址,在 02:42:ac:11:00:00 和 02:42:ac:11:ff:ff 的范围内生成,这样做可以确保不会有 ARP 的冲突。
启动后,Docker 还将 Veth 对的名字映射到了 eth0 网络接口。ip3 就是主机的网卡地址。
在一般情况下,ip1、ip2 和 ip3 是不同的 IP 端,所以在默认不做任何特殊配置的情况下,在外部是看不到 ip1 和 ip2 的。
这样做的结果就是,同一台机器内的容器之间可以互相通信。不同主机上的容器不能够相互通信。实际上它们甚至可能会在相同的网络地址范围内(不同的主机上的 docker0 的地址段可能是一样的)。
为了让它们跨节点互相通信,就必须在主机的地址上分配端口,然后通过这个端口路由或代理到容器上。这种做法显然意味着一定要在容器之间小心谨慎的协调好端口的分配,或者使用动态端口的分配技术。在不同应用之间协调好端口分配是十分困难的事情,特别是集群水平扩展时。而动态的端口分配也会带来高度复杂性,例如:每个应用程序都只能将端口看做一个符号(因为是动态分配的,无法提前设置)。而且 API Server 也要在分配完后,将动态端口插入到配置合适位置。另外,服务也必须能互相之间找到对方等。这些都是 Docker 的网络模型在跨主机访问时面临的问题。
3.5 查看 Docker 启动后的系统情况
Docker 网络在 bridge 模式下 Docker Daemon 启动时创建 docker0 网桥,并在网桥使用的网段为容器分配 IP。来看看实际的操作。
在刚刚启动 Docker Daemon 并且还没有启动任何容器时,网络协议栈的配置情况如下:
[root@bogon yum.repos.d]# systemctl start docker
[root@bogon yum.repos.d]#
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:3e:68:21 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.13/24 brd 10.0.2.255 scope global dynamic enp0s3
valid_lft 968sec preferred_lft 968sec
inet6 fe80::aabc:4d16:c1d7:4ce5/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:37:60:da:71 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
[root@bogon yum.repos.d]#
[root@bogon yum.repos.d]#
iptables-save
# Generated by iptables-save v1.4.21 on Tue May 15 09:39:39 2018
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [1:68]
:POSTROUTING ACCEPT [1:68]
:DOCKER - [0:0]
:OUTPUT_direct - [0:0]
:POSTROUTING_ZONES - [0:0]
:POSTROUTING_ZONES_SOURCE - [0:0]
:POSTROUTING_direct - [0:0]
:POST_public - [0:0]
:POST_public_allow - [0:0]
:POST_public_deny - [0:0]
:POST_public_log - [0:0]
:PREROUTING_ZONES - [0:0]
:PREROUTING_ZONES_SOURCE - [0:0]
:PREROUTING_direct - [0:0]
:PRE_public - [0:0]
:PRE_public_allow - [0:0]
:PRE_public_deny - [0:0]
:PRE_public_log - [0:0]
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT -j OUTPUT_direct
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -j POSTROUTING_direct
-A POSTROUTING -j POSTROUTING_ZONES_SOURCE
-A POSTROUTING -j POSTROUTING_ZONES
-A DOCKER -i docker0 -j RETURN
-A POSTROUTING_ZONES -o enp0s3 -g POST_public
-A POSTROUTING_ZONES -g POST_public
-A POST_public -j POST_public_log
-A POST_public -j POST_public_deny
-A POST_public -j POST_public_allow
-A PREROUTING_ZONES -i enp0s3 -g PRE_public
-A PREROUTING_ZONES -g PRE_public
-A PRE_public -j PRE_public_log
-A PRE_public -j PRE_public_deny
-A PRE_public -j PRE_public_allow
COMMIT
# Completed on Tue May 15 09:39:39 2018
# Generated by iptables-save v1.4.21 on Tue May 15 09:39:39 2018
*mangle
:PREROUTING ACCEPT [23419:53674571]
:INPUT ACCEPT [23417:53673419]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [22948:1257833]
:POSTROUTING ACCEPT [22948:1257833]
:FORWARD_direct - [0:0]
:INPUT_direct - [0:0]
:OUTPUT_direct - [0:0]
:POSTROUTING_direct - [0:0]
:PREROUTING_ZONES - [0:0]
:PREROUTING_ZONES_SOURCE - [0:0]
:PREROUTING_direct - [0:0]
:PRE_public - [0:0]
:PRE_public_allow - [0:0]
:PRE_public_deny - [0:0]
:PRE_public_log - [0:0]
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A INPUT -j INPUT_direct
-A FORWARD -j FORWARD_direct
-A OUTPUT -j OUTPUT_direct
-A POSTROUTING -j POSTROUTING_direct
-A PREROUTING_ZONES -i enp0s3 -g PRE_public
-A PREROUTING_ZONES -g PRE_public
-A PRE_public -j PRE_public_log
-A PRE_public -j PRE_public_deny
-A PRE_public -j PRE_public_allow
COMMIT
# Completed on Tue May 15 09:39:39 2018
# Generated by iptables-save v1.4.21 on Tue May 15 09:39:39 2018
*security
:INPUT ACCEPT [23380:53671859]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [22962:1258985]
:FORWARD_direct - [0:0]
:INPUT_direct - [0:0]
:OUTPUT_direct - [0:0]
-A INPUT -j INPUT_direct
-A FORWARD -j FORWARD_direct
-A OUTPUT -j OUTPUT_direct
COMMIT
# Completed on Tue May 15 09:39:39 2018
# Generated by iptables-save v1.4.21 on Tue May 15 09:39:39 2018
*raw
:PREROUTING ACCEPT [23419:53674571]
:OUTPUT ACCEPT [22948:1257833]
:OUTPUT_direct - [0:0]
:PREROUTING_ZONES - [0:0]
:PREROUTING_ZONES_SOURCE - [0:0]
:PREROUTING_direct - [0:0]
:PRE_public - [0:0]
:PRE_public_allow - [0:0]
:PRE_public_deny - [0:0]
:PRE_public_log - [0:0]
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A OUTPUT -j OUTPUT_direct
-A PREROUTING_ZONES -i enp0s3 -g PRE_public
-A PREROUTING_ZONES -g PRE_public
-A PRE_public -j PRE_public_log
-A PRE_public -j PRE_public_deny
-A PRE_public -j PRE_public_allow
COMMIT
# Completed on Tue May 15 09:39:39 2018
# Generated by iptables-save v1.4.21 on Tue May 15 09:39:39 2018
*filter
:INPUT ACCEPT [0:0]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [31:3924]
:DOCKER - [0:0]
:DOCKER-ISOLATION - [0:0]
:FORWARD_IN_ZONES - [0:0]
:FORWARD_IN_ZONES_SOURCE - [0:0]
:FORWARD_OUT_ZONES - [0:0]
:FORWARD_OUT_ZONES_SOURCE - [0:0]
:FORWARD_direct - [0:0]
:FWDI_public - [0:0]
:FWDI_public_allow - [0:0]
:FWDI_public_deny - [0:0]
:FWDI_public_log - [0:0]
:FWDO_public - [0:0]
:FWDO_public_allow - [0:0]
:FWDO_public_deny - [0:0]
:FWDO_public_log - [0:0]
:INPUT_ZONES - [0:0]
:INPUT_ZONES_SOURCE - [0:0]
:INPUT_direct - [0:0]
:IN_public - [0:0]
:IN_public_allow - [0:0]
:IN_public_deny - [0:0]
:IN_public_log - [0:0]
:OUTPUT_direct - [0:0]
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -j INPUT_direct
-A INPUT -j INPUT_ZONES_SOURCE
-A INPUT -j INPUT_ZONES
-A INPUT -m conntrack --ctstate INVALID -j DROP
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j DOCKER-ISOLATION
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -i lo -j ACCEPT
-A FORWARD -j FORWARD_direct
-A FORWARD -j FORWARD_IN_ZONES_SOURCE
-A FORWARD -j FORWARD_IN_ZONES
-A FORWARD -j FORWARD_OUT_ZONES_SOURCE
-A FORWARD -j FORWARD_OUT_ZONES
-A FORWARD -m conntrack --ctstate INVALID -j DROP
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
-A OUTPUT -j OUTPUT_direct
-A DOCKER-ISOLATION -j RETURN
-A FORWARD_IN_ZONES -i enp0s3 -g FWDI_public
-A FORWARD_IN_ZONES -g FWDI_public
-A FORWARD_OUT_ZONES -o enp0s3 -g FWDO_public
-A FORWARD_OUT_ZONES -g FWDO_public
-A FWDI_public -j FWDI_public_log
-A FWDI_public -j FWDI_public_deny
-A FWDI_public -j FWDI_public_allow
-A FWDI_public -p icmp -j ACCEPT
-A FWDO_public -j FWDO_public_log
-A FWDO_public -j FWDO_public_deny
-A FWDO_public -j FWDO_public_allow
-A INPUT_ZONES -i enp0s3 -g IN_public
-A INPUT_ZONES -g IN_public
-A IN_public -j IN_public_log
-A IN_public -j IN_public_deny
-A IN_public -j IN_public_allow
-A IN_public -p icmp -j ACCEPT
-A IN_public_allow -p tcp -m tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
COMMIT
# Completed on Tue May 15 09:39:39 2018
[root@bogon yum.repos.d]#
可以看到,Docker 创建了 docker0 网桥,并添加了 Iptable 规则。docker0 网桥和 Iptables 规则都处于 root 命名空间中。通过解读这些规则,发现即便还没有启动任何容器,但如果已经启动了 Docker Daemon,那么它就已经做好了通信的准备。
对这些规则的说明如下:
(1)在 NAT 表这条记录表明,发往本地网络服务地址的数据包都会执行 DOCKER 链。
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
(2)NAT 表这一条的含义是,若本地发出的数据包不是发往 docker0 的,即是发往主机之外的设备的,都需要进行动态地址修改(MASQUERADE),将源地址从容器的地址(172 段)修改为宿主机网卡的 IP 地址,之后就可以发送给外面的网络了。
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
(3)在 FILTER 表中,这一条是一个框架,目前状态的 DOCKER 链还是空的。
-A FORWARD -o docker0 -j DOCKER
(4)在 FILTER 表中,这一条是说,docker0 发出的包,如果需要 Forward 到非 docker0 的本地 IP 地址的设备,则是允许的,这样,docker0 设备的包就可以根据路由规则中转到宿主机的网卡设备,从而访问外面的网络。
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
(5)在 FILTER 表中,这一条是说,docker0 的包还可以中转给 docker0 本身,即连接在 docker0 网桥上的不同容器之间的通信也是允许的。
-A FORWARD -i docker0 -o docker0 -j ACCEPT
(6)在 FLITER 表中,这一条是说,如果接受到的数据包属于以前已经创建好的连接,那么继续允许通过。这样接受到的数据包自然又走回 docker0,并中转到相应的容器。
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
(7)在 FLITER 表中Docker-isolation链用于放置限制不同容器网络之间的访问的规则。在docker network create命令中的icc=false选项的作用是会阻止同一网络上的容器彼此通信。这就是在下面的前向链中添加一个丢弃规则来实现的。
-A FORWARD -j DOCKER-ISOLATION
3.6 查看 Docker 启动后的系统情况(容器无端口映射)
现在我们启动一个名为"example"的容器,不使用任何端口参数,观察一下网络堆栈部分的变化:
# docker run -itd --name example busybox
3a4ae8df41732354f1a2ad96ba65413d8c28b114ee63cb9e50252bd40db97f07
[root@worknode2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3a4ae8df4173 busybox "sh" 2 seconds ago Up 1 second example
# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:f8:aa:fd brd ff:ff:ff:ff:ff:ff
inet 10.0.2.10/24 brd 10.0.2.255 scope global dynamic enp0s3
valid_lft 792sec preferred_lft 792sec
inet6 fe80::aabc:4d16:c1d7:4ce5/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:a8:f2:2a:ea brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:a8ff:fef2:2aea/64 scope link
valid_lft forever preferred_lft forever
5: veth88d3508@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
link/ether 62:5e:01:6e:f0:4d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::605e:1ff:fe6e:f04d/64 scope link
valid_lft forever preferred_lft forever
# iptables-save
# Generated by iptables-save v1.4.21 on Tue May 22 08:44:54 2018
*filter
:INPUT ACCEPT [2207:196616]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [3893:311506]
:DOCKER - [0:0]
:DOCKER-ISOLATION - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER-ISOLATION -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Tue May 22 08:44:54 2018
# Generated by iptables-save v1.4.21 on Tue May 22 08:44:54 2018
*nat
:PREROUTING ACCEPT [1:92]
:INPUT ACCEPT [1:92]
:OUTPUT ACCEPT [911:54662]
:POSTROUTING ACCEPT [911:54662]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
COMMIT
# Completed on Tue May 22 08:44:54 2018
# ip route
default via 10.0.2.1 dev enp0s3 proto static metric 100
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.10 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
可看到如下情况。
(1)宿主机上的 Netfilter 和路由表都没有变化,说明在不进行端口映射时,Docker 的默认网络是没有特殊处理的。相关的 NAT 和 FILTER 两个 Netfilter 链还是空的。
(2)宿主机上的 Veth 对已经建立,并连接到了容器内。
再次进入刚刚启动的容器内,看看网络栈是什么情况。容器内部的 IP 地址和路由如下:
# docker attach example
/ # ip route
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 scope link src 172.17.0.2
/ #
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
4: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ #
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:16 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1296 (1.2 KiB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ #
可以看到,默认停止的回环设备 lo 已经被启动,外面宿主机连接进来的 Veth 设备也被命名成了 eth0,并且已经配置了地址 172.17.0.2。
路由信息表包含一条到 docke0 的子网路由和一条到 docker0 的默认路由。
3.7 查看容器启动后的情况(容器有端口映射)
下面,用带有端口映射的命令启动 example:
# docker run --name example2 -itd -p 1180:5000 busybox
000eac3c8e24396ada2f66ae3e07c3ec061cb9e181134db15b3fabc0810af98f
在启动后查看 Iptables 的变化:
# iptables-save
# Generated by iptables-save v1.4.21 on Tue May 22 09:17:52 2018
*filter
:INPUT ACCEPT [158:13188]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [228:19120]
:DOCKER - [0:0]
:DOCKER-ISOLATION - [0:0]
:DOCKER-USER - [0:0]
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 5000 -j ACCEPT
-A DOCKER-ISOLATION -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Tue May 22 09:17:52 2018
# Generated by iptables-save v1.4.21 on Tue May 22 09:17:52 2018
*nat
:PREROUTING ACCEPT [1:576]
:INPUT ACCEPT [1:576]
:OUTPUT ACCEPT [47:3088]
:POSTROUTING ACCEPT [47:3088]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 5000 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 1180 -j DNAT --to-destination 172.17.0.2:5000
COMMIT
# Completed on Tue May 22 09:17:52 2018
从新增的规则可以看出,Docker 服务在 NAT 和 FILTER 两个表内添加的两个 DOCKER 子链都是给端口映射用的。例如本例中需要把外面宿主机的 1180 端口映射到容器的 5000 端口。通过前面的分析我们知道,无论是宿主机接收到的还是宿主机本地协议栈发出的,目标地址是本地 IP 地址的包都会经过 NAT 表中的 DOCKER 子链。Docker 为每一个端口映射都在这个链上增加了到实际容器目标地址和目标端口的转换。
经过这个 DNAT 的规则修改后的 IP 包,会重新经过路由模块的判断进行转发。由于目标地址和端口已经是容器的地址和端口,所以受自然就送到了 docker0 上,从而送到对应的容器内部。
当然在 Forward 时,也需要在 Docker 子链中添加一条规则,如果目标端口和地址是指定容器的数据,则允许通过。
在 Docker 按照端口映射的方式启动容器时,主要的不同就是上述 Iptables 部分。而容器内部的路由和网络设备,都和不做端口映射时一样,没有任何变化。
3.8 Docker 的网络局限
从 Docker 对 Linux 网络协议栈的操作可以看到,Docker 一开始没有考虑到多主机互联的网络解决方案。
Docker 一直以来的理念都是 “简单为美”,几乎所有尝试 Docker 的人,都被它 “用法简单,功能强大” 的特性所吸引,这也是 Docker 迅速走红的一个原因。
我们知道,虚拟化技术中最复杂的部分就是虚拟化网络技术,即使是单纯的物理网络部分,也是一个门槛很高的技术领域,通常只被少数网络工程师所掌握,所以我们可以理解,结合了物理网络的虚拟网络技术有多难了。在 Docker 之前,所有接触过 OpenStack 的人的心理都有一个难以释怀的阴影,那就是它的网络问题,于是,Docker 明智的避开了这个 “雷区”,让其他专业人员去用现有的虚拟化网络技术解决 Docker 主机的互联问题,以免让用户觉得 Docker 太难了,从而放弃学习和使用 Docker。
Docker 成名以后,重新开始重视网络解决方案,收购了一家 Docker 网络解决方案攻速—— Socketplane,原因在于这家公司的产品广受好评,但有趣的是 Sockeplane 的方案就是以 Open vSwitch 为核心的,其还为 Open vSwitch 提供了 Docker 镜像,以方便部署程序。之后,Docker 启动了一个 “宏伟” 的虚拟化解决方案—— Libnetwork,如下概念图:

这个概念图没有了 IP,也没有了路由,已经垫付了我们的网络常识了,对于不怎么懂网络的大多数人来说,它的确很有诱惑力,为了是否对于虚拟化网络的模型产生深远冲击还不得而知,但当前,它仅仅是 Docker 官方的一次 “尝试”。
4、Kubernetes 的网络实现
在实际的业务场景中,组件之间的管理十分复杂,提别是随着微服务理念逐步深入人心,应用部署的粒度更加细小和灵活。为了支持业务应用组件的通信联系,Kubernetes 网络的设计主要致力解决以下场景。
(1)容器到容器之间的直接通信。
(2)抽象的 Pod 到 Pod 之间的通信。
(3)Pod 到 Service 之间的通信。
(4)集群外部与内部组件之间的通信。
4.1 容器到容器的通信
在同一个 Pod 内部的容器(Pod 内的容器是不会垮宿主机的)共享同一个网络命名空间,共享一个 Linux 协议栈。所以对于网络的各类操作,就和它们在同一台机器上一样,它们甚至可以用 localhost 地址访问彼此的端口。
这么做的结果很简单、安全和高效,也能减少将已经存在的程序从物理机或者虚拟机移植到容器下运行的难度。容器技术出来之前,其实早就积累了如何在一台机器上运行一组应用程序的经验,例如,如何让端口不冲突,以及如何让客户端发现它们等。
在下图中的虚线部分就是 Node 上运行着的一个 Pod 实例。在我们的例子中,容器就是图中容器1 和容器 2。容器 1 和容器 2 共享了一个网络的命名空间,共享一个命名空间的结果就是它们好像在一台机器上运行似的,它们打开的端口不会有冲突,可以直接使用 Linux 的本地 IPC 进行通信(例如消息队列或者管道)。其实这和传统的一组普通程序运行的环境时完全一样的,传统的程序不需要针对网络做特别的修改就可以移植了。它们之间的互相访问只需要使用 localhost 就可以。例如,如果容器 2 运行的是 MySQL,那么容器 1 使用 localhost:3306 就能直接访问这个运行在容器 2 上的 MySQL 了。

4.2 Pod 之间的通信
我们看了同一个 Pod 内的容器之间的通信情况,再看看 Pod 之间的通信情况。
每一个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址通信,而且不需要使用其他发现机制,例如 DNS、Consul 或者 etcd。
Pod 容器即由可能在同一个 Node 上运行,也有可能在不同的 Node 上运行,所以通信也
分为两类:同一个 Node 内的 Pod 之间的通信和不同 Node 上的 Pod 之间的通信。
4.2.1 同一个 Node 内的 Pod 之间的通信
来看一下同一个 Node 上的两个 Pod 之间的关系:

可以看出,Pod 1 和 Pod 2 都是通过 Veth 连接在同一个 docker0 网桥上的,它们的 IP 地址 IP1、IP2 都是从 docker0 的网段上动态获取的,它们和网桥本身的 IP3 是同一个网段的。
另外,在 Pod 1、Pod 2 的 Linux 协议栈上,默认路由都是 docker0 的地址,也就是说所有非本地地址的网络数据,都会被默认发送到 docker0 网桥上,由 docker0 网桥直接中转。
综上所述,由于它们都关联在同一个 docker0 网桥上,地址段相同,所以它们之间是能直接通信的。
4.2.2 不同 Node 上的 Pod 之间的通信
Pod 的地址是与 docker0 在同一个网段内的,我们知道 docker0 网段与宿主机网卡是两个完全不同的 IP 网段,并且不同 Node 之间的通信只能通过宿主机的物理网卡进行,因此要想实现位于不同 Node 上的 Pod 容器之间的通信,就必须想办法通过主机的这个 IP 地址来进行寻址和通信。
另一方面,这些动态分配且藏在 docker0 之后的所谓 “私有” IP 地址也是可以找到的。Kubernetes 会记录所有正在运行 Pod 的 IP 分配信息,并将这些信息保存在 etcd 中(作为 Service 的 Endpoint)。这些私有 IP 信息对于 Pod 到 Pod 的通信也是十分重要的,因为我们的网络模型要求 Pod 到 Pod 使用私有 IP 进行通信。所以首先要知道这些 IP 是什么。
之前提到,Kubernetes 的网络对 Pod 的地址是平面的和直达的,所以这些 Pod 的 IP 规划也很重要,不能由冲突。只要没有冲突,我们就可以想办法在整个 Kubernetes 的集群中找到它。
综上所述,要想支持不同 Node 上的 Pod 之间的通信,就要达到两个条件:
(1)
在整个 Kubernetes 集群中对 Pod 的 IP 分配进行规划,不能有冲突;
(2)找到一种办法,将 Pod 的 IP 和所在 Node 的 IP 关联起来,通过这个关联让 Pod 可以互相访问。
根据条件 1 的要求,需要在部署 Kubernetes 时,
对 docker0 的 IP 地址进行规划,保证每一个 Node 上的 docker0 地址没有冲突。可以在规划后手工配置到每个 Node 上,或者做一个分配规则,由安装的程序自己去分配占用。例如 Kubernetes 的网络增强开源软件 Flannel 就能够管理资源池的分配。
根据条件 2 的要求,Pod 中的数据在发出时,需要有一个机制能够知道对方 Pod 的 IP 地址挂载哪个具体的 Node 上。也就是说先要找到 Node 对应宿主机的 IP 地址,将数据发送到这个宿主机的网卡上,然后在宿主机上将应用的数据转到具体的 docker0 上。一旦数据达到宿主机 Node,则那个 Node 内部的 docker0 便知道如何将数据发送到 Pod。

在上图中,IP 1 对应的是 Pod 1、IP 2 对应的是 Pod 2。Pod 1 在访问 Pod 2 时,首先要将数据从源 Node 的 eth0 发送出去,找到并到达 Node 2 的 eth0。也就是说先要从 IP 3 到 IP 4,之后才是 IP 4 到 IP 2 的递送。
在 Google 的 GEC 环境下,Pod 的 IP 管理(类似 docker0)、分配及它们之间的路由打通都是由 GCE 完成的。Kubernetes 作为主要在 GCE 上面运行的框架,它的设计是假设底层已经具备这些条件,所以它分配完地址并将地址记录下来就完成了它的工作。在实际的 GCE 环境宏,GCE 的网络组建会读取这些信息,实现具体的网络打通。
而在实际的生产中,因为安全、费用、合规等种种原因,Kubernetes 的客户不可能全部使用 Google 的 GCE 环境,所以在实际的私有云环境中,除了部署 Kubernetes 和 Docker,还需要额外的网络配置,甚至通过一些软件来实现 Kubernetes 对网络的要求。做到这些后,Pod 和 Pod 之间才能无差别地透明通信。
5、Pod和Service网络实战
本节将通过一个完整的实验,从部署一个Pod开始,一步一步地部署那些K8s的组件,来剖析k8s在网络层是如何实现及如何工作的。
本次部署使用3个节点:
- Master节点,10.0.2.15
- Node1节点,10.0.2.4 docker0网桥默认地址手动配置为:172.16.10.1/24
- Node2节点,10.0.2.5 docker0网桥默认地址手动配置为:172.16.20.1/24

k8s的网络模型要求每个Node上的容器都可以相互访问。默认的Docker网络模型提供了一个IP地址段172.17.0.0/16的docker0网桥。每个容器都会从这个子网内获得IP地址,并且将docker0网桥的IP地址(172.17.0.1)作为其默认网关。
需要注意的是Docker宿主机外面的网络不需要知道任何关于这个172.17.0.0/16的信息或者知道如何连接到它内部,因为Docker的宿主机针对容器发出的数据,在物理网卡地址后面做了IP伪装MASQUERADE。也就是说,在网络上看到的任何容器数据流都来源于那台Docker节点的物理IP地址。
这个模型便于使用,但并不完美,需要依赖端口映射的机制。
在k8s的网络模型中,每台主机上的docker0网桥都是可以被路由到的。也就是说,在部署了一个Pod时,在同一个集群内,那台主机的外面可以直接访问到那个Pod,并不需要在那台物理主机上作端口映射。
综上所述,我们可以在网络层将k8s看作一个路由器,如下图所示。

为了支持k8s网络模型,我们采取了直接路由的方式来实现,在每个Node上设置相应的静态路由项。
在Node1上:
route add -net 172.16.20.0 netmask 255.255.255.0 gw 10.0.2.5
在Node2上:
route add -net 172.16.10.0 netmask 255.255.255.0 gw 10.0.2.4
查看下Node1当前的网络及路由信息:
[root@k8s-node1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:9f:89:14 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.4/24 brd 10.0.2.255 scope global noprefixroute dynamic enp0s3
valid_lft 1190sec preferred_lft 1190sec
inet6 fe80::a00:27ff:fe9f:8914/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:88:49:29:08 brd ff:ff:ff:ff:ff:ff
inet 172.16.10.1/24 brd 172.16.10.255 scope global docker0
valid_lft forever preferred_lft forever
[root@k8s-node1 ~]# ip r
default via 10.0.2.1 dev enp0s3 proto dhcp metric 100
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.4 metric 100
172.16.10.0/24 dev docker0 proto kernel scope link src 172.16.10.1
172.16.20.0/24 via 10.0.2.5 dev enp0s3
通过以上设置,就意味着每一个新部署的容器都将使用这个Node(docker0的网桥IP)作为它的默认网关。而这些Node节点(类似路由器)都有其他docker0的路由信息,这样它们就能够相互通信了。
接下来的一些实际的案例,将演示k8s在不同的场景下其网络部分到底做了什么事情。
5.1 第1步 部署一个RC/Pod
部署的RC/Pod描述文件如下(frontend-controller.yaml):
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
labels:
name: frontend
spec:
replicas: 1
selector:
name: frontend
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: php-redis
image: kubeguide/guestbook-php-frontend
ports:
- containerPort: 80
hostPort: 80
env:
- name: GET_HOSTS_FROM
value: env
创建该RC前的Node1的网络地址与路由信息:
[root@k8s-node1 ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.16.10.1 netmask 255.255.255.0 broadcast 172.16.10.255
ether 02:42:0b:40:61:c2 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.2.4 netmask 255.255.255.0 broadcast 10.0.2.255
inet6 fe80::a00:27ff:fe9f:8914 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:9f:89:14 txqueuelen 1000 (Ethernet)
RX packets 1601 bytes 946612 (924.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1789 bytes 226746 (221.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 4 bytes 240 (240.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 240 (240.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@k8s-node1 ~]# ip r
default via 10.0.2.1 dev enp0s3 proto dhcp metric 100
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.4 metric 100
172.16.10.0/24 dev docker0 proto kernel scope link src 172.16.10.1
172.16.20.0/24 via 10.0.2.5 dev enp0s3
现在部署一下前面准备的RC/Pod配置文件,看看网络地址发生了什么变化:
# kubectl create -f frontend-controller.yaml
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
frontend-slw97 1/1 Running 1 4h 172.16.10.2 10.0.2.4
可以看到一些有趣的事情。Kubernetes为这个Pod找了一个主机10.0.2.4(Node1)来运行它。另外,这个Pod还获得了一个在Node1的docker0网桥上的IP地址。我们登录到Node1上看看发生了什么事情:
[root@k8s-node1 ~]# ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.10.1 netmask 255.255.255.0 broadcast 172.16.10.255
inet6 fe80::42:a5ff:fe13:f81b prefixlen 64 scopeid 0x20<link>
ether 02:42:a5:13:f8:1b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 648 (648.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.2.4 netmask 255.255.255.0 broadcast 10.0.2.255
inet6 fe80::a00:27ff:fe9f:8914 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:9f:89:14 txqueuelen 1000 (Ethernet)
RX packets 628 bytes 316765 (309.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 609 bytes 89047 (86.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 4 bytes 240 (240.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 240 (240.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth55f8b16: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::3480:49ff:feff:86b9 prefixlen 64 scopeid 0x20<link>
ether 36:80:49:ff:86:b9 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16 bytes 1296 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@k8s-node1 ~]# ip r
default via 10.0.2.1 dev enp0s3 proto dhcp metric 100
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.4 metric 100
172.16.10.0/24 dev docker0 proto kernel scope link src 172.16.10.1
[root@k8s-node1 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a513f81b no veth55f8b16
可以看到网络地址中新增了一个veth设备,且加入到了docker0网桥中。而网络路由信息并没的发生变化。
执行docker命令查看下Node1节点有哪些容器正在运行:
[root@k8s-node1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
07608cab2208 kubeguide/guestbook-php-frontend "apache2-foreground" 8 minutes ago Up 8 minutes k8s_php-redis_frontend-slw97_default_ab6ea9e3-6318-11e8-88a4-080027800835_1
a8bdd4d6028f gcr.io/google_containers/pause-amd64:3.0 "/pause" 8 minutes ago Up 8 minutes 0.0.0.0:80->80/tcp k8s_POD_frontend-slw97_default_ab6ea9e3-6318-11e8-88a4-080027800835_1
[root@k8s-node1 ~]#
在Node1节点上现在运行了两个容器,在我们的RC/Pod定义文件中仅仅包含了一个,那么这第2个是从哪里来的呢?
第2个看起来运行的是一个叫作google_containers/pause-amd64:3.0的镜像,而且这个容器已经有端口映射到它上面了,为什么是这样呢?
让我们深入容器内部去看一下具体原因。使用Docker的inspect命令来查看容器的详细信息,特别要关注容器的网络模型。
[root@k8s-node1 ~]# docker inspect a8bdd4d6028f|grep NetworkMode
"NetworkMode": "default",
[root@k8s-node1 ~]# docker inspect 07608cab2208|grep NetworkMode
"NetworkMode": "container:a8bdd4d6028ffd4ab60fb60cf936fcb942eed53165d8b96c892e15c4770540fc",
从上面的结果可以看到:我们检查的第1个容器是运行了"google_containers/pause-amd64:3.0"镜像的容器,它使用了Docker默认的网络模型,即bridge。而我们检查的第2个容器,也就是在RC/Pod中定义运行的php-redis容器,使用了非默认的网络配置和映射容器的模型,指定了映射目标容器为"google_containers/pause-amd64:3.0"。
一起来思考一下这个过程,为什么k8s要这么做呢?首先,一个Pod内的所有容器都需要共用同一个IP地址,这就意味着一定要使用网络的容器映射模式。然而,为什么不能只启动第1个Pod中的容器,而将第2个Pod内的容器关联到第1个容器呢?我们认为k8s从两个方面来考虑这个问题:首先,如果Pod有超过两个容器的话,则连接这些容器可能不容易;其次,后面的容器还要依赖第1个被关联的容器,如果第2个容器关联到第1个容器,且第1个容器死掉的话,第2个也将死掉。启动一个基础容器,然后将Pod内的所有容器都连接到它上面会更容易一些。因为我们只需要为基础的这个google_containers/pause容器执行端口映射规则,这也简化了端口映射的过程。所以我们启动Pod后的网络模型类似于下图。

在这种情况下,实际Pod的IP数据流的网络目标都是这个google_containers/pause容器。在上图中,虽然标识出了google_containers/pause容器将端口80的流量转发给了相关的后端工作容器。但是Pause只是逻辑上的,并没有真正这么做(转发的动作)。实际情况是,工作容器直接监听了这些端口,且是和google_containers/pause容器共享了同一个网络堆栈。这就是为什么在Pod内部实际容器的端口映射都显示到google_containers/pause容器上了。
我们可以使用docker port命令来检验一下:
[root@k8s-node1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5dba0e94318f kubeguide/guestbook-php-frontend "apache2-foreground" 16 minutes ago Up 16 minutes k8s_php-redis_frontend-slw97_default_ab6ea9e3-6318-11e8-88a4-080027800835_2
04eb1094ea2a gcr.io/google_containers/pause-amd64:3.0 "/pause" 16 minutes ago Up 16 minutes 0.0.0.0:80->80/tcp k8s_POD_frontend-slw97_default_ab6ea9e3-6318-11e8-88a4-080027800835_2
[root@k8s-node1 ~]#
[root@k8s-node1 ~]# docker port 04eb1094ea2a
80/tcp -> 0.0.0.0:80
综上所述,google_containers/pause容器实际上只是负责接管这个Pod的Endpoint,并没有做更多的事情。那么Node呢?它需要将数据流传给google_containers/pause容器吗?我们来检查一下iptables规则,看看有什么发现:
[root@k8s-node1 ~]# iptables-save
# Generated by iptables-save v1.4.21 on Wed May 30 08:56:31 2018
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:DOCKER - [0:0]
:KUBE-MARK-DROP - [0:0]
:KUBE-MARK-MASQ - [0:0]
:KUBE-NODEPORTS - [0:0]
:KUBE-POSTROUTING - [0:0]
:KUBE-SEP-OGNOLD2JUSLFPOMZ - [0:0]
:KUBE-SERVICES - [0:0]
:KUBE-SVC-NPX46M4PTMTKRN6Y - [0:0]
:OUTPUT_direct - [0:0]
:POSTROUTING_ZONES - [0:0]
:POSTROUTING_ZONES_SOURCE - [0:0]
:POSTROUTING_direct - [0:0]
:POST_public - [0:0]
:POST_public_allow - [0:0]
:POST_public_deny - [0:0]
:POST_public_log - [0:0]
:PREROUTING_ZONES - [0:0]
:PREROUTING_ZONES_SOURCE - [0:0]
:PREROUTING_direct - [0:0]
:PRE_public - [0:0]
:PRE_public_allow - [0:0]
:PRE_public_deny - [0:0]
:PRE_public_log - [0:0]
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -j OUTPUT_direct
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.16.10.0/24 ! -o docker0 -j MASQUERADE
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -j POSTROUTING_direct
-A POSTROUTING -j POSTROUTING_ZONES_SOURCE
-A POSTROUTING -j POSTROUTING_ZONES
-A POSTROUTING -s 172.16.10.2/32 -d 172.16.10.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.16.10.2:80
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
-A KUBE-SEP-OGNOLD2JUSLFPOMZ -s 10.0.2.15/32 -m comment --comment "default/kubernetes:https" -j KUBE-MARK-MASQ
-A KUBE-SEP-OGNOLD2JUSLFPOMZ -p tcp -m comment --comment "default/kubernetes:https" -m recent --set --name KUBE-SEP-OGNOLD2JUSLFPOMZ --mask 255.255.255.255 --rsource -m tcp -j DNAT --to-destination 10.0.2.15:6443
-A KUBE-SERVICES -d 10.10.10.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https" -m recent --rcheck --seconds 10800 --reap --name KUBE-SEP-OGNOLD2JUSLFPOMZ --mask 255.255.255.255 --rsource -j KUBE-SEP-OGNOLD2JUSLFPOMZ
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https" -j KUBE-SEP-OGNOLD2JUSLFPOMZ
-A POSTROUTING_ZONES -o enp0s3 -g POST_public
-A POSTROUTING_ZONES -g POST_public
-A POST_public -j POST_public_log
-A POST_public -j POST_public_deny
-A POST_public -j POST_public_allow
-A PREROUTING_ZONES -i enp0s3 -g PRE_public
-A PREROUTING_ZONES -g PRE_public
-A PRE_public -j PRE_public_log
-A PRE_public -j PRE_public_deny
-A PRE_public -j PRE_public_allow
COMMIT
# Completed on Wed May 30 08:56:31 2018
# Generated by iptables-save v1.4.21 on Wed May 30 08:56:31 2018
*mangle
:PREROUTING ACCEPT [1907:1215901]
:INPUT ACCEPT [1905:1214749]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [2155:247235]
:POSTROUTING ACCEPT [2155:247235]
:FORWARD_direct - [0:0]
:INPUT_direct - [0:0]
:OUTPUT_direct - [0:0]
:POSTROUTING_direct - [0:0]
:PREROUTING_ZONES - [0:0]
:PREROUTING_ZONES_SOURCE - [0:0]
:PREROUTING_direct - [0:0]
:PRE_public - [0:0]
:PRE_public_allow - [0:0]
:PRE_public_deny - [0:0]
:PRE_public_log - [0:0]
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A INPUT -j INPUT_direct
-A FORWARD -j FORWARD_direct
-A OUTPUT -j OUTPUT_direct
-A POSTROUTING -j POSTROUTING_direct
-A PREROUTING_ZONES -i enp0s3 -g PRE_public
-A PREROUTING_ZONES -g PRE_public
-A PRE_public -j PRE_public_log
-A PRE_public -j PRE_public_deny
-A PRE_public -j PRE_public_allow
COMMIT
# Completed on Wed May 30 08:56:31 2018
# Generated by iptables-save v1.4.21 on Wed May 30 08:56:31 2018
*security
:INPUT ACCEPT [1903:1214093]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [2155:247235]
:FORWARD_direct - [0:0]
:INPUT_direct - [0:0]
:OUTPUT_direct - [0:0]
-A INPUT -j INPUT_direct
-A FORWARD -j FORWARD_direct
-A OUTPUT -j OUTPUT_direct
COMMIT
# Completed on Wed May 30 08:56:31 2018
# Generated by iptables-save v1.4.21 on Wed May 30 08:56:31 2018
*raw
:PREROUTING ACCEPT [1907:1215901]
:OUTPUT ACCEPT [2155:247235]
:OUTPUT_direct - [0:0]
:PREROUTING_ZONES - [0:0]
:PREROUTING_ZONES_SOURCE - [0:0]
:PREROUTING_direct - [0:0]
:PRE_public - [0:0]
:PRE_public_allow - [0:0]
:PRE_public_deny - [0:0]
:PRE_public_log - [0:0]
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A OUTPUT -j OUTPUT_direct
-A PREROUTING_ZONES -i enp0s3 -g PRE_public
-A PREROUTING_ZONES -g PRE_public
-A PRE_public -j PRE_public_log
-A PRE_public -j PRE_public_deny
-A PRE_public -j PRE_public_allow
COMMIT
# Completed on Wed May 30 08:56:31 2018
# Generated by iptables-save v1.4.21 on Wed May 30 08:56:31 2018
*filter
:INPUT ACCEPT [0:0]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [7:2124]
:DOCKER - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
:FORWARD_IN_ZONES - [0:0]
:FORWARD_IN_ZONES_SOURCE - [0:0]
:FORWARD_OUT_ZONES - [0:0]
:FORWARD_OUT_ZONES_SOURCE - [0:0]
:FORWARD_direct - [0:0]
:FWDI_public - [0:0]
:FWDI_public_allow - [0:0]
:FWDI_public_deny - [0:0]
:FWDI_public_log - [0:0]
:FWDO_public - [0:0]
:FWDO_public_allow - [0:0]
:FWDO_public_deny - [0:0]
:FWDO_public_log - [0:0]
:INPUT_ZONES - [0:0]
:INPUT_ZONES_SOURCE - [0:0]
:INPUT_direct - [0:0]
:IN_public - [0:0]
:IN_public_allow - [0:0]
:IN_public_deny - [0:0]
:IN_public_log - [0:0]
:KUBE-FIREWALL - [0:0]
:KUBE-FORWARD - [0:0]
:KUBE-SERVICES - [0:0]
:OUTPUT_direct - [0:0]
-A INPUT -j KUBE-FIREWALL
-A INPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -j INPUT_direct
-A INPUT -j INPUT_ZONES_SOURCE
-A INPUT -j INPUT_ZONES
-A INPUT -m conntrack --ctstate INVALID -j DROP
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A FORWARD -m comment --comment "kubernetes forward rules" -j KUBE-FORWARD
-A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -i lo -j ACCEPT
-A FORWARD -j FORWARD_direct
-A FORWARD -j FORWARD_IN_ZONES_SOURCE
-A FORWARD -j FORWARD_IN_ZONES
-A FORWARD -j FORWARD_OUT_ZONES_SOURCE
-A FORWARD -j FORWARD_OUT_ZONES
-A FORWARD -m conntrack --ctstate INVALID -j DROP
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
-A OUTPUT -j KUBE-FIREWALL
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -j OUTPUT_direct
-A DOCKER -d 172.16.10.2/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 80 -j ACCEPT
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
-A FORWARD_IN_ZONES -i enp0s3 -g FWDI_public
-A FORWARD_IN_ZONES -g FWDI_public
-A FORWARD_OUT_ZONES -o enp0s3 -g FWDO_public
-A FORWARD_OUT_ZONES -g FWDO_public
-A FWDI_public -j FWDI_public_log
-A FWDI_public -j FWDI_public_deny
-A FWDI_public -j FWDI_public_allow
-A FWDI_public -p icmp -j ACCEPT
-A FWDO_public -j FWDO_public_log
-A FWDO_public -j FWDO_public_deny
-A FWDO_public -j FWDO_public_allow
-A INPUT_ZONES -i enp0s3 -g IN_public
-A INPUT_ZONES -g IN_public
-A IN_public -j IN_public_log
-A IN_public -j IN_public_deny
-A IN_public -j IN_public_allow
-A IN_public -p icmp -j ACCEPT
-A IN_public_allow -s 10.0.2.0/24 -j ACCEPT
-A IN_public_allow -p tcp -m tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
-A KUBE-FIREWALL -m comment --comment "kubernetes firewall for dropping marked packets" -m mark --mark 0x8000/0x8000 -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
COMMIT
# Completed on Wed May 30 08:56:31 2018
[root@k8s-node1 ~]#
上面的内容很多,实际上大部分是k8s用于自身访问管理的一些默认规则,我们可以看到有一条hostport 80端口的nat规则,将node1的80端口流量转发给了我们创建的工作容器80端口。
如果要对上面表、链中的内容有逐条的深入理解,请参照我们前面的文章《k8s技术预研9--Kubernetes核心组件运行原理分析》中关于kube-proxy组件的运行原理分析,其中有详尽的讲解。
5.2 第2步 发布一个服务
我们接下来看一下k8s是如何处理Service的。Service允许我们在多个Pod之间抽象一些服务,而且服务可以通过提供在同一个Service的多个Pod之间的负载均衡机制来支持水平扩展。
我们再次将环境初始化,删除刚刚创建的RC/Pod来确保集群是空的:
[root@k8s-master ~]# kubectl get rc
NAME DESIRED CURRENT READY AGE
frontend 1 1 1 1d
[root@k8s-master ~]# kubectl delete rc frontend
replicationcontroller "frontend" deleted
[root@k8s-master ~]#
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.10.10.1 <none> 443/TCP 6d
[root@k8s-master ~]#
[root@k8s-master ~]# kubectl get pods
No resources found.
然后准备一个名称为frontend的Service配置文件:
apiVersion: v1
kind: Service
apiVersion: v1
metadata:
name: frontend
labels:
name: frontend
spec:
selector:
name: frontend
ports:
- port: 80
创建并观察服务状态:
[root@k8s-master ~]# vi frontend-service.yaml
[root@k8s-master ~]# kubectl create -f frontend-service.yaml
service "frontend" created
[root@k8s-master ~]#
[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend ClusterIP 10.10.10.243 <none> 80/TCP 10s
kubernetes ClusterIP 10.10.10.1 <none> 443/TCP 6d
[root@k8s-master ~]# kubectl get services -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
frontend ClusterIP 10.10.10.243 <none> 80/TCP 16s name=frontend
kubernetes ClusterIP 10.10.10.1 <none> 443/TCP 6d <none>
服务正确创建后,k8s已经为这个服务分配了一个虚拟IP地址10.10.10.243,这个IP地址是在k8s的Portal Network中分配的。而这个Portal Network的地址范围则是我们在kubemaster上启动kube-api服务进程时,使用--service-cluster-ip-range=xx命令行参数指定的:
[root@k8s-master kubernetes]# cat apiserver
KUBE_API_ARGS="--storage-backend=etcd3 --etcd-servers=http://127.0.0.1:2379 --insecure-bind-address=0.0.0.0 --insecure-port=8080 --service-cluster-ip-range=10.10.10.0/24 --service-node-port-range=1-65535 --admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,DefaultStorageClass,ResourceQuota --logtostderr=true --log-dir=/var/log/kubernetes --v=2"
这个IP段可以是任何段,只要不和docker0或者物理网络的子网冲突就可以。选择任意其他网段的原因是这个网段将不会在物理网络和docker0网络上进行路由。这个Portal Network针对每一个Node都有局部的特殊性,实际上它存在的意义是让容器的流量都指向默认网关(就是docker0网桥)。
我们登录Node1节点,查看下Iptalbes/Netfilter的规则变化,仅是涉及变化的部分:
[root@k8s-node1 ~]# iptables-save
# Generated by iptables-save v1.4.21 on Thu May 31 09:09:58 2018
*nat
................
-A DOCKER -i docker0 -j RETURN
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
-A KUBE-SEP-OGNOLD2JUSLFPOMZ -s 10.0.2.15/32 -m comment --comment "default/kubernetes:https" -j KUBE-MARK-MASQ
-A KUBE-SEP-OGNOLD2JUSLFPOMZ -p tcp -m comment --comment "default/kubernetes:https" -m recent --set --name KUBE-SEP-OGNOLD2JUSLFPOMZ --mask 255.255.255.255 --rsource -m tcp -j DNAT --to-destination 10.0.2.15:6443
-A KUBE-SERVICES -d 10.10.10.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.10.10.243/32 -p tcp -m comment --comment "default/frontend: cluster IP" -m tcp --dport 80 -j KUBE-SVC-GYQQTB6TY565JPRW
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https" -m recent --rcheck --seconds 10800 --reap --name KUBE-SEP-OGNOLD2JUSLFPOMZ --mask 255.255.255.255 --rsource -j KUBE-SEP-OGNOLD2JUSLFPOMZ
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https" -j KUBE-SEP-OGNOLD2JUSLFPOMZ
................
*filter
.......................
-A KUBE-FIREWALL -m comment --comment "kubernetes firewall for dropping marked packets" -m mark --mark 0x8000/0x8000 -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-SERVICES -d 10.10.10.243/32 -p tcp -m comment --comment "default/frontend: has no endpoints" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
COMMIT
# Completed on Thu May 31 09:09:58 2018
在nat表中增加了一条对宿主机80端口的匹配规则,符合匹配条件的数据包被转向到KUBE-SVC-GYQQTB6TY565JPRW链继续处理,而这个链目前还未创建出来,因为我们没有给这个Service指出后端服务端口。
在filter表中增加了一条针对要访问该Service ip:80服务的数据包的过滤规则,由于“has no endpoints",所以数据包被全部拒绝并回复为网络不可达。
创建Replication Controller并观察结果:
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
labels:
name: frontend
spec:
replicas: 2
selector:
name: frontend
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: php-redis
image: kubeguide/guestbook-php-frontend
ports:
- containerPort: 80
hostPort: 80
env:
- name: GET_HOSTS_FROM
value: env
在集群上发布上述配置文件后,等待并观察,确保所有Pod都运行起来了。
[root@k8s-master ~]# kubectl get rc -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
frontend 2 2 2 13m php-redis kubeguide/guestbook-php-frontend name=frontend
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
frontend-7bstg 1/1 Running 0 14m 172.16.20.2 10.0.2.5
frontend-8g6w8 1/1 Running 0 14m 172.16.10.2 10.0.2.4
Service将会对匹配到标签为"name=frontend"的所有Pod进行负载分发。因为Service的选择匹配所有的这些Pod,所以我们的负载均衡将会对这2个Pod进行分发。
在node1节点上,查看Kube-proxy服务的事件日志,我们可以看到kube-proxy在以每30s同步一次的时间间隔,执行iptables配置规则的同步任务。其中就包括了为"default/frontend:"这个Service设置endpoints,而这又是根据Service定义中指定的标签匹配决定的。
[root@k8s-node1 ~]# ps -ef|grep proxy
root 972 1 0 22:32 ? 00:00:14 /usr/bin/kube-proxy --master=http://10.0.2.15:8080 --hostname-override=10.0.2.4 --logtostderr=true --log-dir=/var/log/kubernetes --v=4
root 1884 976 0 22:45 ? 00:00:00 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 80 -container-ip 172.16.10.2 -container-port 80
root 4161 1728 0 23:31 pts/0 00:00:00 grep --color=auto proxy
[root@k8s-node1 ~]# journalctl _PID=972
Jun 04 23:17:48
k8s-node1.test.com kube-proxy[972]: I0604 23:17:48.810813 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:50
k8s-node1.test.com kube-proxy[972]: I0604 23:17:50.334582 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:50
k8s-node1.test.com kube-proxy[972]: I0604 23:17:50.824018 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.261664 972 reflector.go:286] k8s.io/kubernetes/pkg/client/informers/informers_generated/internalversion/factory.go:
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.261957 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262016 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262059 972 proxier.go:878] Setting endpoints for "default/frontend:" to [172.16.10.2:80 172.16.20.2:80]
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262173 972 proxier.go:878] Setting endpoints for "default/frontend:" to [172.16.10.2:80 172.16.20.2:80]
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262236 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262270 972 proxier.go:878] Setting endpoints for "default/kubernetes:https" to [10.0.2.15:6443]
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262440 972 proxier.go:878] Setting endpoints for "default/kubernetes:https" to [10.0.2.15:6443]
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.262492 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.287716 972 reflector.go:286] k8s.io/kubernetes/pkg/client/informers/informers_generated/internalversion/factory.go:
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.288110 972 config.go:241] Calling handler.OnServiceUpdate
Jun 04 23:17:51
k8s-node1.test.com kube-proxy[972]: I0604 23:17:51.288315 972 config.go:241] Calling handler.OnServiceUpdate
Jun 04 23:17:52
k8s-node1.test.com kube-proxy[972]: I0604 23:17:52.348078 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:52
k8s-node1.test.com kube-proxy[972]: I0604 23:17:52.838431 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:54
k8s-node1.test.com kube-proxy[972]: I0604 23:17:54.362774 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:54
k8s-node1.test.com kube-proxy[972]: I0604 23:17:54.854564 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.391708 972 proxier.go:1005] Syncing iptables rules
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.432430 972 iptables.go:321] running iptables-save [-t filter]
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.436001 972 iptables.go:321] running iptables-save [-t nat]
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.440365 972 iptables.go:381] running iptables-restore [-w 5 --noflush --counters]
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.445522 972 healthcheck.go:235] Not saving endpoints for unknown healthcheck "default/frontend"
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.445551 972 proxier.go:980] syncProxyRules took 53.905661ms
Jun 04 23:17:55
k8s-node1.test.com kube-proxy[972]: I0604 23:17:55.445569 972 bounded_frequency_runner.go:221] sync-runner: ran, next possible in 0s, periodic in 30s
Jun 04 23:17:56
k8s-node1.test.com kube-proxy[972]: I0604 23:17:56.378806 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:56
k8s-node1.test.com kube-proxy[972]: I0604 23:17:56.872912 972 config.go:141] Calling handler.OnEndpointsUpdate
Jun 04 23:17:58
k8s-node1.test.com kube-proxy[972]: I0604 23:17:58.392294 972 config.go:141] Calling handler.OnEndpointsUpdate
此时我们再登录Node1节点,观察下发生变化的iptables规则:
[root@k8s-node1 ~]# iptables-save
# Generated by iptables-save v1.4.21 on Mon Jun 4 23:01:20 2018
*nat
................................
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -j PREROUTING_direct
-A PREROUTING -j PREROUTING_ZONES_SOURCE
-A PREROUTING -j PREROUTING_ZONES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -j OUTPUT_direct
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.16.10.0/24 ! -o docker0 -j MASQUERADE
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -j POSTROUTING_direct
-A POSTROUTING -j POSTROUTING_ZONES_SOURCE
-A POSTROUTING -j POSTROUTING_ZONES
-A POSTROUTING -s 172.16.10.2/32 -d 172.16.10.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.16.10.2:80
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
-A KUBE-SEP-ATXVF35BWTBVBPAT -s 172.16.20.2/32 -m comment --comment "default/frontend:" -j KUBE-MARK-MASQ
-A KUBE-SEP-ATXVF35BWTBVBPAT -p tcp -m comment --comment "default/frontend:" -m tcp -j DNAT --to-destination 172.16.20.2:80
-A KUBE-SEP-K44NXSJ6EIIRFQ5M -s 172.16.10.2/32 -m comment --comment "default/frontend:" -j KUBE-MARK-MASQ
-A KUBE-SEP-K44NXSJ6EIIRFQ5M -p tcp -m comment --comment "default/frontend:" -m tcp -j DNAT --to-destination 172.16.10.2:80
-A KUBE-SEP-OGNOLD2JUSLFPOMZ -s 10.0.2.15/32 -m comment --comment "default/kubernetes:https" -j KUBE-MARK-MASQ
-A KUBE-SEP-OGNOLD2JUSLFPOMZ -p tcp -m comment --comment "default/kubernetes:https" -m recent --set --name KUBE-SEP-OGNOLD2JUSLFPOMZ --mask 255.255.255.255 --rsource -m tcp -j DNAT --to-destination 10.0.2.15:6443
-A KUBE-SERVICES -d 10.10.10.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.10.10.243/32 -p tcp -m comment --comment "default/frontend: cluster IP" -m tcp --dport 80 -j KUBE-SVC-GYQQTB6TY565JPRW
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-GYQQTB6TY565JPRW -m comment --comment "default/frontend:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-K44NXSJ6EIIRFQ5M
-A KUBE-SVC-GYQQTB6TY565JPRW -m comment --comment "default/frontend:" -j KUBE-SEP-ATXVF35BWTBVBPAT
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https" -m recent --rcheck --seconds 10800 --reap --name KUBE-SEP-OGNOLD2JUSLFPOMZ --mask 255.255.255.255 --rsource -j KUBE-SEP-OGNOLD2JUSLFPOMZ
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https" -j KUBE-SEP-OGNOLD2JUSLFPOMZ
..........................................
以上iptables规则中我们只重点关注nat表中因为我们创建这个示例RC所引起变化的这一部分内容。
从中我们可以看到这些知识点:
- 针对Service定义了一个链:KUBE-SERVICES,可以看到其中针对Cluster ip 10.10.10.243:80的访问请求是被跳转到了下面的这个KUBE-SVC-*链中;
- 针对Service的负载均衡功能定义了一个链:KUBE-SVC-GYQQTB6TY565JPRW,因为在我们的示例RC中共定义了两个pods实例,所以这里可以看到先是通过“--mode random --probability 0.50000000000”来按50%的可能性跳转到为Node1节点hostport 80服务所定义的链:KUBE-SEP-K44NXSJ6EIIRFQ5M,另外50%是跳转到为Node2节点hostport 80服务定义的链:KUBE-SEP-ATXVF35BWTBVBPAT;
- 针对Service Endpoints服务定义的链:KUBE-SEP-K44NXSJ6EIIRFQ5M和KUBE-SEP-ATXVF35BWTBVBPAT,有几个Pods实例就会产生几个这样的iptables nat表中的自定义链,每个链中只有两条规则,先是指定了从容器发出的数据包需要做IP地址伪装,然后规定了进入到Node节点的访问请求被DNAT给了指定的容器:端口,如Node1节点的172.16.10.2:80;
以上讨论到的这些iptables规则管理全部是kube-proxy进程负责的。我们是以Node1节点的iptables规则做的讲解,从中可以发现Node1节点的kube-proxy进程不但给本机的pod分发了流量,还直接给Node2节点的另一个pod实例也分发了50%的流量。而且是直接从Node1的kube-proxy将流量负载到了RC的所有Pods上面,并不会额外的经过Node2节点的kube-proxy服务!
下图演示了,从Node1上的Pod访问Service的cluster ip:port时的一种数据流动情况,即流量被Node1节点的kube-proxy服务分配到了Node2上的相应工作Pod上去了,且会绕过Node2的kube-proxy。

6、CNI网络模型
随着用户对容器云的网络特性要求越来越高,跨主机容器网络互通已成为最基本的要求,更高的要求包括容器固定的IP地址、一个容器多个IP地址、多个子网隔离、ACL控制策略、与SDN集成等。目前主流的容器网络模型主要有Docker公司提出的Container Network Model(CNM)模型和CoreOS公司提出的Container Network Interface(CNI)模型。
6.1 CNM模型
CNM模型是Docker公司提出的网络模型,现已被Cisco Contiv, Kuryr, Open Virtual Networking(OVN), Project Calicao, VMware, Weave和Plumgrid等项目采纳。另外Weave, Project Calio, Kuryr和Plumgrid等项目也为CNM提供了网络插件的具体实现。
CNM模型主要通过Network Sandbox, Endpoint 和 Network这3个组件进行实现。如下图所示:
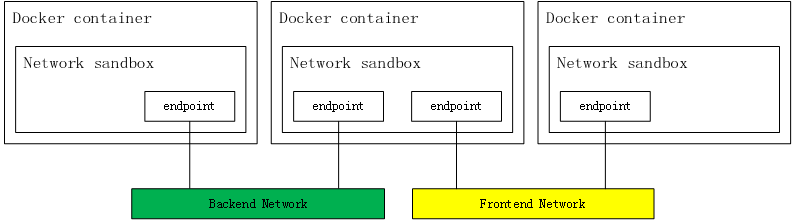
- Network sandbox:容器内部的网络栈,包括网络接口、路由表、DNS等配置的管理。Sandbox可以利用Linux网络命名空间、FreeBSD Jail等机制进行实现。一个Sandbox可以包含多个Endpoint。
- Endpoint:用于将容器内的Sandbox与外部网络相连的网络接口。可以使用veth对、Open vSwitch的内部port等技术进行实现。一个Endpoint仅能够加入一个Network。
- Network:可以直接互连的Endpoint的集合。可以通过Linux网桥、VLAN等技术进行实现。一个Network包含多个Endpoint。
6.2 CNI模型
CNI是由CoreOS公司提出的另一种容器网络规范,2018年初红帽宣布收购CoreOS,其收购的主要目的倒不是为了CNI这一个容器网络规范,因为CNI本身就是开源项目,红帽的主要意图大概是为了CoreOS公司的另一个拳头产品——企业版k8s。
CNI目前已经被Kubernetes, rkt, Apache Mesos, Cloud Foundry和Kurma等项目采纳。Contiv Networking, Project Calico, Weave, SR-IOV, Cilium, Infoblox, Multus, Romana, Plumgrid和Midokura等项目也为CNI提供了网络插件的具体实现。
下图描述了容器运行环境与各种网络插件通过CNI进行连接的模型。

CNI定义的是容器运行环境与网络插件之间的简单接口规范,通过一个JSON Schema定义CNI插件提供的输入和输出参数。一个容器可以通过绑定多个网络插件加入多个网络中。
本节将对K8S如何实现CNI模型进行详细说明。
6.3 CNI规范概述
CNI提供了一种应用容器的插件化网络解决方案,定义对容器网络进行操作和配置的规范,通过插件的形式对CNI接口进行实现。CNI是由rkt Networking Proposal发展而来的,试图提供一种普适的容器网络解决方案。CNI仅关注在创建容器时分配网络资源,和在销毁容器时删除网络资源,这使得CNI规范非常轻巧,易于实现,得到广泛好评。
CNI模型中只涉及两个概念:容器和网络。
- 容器(Container):容器是拥有独立Linux网络命名空间的环境,例如使用Docker或rkt创建的容器。关键之处是容器需要拥有自己的Linux网络命名空间,这是加入网络的必要条件。
- 网络(Network):网络表示可以互连的一组实体,这些实体拥有各自独立、唯一的IP地址。这些实体可以是容器、物理机或者其他网络设备(比如路由器)等。
对容器网络的设置和操作都通过插件进行具体实现,CNI插件包括两种类型:
- CNI Plugin,负责为容器配置网络资源
- IPAM(IP Address Management) Plugin,负责对容器的IP地址进行分配和管理。
IPAM Plugin作为CNI Plugin的一部分,与CNI Plugin一起工作。
6.4 CNI Plugin插件详解
CNI Plugin包括3个基本接口的定义:添加(Add Container to Network)、删除(Delete Container from Network)和版本查询(Report Version)。这些接口的具体实现要求插件提供一个可执行的程序,在容器网络添加或删除时进行调用,以完成具体的操作。
1)添加:将容器添加到某个网络。主要过程为在Container Runtime创建容器时,先创建好容器内的网络命名空间(Network Namespace),然后调用CNI插件为该netns进行网络配置,最后启动容器内的进程。
添加接口的参数如下:
- Version:CNI版本号
- Container ID:容器ID
- Network namespace path:容器的网络命名空间路径,例如/proc/[pid]/ns/net
- Network configuration:网络配置JSON文档,用于描述容器待加入的网络
- Extra arguments:其他参数,提供基于容器的CNI插件简单配置机制
- Name of the interface inside the container:容器内的网卡名
返回的信息如下:
- Interfaces list:网卡列表,根据plugin的实现,可能包括Sandbox Interface名称、主机Interface名称、每个Interface的地址等信息。
- IPs assigned to the interface:IPv4或者IPv6地址、网关地址、路由信息等。
- DNS information:DNS相关的信息。
2)删除:容器销毁时将容器从某个网络中删除。
删除接口的参数如下:
- Version:CNI版本号
- Container ID:容器ID
- Network namespace path:容器的网络命名空间路径,例如/proc/[pid]/ns/net
- Network configuration:网络配置JSON文档,用于描述容器待加入的网络
- Extra arguments:其他参数,提供基于容器的CNI插件简单配置机制
- Name of the interface inside the container:容器内的网卡名
3)版本查询:查询网络插件支持的CNI规范版本号
无参数,返回值为网络插件支持的CNI规范版本号,例如:
{
"cniVersion": "0.3.1", // the version of the CNI spec in use for this output
"supportedVersions": "["0.1.0", "0.2.0", "0.3.0", "0.3.1"]" //the list of CNI spec versions that this plugin supports
}
CNI插件应该能够支持通过环境变量和标准输入传入参数。可执行文件通过”网络配置参数“中的type字段标识的文件名在环境变量"CNI_PATH"设定的路径下进行查找。一旦找到,容器运行时将调用该可执行程序,并传入以下环境变量和网络配置参数,供该插件完成容器网络资源和参数的设置。
环境变量参数如下。
- CNI_COMMAND:接口方法,包括ADD, DEL和VERSION
- CNI_CONTAINERD:容器ID
- CNI_NETNS:容器的网络命名空间路径,例如/proc/[pid]/ns/net
- CNI_IFNAME:待设置的网络接口名称
- CNI_ARGS:其他参数,为key=value格式,多个参数之间用分号分隔,例如"FOO=BAR;ABC=123"
- CNI_PATH:可执行文件查找路径,可以设置多个
网络配置参数则由一个JSON报文组成,以标准输入(stdin)的方式传递给可执行程序。
网络配置参数如下:
- cniVersion (string):CNI版本号
- name (string):网络名称,应在一个管理域内唯一
- type (string):CNI插件可执行文件的名称
- args (dictionary):其他参数
- ipMasq (boolean):是否设置IP Masquerade(需插件支持),适用于主机可作为网关的环境中
- ipam:IP地址管理的相关配置
- type (string):IPAM可执行的文件名
- dns:DNS服务的相关配置
- nameservers (list of strings):名字服务器列表,可以使用IPv4或IPv6地址
- domain (string):本地域名,用于短主机名查询
- search (list of strings):按优先级排序的域名查询列表
- options (list of strings):传递给resolver的选项列表
下列定义了一个名为"dbnet"的网络配置参数,IPAM使用"host-local"进行设置。
{
"cniVersion": "0.3.1",
"name": "dbnet",
"type": "bridge",
"bridge": "cni0",
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameservers": [ "10.1.0.2" ]
}
}
6.5 IPAM Plugin插件详解
为了减轻CNI Plugin对IP地址管理的负担,CNI规范中设置了一个新的插件专门用于管理容器的IP地址(还包括网关、路由等信息),被称为IPAM Plugin。通常由CNI Plugin在运行时自动调用IPAM Plugin完成容器IP地址的分配。
IPAM Plugin负责为容器分配IP地址、网关、路由和DNS,典型的实现包括host-local和dhcp。与CNI Plugin类似,IPAM插件也通过可执行程序完成IP地址分配的具体操作。IPAM可执行程序也处理传递给CNI插件的环境变量和通过标准输入(stdin)传入的网络配置参数。
如果成功完成了容器IP地址的分配,则IPAM插件应该通过标准输出(stdout)返回以下JSON报文:
{
"cniVersion": "0.3.1",
"ips": [
{
"version": "<4-or-6>",
"address": "<ip-and-prefix-in-CIDR>",
"gateway": "<ip-address-of-the-gateway>" (optional)
},
...
],
"routes": [ (optional)
{
"dst": "<ip-and-prefix-in-cidr>",
"gw": "<ip-of-next-hop>" (optional)
},
...
],
"dns":
{
"nameservers": "<list-of-nameservers>", (optional)
"domain": "<name-of-local-domain>", (optional)
"search": "<list-of-search-domains>" (optional)
"options": "<list-of-options>" (optional)
}
}
其中包括ips、routes和dns三段内容。
- ips段:分配给容器的IP地址(也可能包括网关)
- routes段:路由规则记录
- dns段:DNS相关的信息
6.6 多网络插件
很多情况下,一个容器需要连接多个网络,CNI规范支持一个容器运行多个CNI Plugin来实现这个目标。多个网络插件将按照网络配置列表中的顺序执行,并将前一个网络配置的执行结果传递给后面的网络配置。多网络配置用JSON报文进行配置,包括如下信息:
- cniVersion (string):CNI版本号
- name (string):网络名称,应在一个管理域内唯一,将用于下面的所有plugin
- plugins (list):网络配置列表
下例定义了两个网络配置参数,分别作用于两个插件,第1个为bridge,第2个为tuning。CNI将首先执行第1个bridge插件设置容器的网络,然后执行第2个tuning插件:
{
"cniVersion": "0.3.1",
"name": "dbnet",
"plugins": [
{
"type": "bridge",
// type (plugin) specific
"bridge": "cni0",
// args may be ignored by plugins
"args": {
"labels": {
"appVersion": "1.0"
}
},
"ipam": {
"type": "host-local",
// ipam specific
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameserver": [ "10.1.0.1" ]
}
},
{
"type": "tuning",
"sysctl": {
"net.core.somaxconn": "500"
}
}
]
}
容器运行时,在执行第1个bridge插件时,网络配置参数将被设置为:
{
"cniVersion": "0.3.1",
"name": "dbnet",
"type": "bridge",
"bridge": "cni0",
"args": {
"labels": {
"appVersion": "1.0"
}
},
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameservers": [ "10.1.0.2" ]
}
}
之后,在执行第2个tuning插件时,网络配置参数将被设置为:
{
"cniVersion": "0.3.1",
"name": "dbnet",
"type": "tuning",
"sysctl": {
"net.core.somaxconn": "500"
},
"prevResult": {
"ip4": {
"ip": "10.1.0.3/16",
"gateway": "10.1.0.1"
}
"dns": {
"nameservers": [ "10.1.0.2" ]
}
}
}
其中prevResult字段内包含的信息为上一个bridge插件执行的结果。
在删除多个CNI Plugin时,则以逆序执行删除操作,以上例为例,将先删除tuning插件的网络配置:
{
"cniVersion": "0.3.1",
"name": "dbnet",
"type": "tuning",
"sysctl": {
"net.core.somaxconn": "500"
}
}
然后删除bridge插件的网络配置:
{
"cniVersion": "0.3.1",
"name": "dbnet",
"type": "bridge",
"bridge": "cni0",
"args": {
"labels": {
"appVersion": "1.0"
}
},
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameservers": [ "10.1.0.2" ]
}
}
6.7 命令返回信息说明
对ADD或DELETE操作,返回码为0表示执行成功,非0表示失败,并以JSON报文的格式通过标准输出(stdout)返回操作的结果。
以ADD操作为例,成功将容器添加到网络的结果将返回以下JSON报文。其中ips, routes 和 dns段的信息应该与IPAM Plugin返回的结果相同,重要的是interface字段,应通过CNI Plugin进行设置并返回。
{
"cniVersion": "0.3.1",
"interfaces": [ (this key omitted by IPAM plugins)
{
"name": "<name>",
"mac": "<MAC address>", (required if L2 addresses are meaningfull)
"sandbox": "<netns path or hypervisor identifier>" (required for container/hypervisor interfaces, empty/omitted for host interfaces)
}
],
"ips": [
{
"version": "<4-or-6>",
"address": "<ip-and-prefix-in-CIDR>",
"gateway": "<ip-address-of-the-gateway>" (optional)
"interface": <numeric index into 'interfaces' list>
},
...
],
"routes": [ (optional)
{
"dst": "<ip-and-prefix-in-cidr>",
"gw": "<ip-of-next-hop>" (optional)
},
...
],
"dns": {
"nameservers": "<list-of-nameservers>", (optional)
"domain": "<name-of-local-domain>", (optional)
"search": "<list-of-search-domains>" (optional)
"options": "<list-of-options>" (optional)
}
}
接口调用失败时,返回码不为0,应通过标准输出(stdout)返回如下包含错误信息的JSON报文:
{
"cniVersion": "0.3.1",
"code": <numeric-error-code>,
"msg": <short-error-message>,
"details": <long-error-message> (optional)
}
错误码包括如下内容:
- CNI版本不匹配
- 网络配置中存在不支持的字段,详细信息应在msg中说明
6.8 在Kubernetes中使用网络插件
Kubernetes目前支持两种网络插件的实现。
- CNI插件:根据CNI规范实现其接口,以与插件提供者进行对接
- kubenet插件:使用bridge和host-local CNI插件实现了一个基本的cbr0,目前还处于Alpha阶段
为了在Kubernetes集群中使用网络插件,需要在kubelet服务的启动参数上设置下面两个参数:
- --network-plugin-dir:kubelet启动时扫描网络插件的目录
- --network-plugin:网络插件名称,对于CNI插件,设置为"cni"即可,无须关注--network-plugin-dir的路径。对于kubenet插件,设置为"kubenet", 目前仅实现了一个简单的cbr0 Linux网桥。
在设置--network-plugin="cni"时,kubelet还需设置下面两个参数:
- --cni-conf-dir:CNI插件的配置文件目录,默认为/etc/cni/net.d。该目录下的配置文件内容需要符合CNI规范
- --cni-bin-dir:CNI插件的可执行文件目录,默认为/opt/cni/bin
目前已有多个开源项目支持以CNI网络插件的形式部署到Kubernetes集群中,进行Pod的网络设置和网络策略的设置,包括Calico, Canal, Cilium, Contiv, Flannel, Romana, Weave Net等。
7、Kubernetes网络策略
为了实现细粒度的容器间网络访问隔离策略,k8s 从v1.3版本开始,由SIG-Network小组主导研发了Network Policy机制,目前API版本为extensions/v1beta1。Network Policy的主要功能是对Pod间的网络通信进行限制和准入控制,设置方式为将Pod的Label作为查询条件,设置允许访问或禁止访问的客户端Pod列表。目前查询条件可以作用于Pod和Namespace级别。
为了使用Network Policy,k8s引入一个新的资源对象"NetworkPolicy",供用户设置Pod间网络访问的策略。但仅定义一个网络策略是无法完成实际的网络隔离的,还需要一个策略控制器(policy controller)进行策略的实现。策略控制器由第三方网络组件提供,目前Calico, Romana, Weave, OpenShift, OpenContrail等开源项目均支持网络策略的实现。
Network Policy的工作原理如下图所示,policy controller需要实现一个API Listener,监听用户设置的NetworkPolicy定义,并将网络访问规则通过各Node的Agent进行实际设置(Agent则需要CNI网络插件实现)。

网络策略的设置包括网络隔离(禁止访问)和允许访问(白名单)两种方式,网络隔离需要在设置其他允许访问列表之前进行启用。
7.1 网络隔离
网络隔离作用于Namespace级别。为一个Namespace设置了网络隔离后,该规则将作用于属于这个Namespace的所有Pod,即拒绝所有Pod之间的网络访问。当前仅支持“进入”方向的网络访问(Ingress)。
目前支持的网络隔离策略仅有DefaultDeny,即到该Namespace中Pod的网络访问都被拒绝。
下面例子是设置DefaultDeny网络策略方式为给Namespace default设置一个annotation:
kind: Namespace
apiVersion: v1
metadata:
name: default
annotations:
net.beta.kubernetes.io/network-policy:
{
"ingress": {
"isolation": "DefaultDeny"
}
}
也可以使用kubectl命令行工具给一个Namespace设置annotation:
# kubectl annotate ns <namespace_name>
"net.beta.kubernetes.io/network-policy={\"ingress\": {\"isolation\": \"DefaultDeay\"}}"
7.2 准入白名单设置
在设置了默认的网络隔离策略之后,系统管理员还需对允许访问Pod的策略进行进一步设置,这就要通过NetworkPolicy对象来完成了,以下面的定义为例:
apiVersion: extensions/v1beta1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
ingress:
- from:
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: tcp
port: 6379
主要参数如下:
- podSelector:用于定义后面Ingress策略将作用的Pod范围,即网络访问的目标Pod范围。
- ingress: 定义可以访问目标Pod的白名单策略,满足from条件的客户端才能访问ports定义的目标Pod端口号。
- from:对符合条件的客户端Pod进行网络放行,可以基于客户端Pod的Label或客户端Pod所在的Namespace的Label进行设置。
- ports:可访问的目标Pod监听的端口号。
通过这个NetworkPolicy定义,管理员实际上设置了如下网络策略。
- 该策略作用于Namespace default中含有"role=db" Label的全部Pod(作为服务提供者)。
- 包含"role=frontend" Label的客户端Pod允许访问。
- 属于包含"project=myproject" Label的Namespace的客户端Pod允许访问。
下列的NetworkPolicy设置允许任何客户端访问:
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: allow-all
spec:
podSelector:
ingress:
- {}
参考资料:
《Kubernetes权威指南——从Docker到Kubernetes实践全接触》第3章