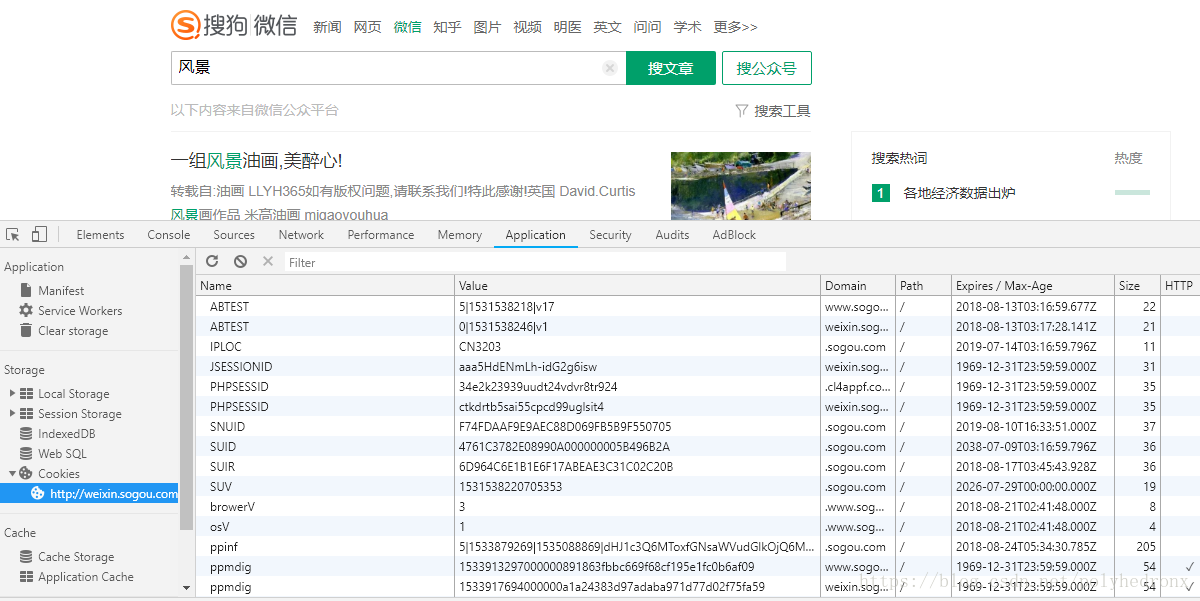
搜狗(http://weixin.sogou.com/)已经为我们做了一层微信文章的爬取,通过它我们可以获取一些微信文章的列表以及微信公众号的一些信息,但是它有很多反爬虫的措施,可以检测到你的IP异常,然后把你封掉。本文采用代理的方法处理反爬来抓取微信文章。
(1)目标站点分析
打开搜狗微信,输入要查找的内容,比如我们输入“风景”,就会出现微信文章的列表,向下翻动我们可以发现每页有10条内容,在最下方可以进行翻页。需要注意的是,未登陆时最多可以查看10页内容,登陆之后就可以查看100页的内容(也就是说,做爬虫的时候可以使用cookie爬取到100页内容):
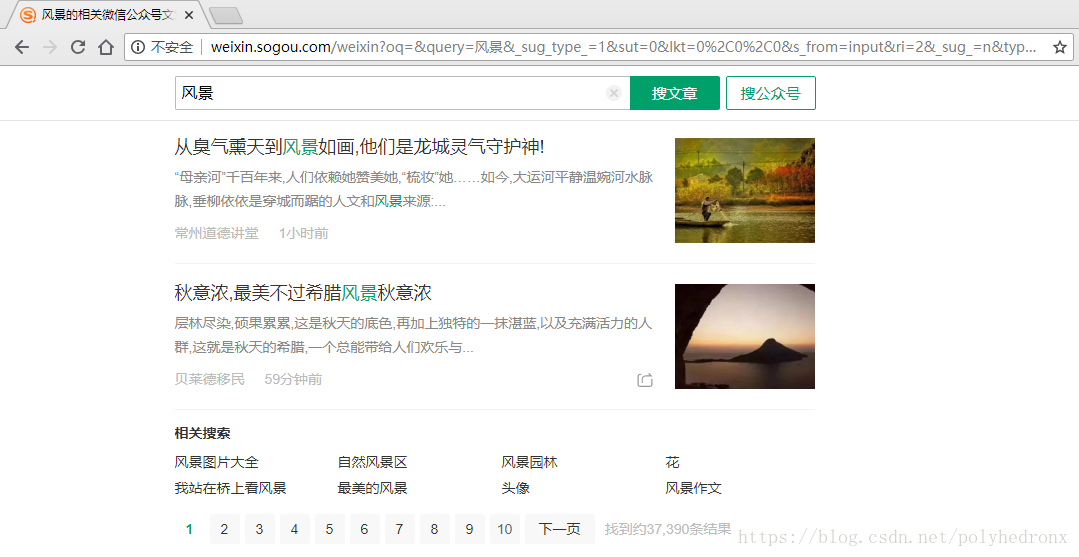
从网页的url可以看出这是一个get请求,只保留主要的请求参数,把url简化为:
其中,“query”代表搜索的关键词,“type”代表搜索结果的类型,“type=1”表示搜索结果是微信公众号,“type=2”表示搜索结果是微信文章,“page”也就是当前页数。
现在网页是能正常访问的,但当我们点击翻页比较频繁的话,就会出现访问出错,输入验证码之后才能再次正常访问:
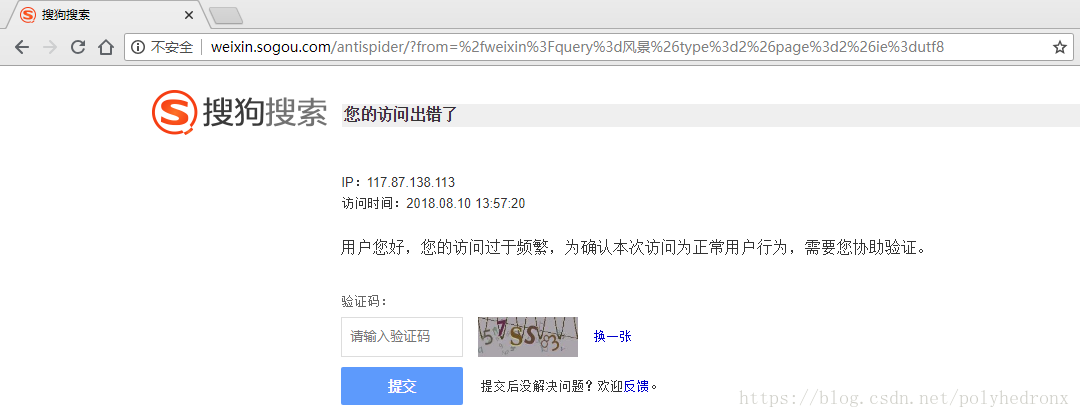
对网页请求进行分析,可以发现正常请求时状态码都是200,出现访问出错时状态码变成了302:

状态码302又代表什么呢?百度一下:
HTTP状态码302表示临时性重定向,该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。
也就是说,我们原来的请求被跳转到了一个新的页面,这个新的页面就是访问出错,需要输入验证码的页面:
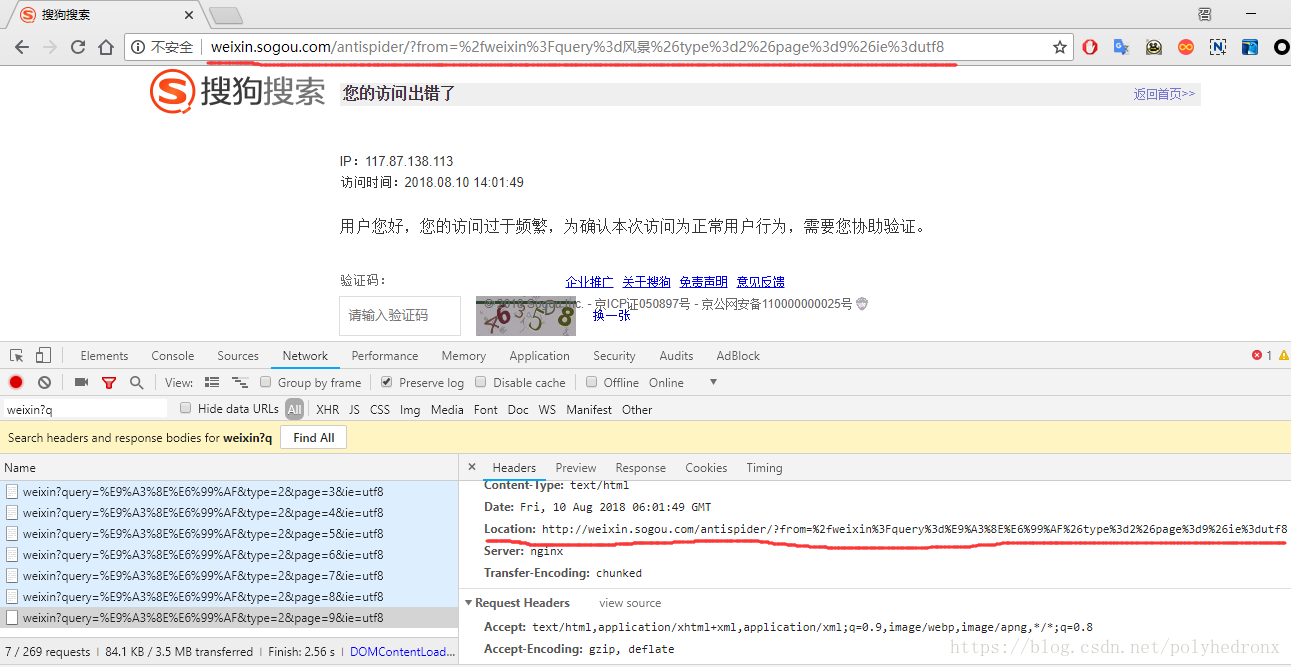
根据以上分析,我们可以根据请求返回的状态码判断IP是否被封,如果状态码是200说明可以正常访问,如果状态码是302,则说明IP已经被封。
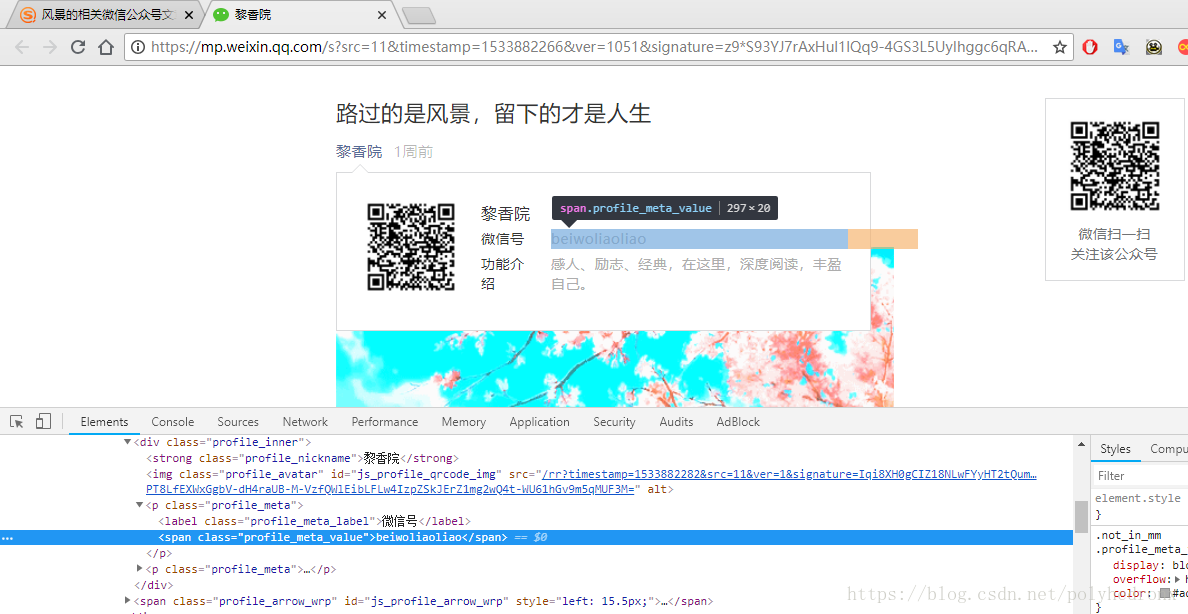
接着我们再分析一下后续的页面。在列表里打开一条微信文章,我们可以获取到文章的标题、公众号的一些信息,以及文章内容。文章内容包括文字和一些图片,在这里我们只爬取文章中的文字部分。
(2)流程框架
1.抓取索引页内容
利用requests请求目标站点,得到索引网页HTML代码,返回结果。
2.代理设置
如果遇到302状态码,则说明IP被封,切换代理重试。
3.分析详情页内容
请求详情页,分析得到标题、正文等内容。
4.将数据保存到数据库
将结构化数据保存至MongoDB。
(3)爬虫代码
# weixin_article.py
import re
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
from requests.exceptions import ConnectionError
from weixin_article_config import *
import pymongo
from fake_useragent import UserAgent, FakeUserAgentError
import time
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
proxy = None # 全局代理
def get_proxy():
try:
response = requests.get('http://127.0.0.1:5000/get')
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy # 引用全局变量
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
ua = UserAgent()
except FakeUserAgentError:
pass
headers = {
'Cookie': 'IPLOC=CN3203; SUID=4761C3782E08990A000000005B496B2A; SUV=1531538220705353; ABTEST=0|1531538246|v1; weixinIndexVisited=1; JSESSIONID=aaa5HdENmLh-idG2g6isw; PHPSESSID=ctkdrtb5sai55cpcd99uglsit4; SUIR=6D964C6E1B1E6F17ABEAE3C31C02C20B; ppinf=5|1533879269|1535088869|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo1OnN1Z2FyfGNydDoxMDoxNTMzODc5MjY5fHJlZm5pY2s6NTpzdWdhcnx1c2VyaWQ6NDQ6bzl0Mmx1QXg2cUNnY3dESUlCVkQ4REQzejdmVUB3ZWl4aW4uc29odS5jb218; pprdig=qmTYp6UdjuqBQsh41S2iPuC6aVGbF8-gC-oD4_JnXCEABwuE8dKqwUYrBA6ShYaZPxoNW11zcC9vnHQXr57mKAkCYl_j7HUAwAwPPkB8Hw8Iv1IBDQKe3oFFlmig9sp8N_H9VHyF9G-o03WmzDLDoZyiZ-3MPvM-olyDPQ4j_gY; sgid=31-36487535-AVttIibUibd0Gctt8SOaDTEqo; sct=4; wP_h=effa146bd88671d4ec8690f70eefe1957e085595; ppmdig=1533917694000000a1a24383d97adaba971d77d02f75fa59; SNUID=9028BCC8F9FC8BEEF42ED05AF94BDD9E; seccodeRight=success; successCount=1|Fri, 10 Aug 2018 16:20:22 GMT',
'Host': 'weixin.sogou.com',
'Referer': 'http://weixin.sogou.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': ua.random
}
try:
if proxy:
proxies = {'http': proxy}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies) # timeout=10
else:
response = requests.get(url, allow_redirects=False, headers=headers) # timeout=10
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
else:
print('Error Status Code', response.status_code)
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
def get_index(keyword, page):
data = {
'query': keyword,
'type': '2',
'page': page
}
url = 'http://weixin.sogou.com/weixin?' + urlencode(data)
return get_html(url)
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
def parse_detail(html, url):
doc = pq(html)
title = doc('.rich_media_title').text()
content = "".join(doc('.rich_media_content').text().split())
nickname = doc('.profile_nickname').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
date_pattern = re.compile('var publish_time = \"(.*?)\"', re.S)
date_search = re.search(date_pattern, html)
if date_search:
date = date_search.group(1)
else:
date = None
return {
'url': url,
'title': title,
'date': date,
'nickname': nickname,
'wechat': wechat,
'content': content
}
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Save to Mongo', data['title'])
return True
else:
print('Save to Mongo Failed', data['title'])
return False
def main():
for page in range(1, 101):
html = get_index(KEYWOED, page)
time.sleep(1) # 减小IP被封的风险
if html:
article_urls = parse_index(html)
for article_url in article_urls:
if article_url:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html, article_url)
if article_data:
save_to_mongo(article_data)
if __name__ == '__main__':
main()
# config.py
MONGO_URL = 'localhost'
MONGO_DB = 'weixin'
MONGO_TABLE = 'articles'
KEYWOED = '风景' # 关键词
MAX_COUNT = 5 # 最大请求次数
此外,需要注意的是,程序使用的代理是从自己维护的代理池中取用的,而代理池是从网上获取的一些公共IP,这些IP一般是不太稳定的,也有可能是很多人都在使用的,所以爬取效果可能不是很好,被禁的概率比较高。当然,你也可以使用自己购买的一些代理,只需要改写“get_proxy”方法就ok了。
最后,还需要注意Cookies的一些设置。从下面的图中我们可以看出,cookies是有它自己的过期时间的,如果在抓取过程中发现无法获取后面的内容,有可能是cookies已经过期了,这时候我们重新登录一下,然后替换掉原来的Cookies就好了。