这里我们以最简单、最对小白友善的八爪鱼采集器为例说明
1、下载官网
2、采集对象
比如我要采集安居客上上海杨浦区二手房的房源信息,首先打开我要采集的网页
https://shanghai.anjuke.com/sale/yangpu/
我们要采集的界面如下:

就是要把每一条数据的房价、户型、面积等信息爬取下来。
3、开始采集
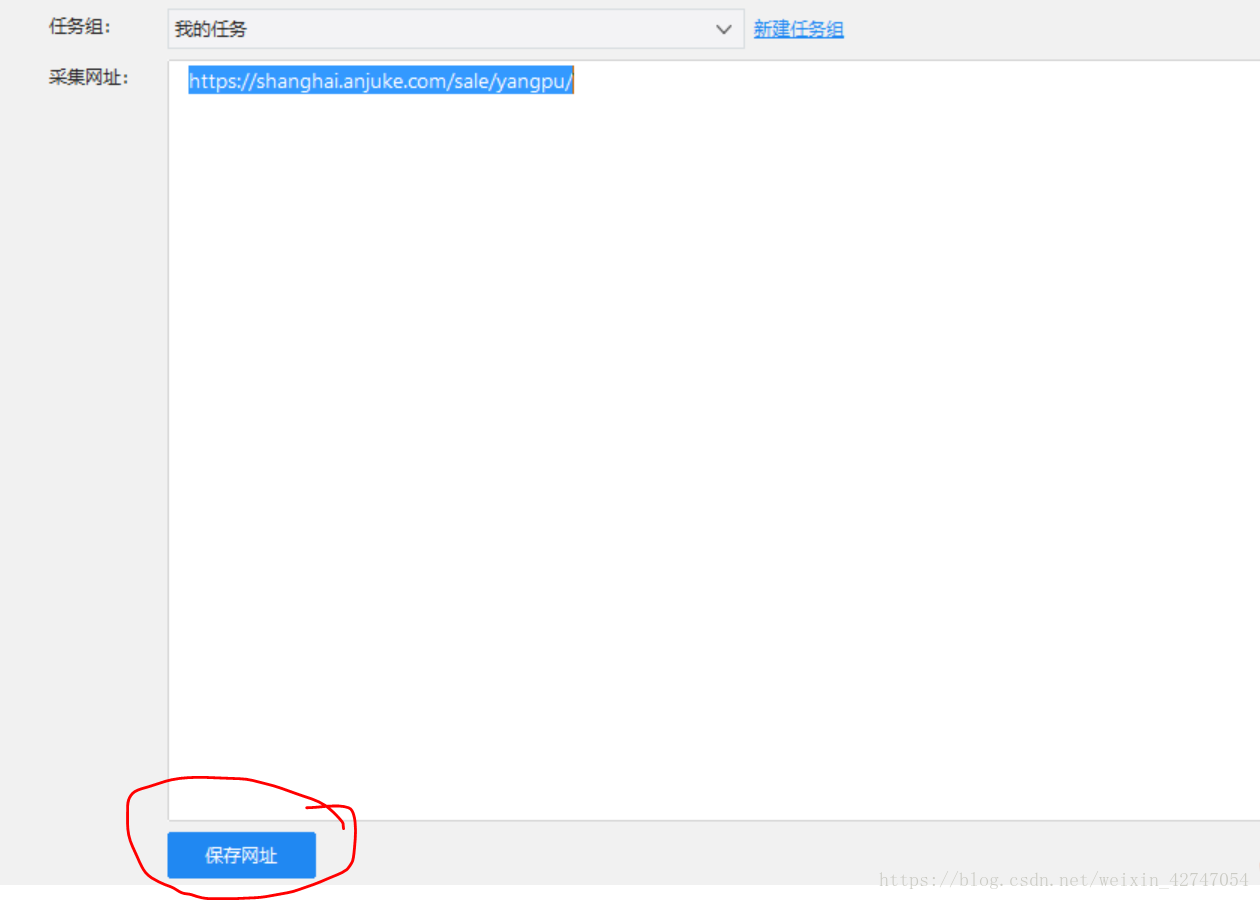
第一步,点击“自定义采集”下的“立即使用”,把我们的网址复制到“采集网址”里,并点击保存网址
鼠标往下滚,滚到我们想看到的界面
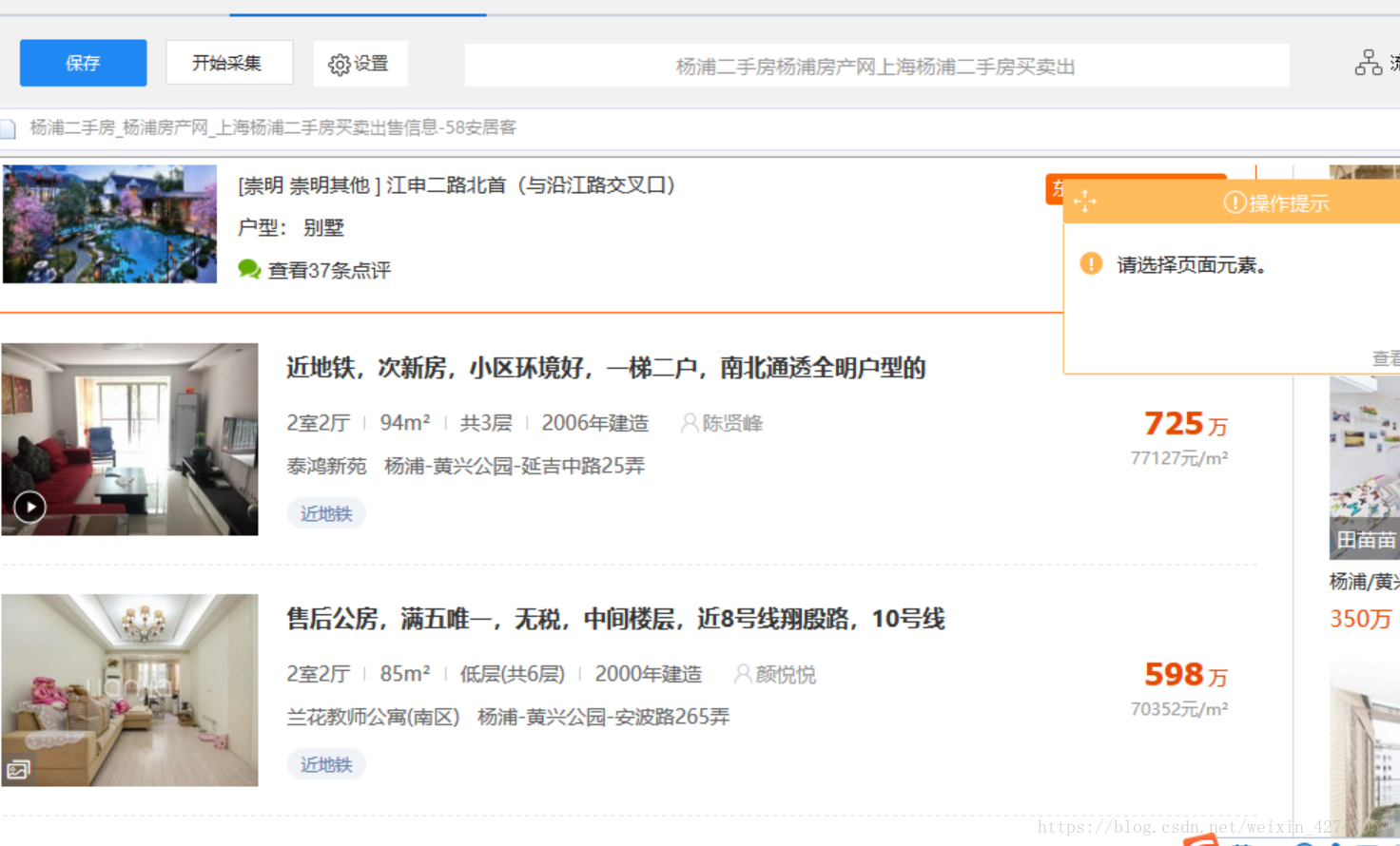
点击第一条的标题后,呈绿色,同时八爪鱼与自动识别相似字段并用浅红色表示,这时,点击右边选项框的“选中全部”

这时,标题都变成绿色了代表全部被选中,当然我们要采集不只是标题,还有点开它以后里面各条的内容,因此我们再点击“循环点击每个链接”

之后就跳到了第一条的内容里
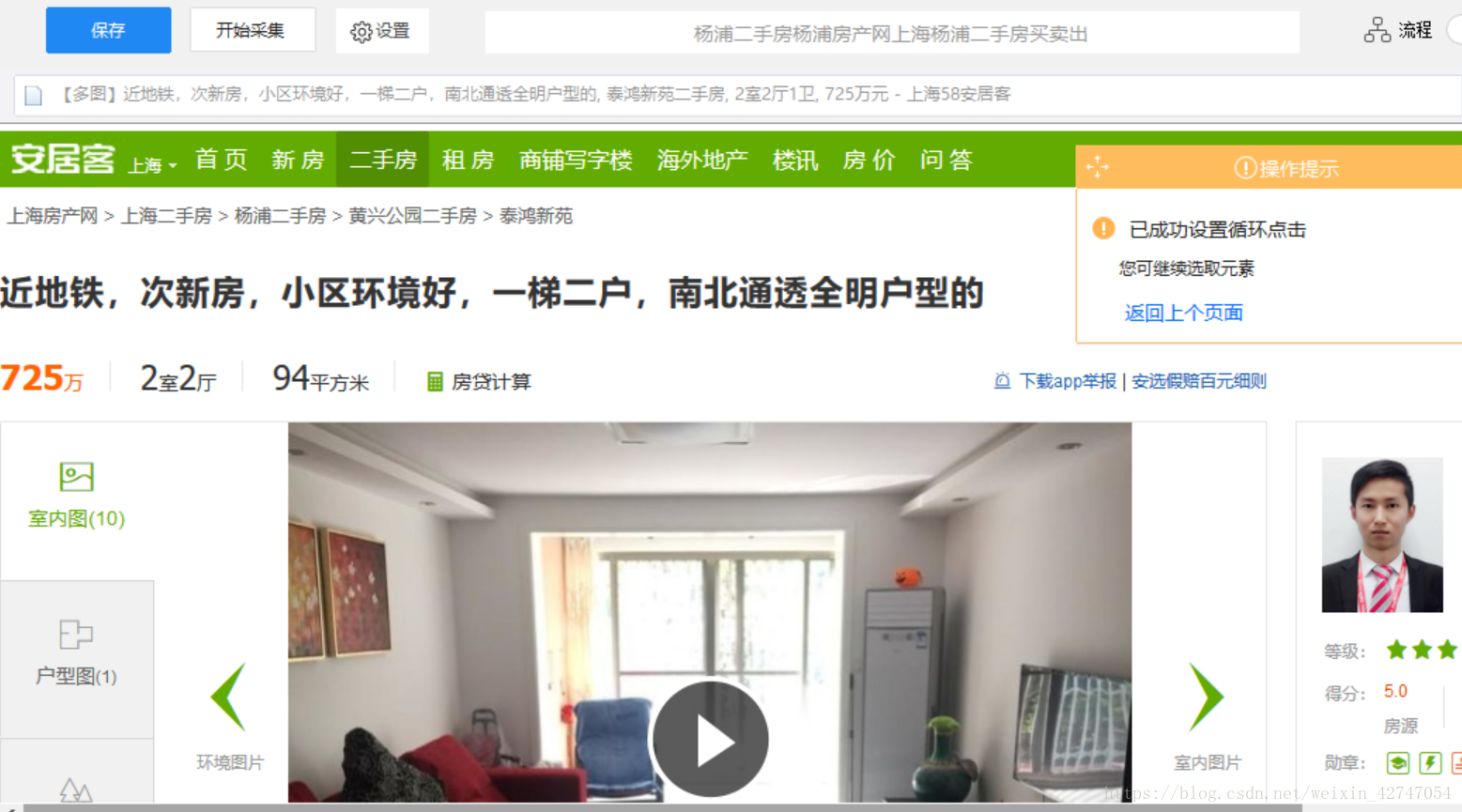
往下滚动鼠标,发现我们要的信息都在这一区域

依次点击我们想要的数据

点击“采集以下数据”后,打开上面的“数据预览”
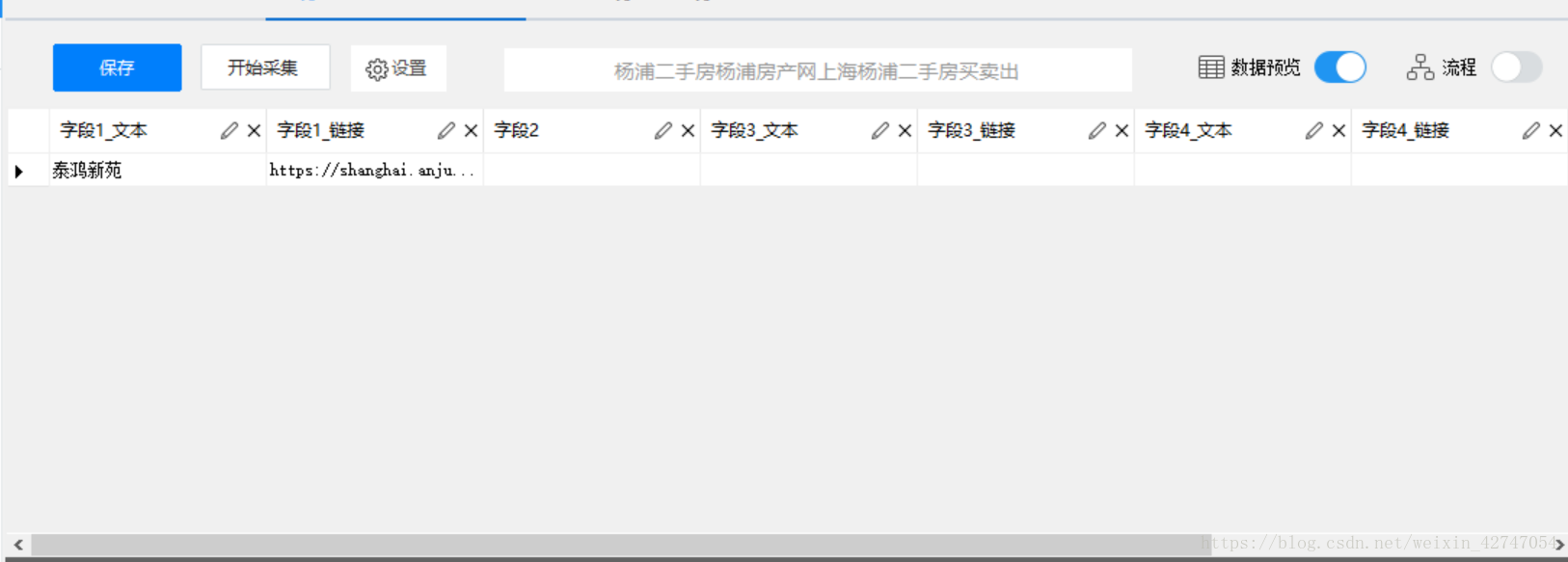
发现我们采集了很多列数据,这时建议更改列名以防后续把数据导下来时忘记对应的信息是什么。
这里只是设置了一页的规则,接下来我们要设置完翻页
把“流程”打开,点击“打开网页”就可以回到一开始的界面

这时关掉“流程”,来到我们要翻页的地方。

点击“下一页”,会弹出操作提示的选项框,我们点击“循环点击下一页”(这里安居客的网页翻页的是“下一页”,如果是“加载更多”这类其他语句,八爪鱼就识别不出来,选项框也就不会出现“循环点击下一页”的提示,这时我们就要点击“循环点击该链接”等字样的选项)

打开流程,发现原来的循环下面多了一个循环,这个新的循环就是我们刚才设置的翻页循环
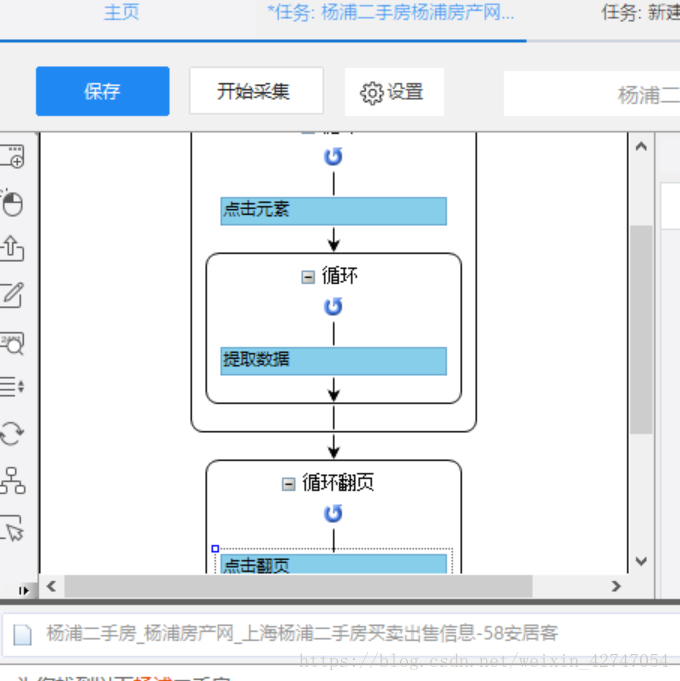
我们的逻辑规则是:
先翻页,再点击每一条,最后把每一条中的数据提取出来
那么翻页这个循环就要放在最外面,把上面的循环包含起来,我们用鼠标选中上面那个循环
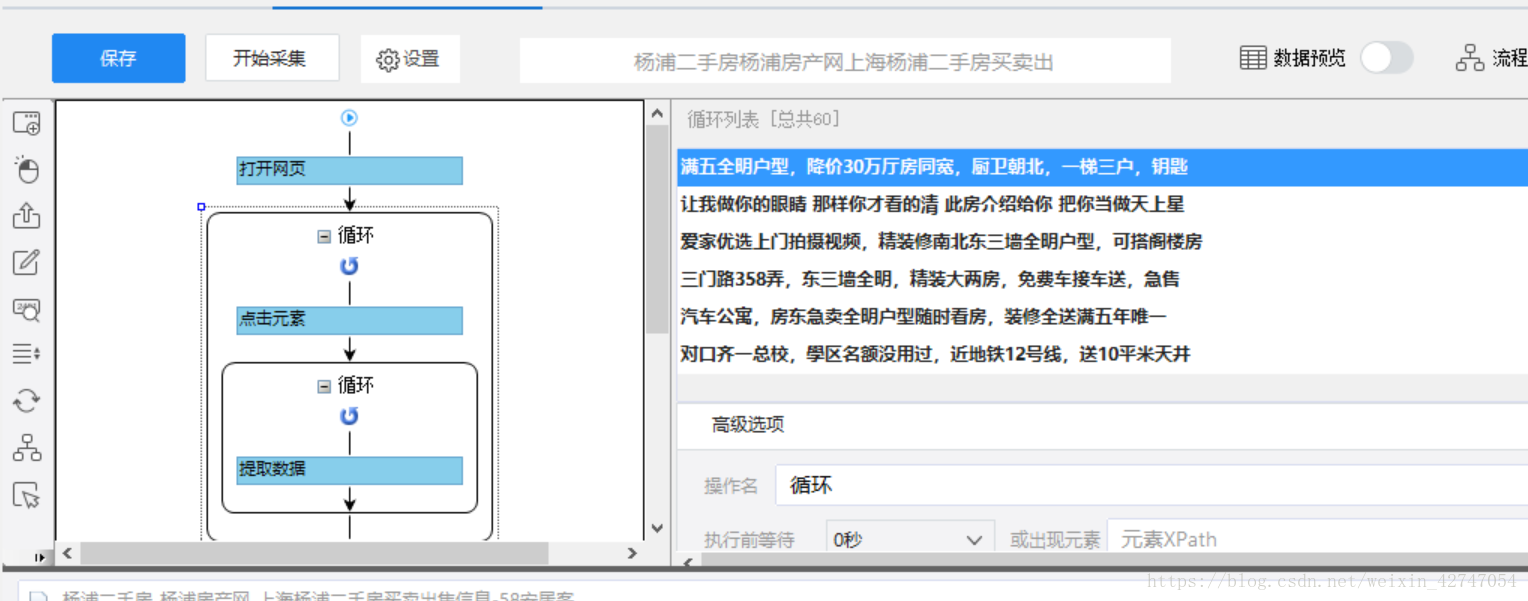
把它拖动到翻页循环里面

最后整个流程就做完了,接下来就是保存,并点击“开始采集”。