微信于2018年12月21号发布了7.0.0的版本,微信手机端界面及相关链接结构改变巨大,之前的fiddle抓包爬取微信文章评论可能不适用,在此,可以直接使用网页进行微信文章+评论的爬取,不需要抓包。本文以爬取CSDN的公众号文章+评论为例。
将任意一篇CSDN的文章用浏览器打开。
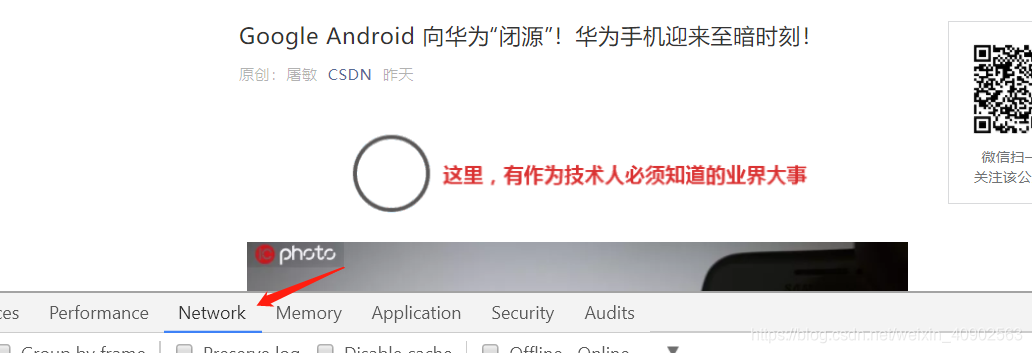
刷新网页,在Network中找到appmsgreport?action(通常是在最下面)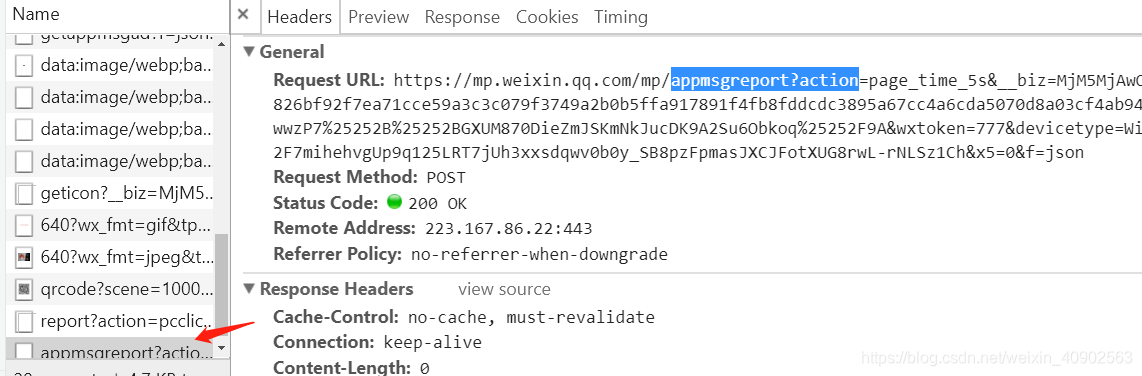
在之前的fiddle抓包获取评论时,我们可以看到文章的评论和点赞是位于这个文件中,可能该链接无法打开,因为其中的pass_ticket、appmsg_token参数是会随机更改
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5MjAwODM4MA==&f=json&offset=120&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=Kg1y6upVtIfQczL3z0iwwwzP7%2B%2BGXUM870DieZmJSKmNkJucDK9A2Su6Obkoq%2F9A&wxtoken=&appmsg_token=1009_fhrxCPVFBbA%2F7mihehvgUp9q125LRT7jUh3xxsdqwv0b0y_SB8pzFpmasJXCJFotXUG8rwL-rNLSz1Ch&x5=1&f=json
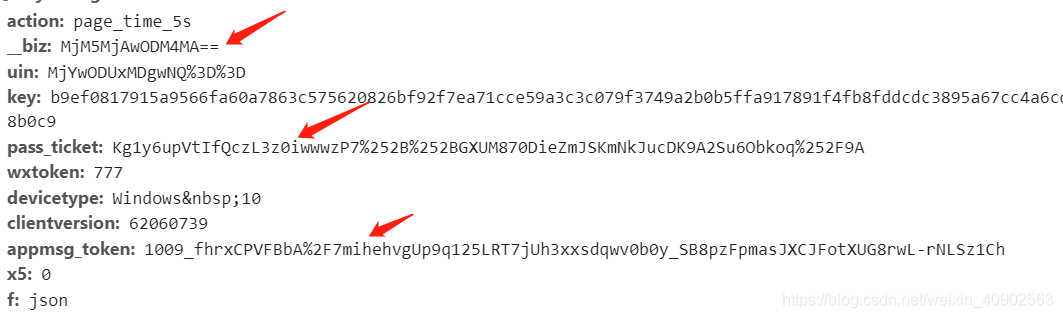
在刚刚的appmsgreport?action中找到这三个参数,其中_biz是每个公众号独一的id,pass_ticket和appmsg_token会随机更改,所以基本上每爬一个公众号就需要重新复制一次。
同时还有第四个参数:cookie
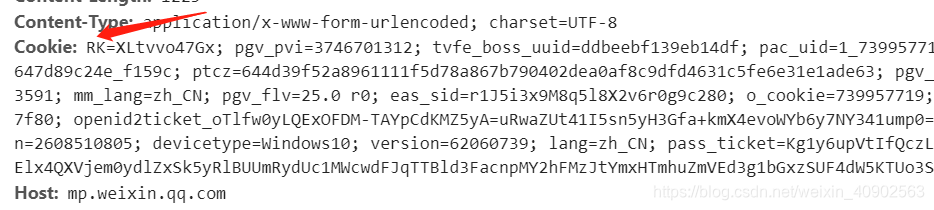
在这里,需要将cookie的所有内容复制,现在已经准备好所有的参数,代码如下:
import json
import re
from datetime import datetime
import time
import os
from lxml import etree
from selenium import webdriver
from pyquery import PyQuery as pq
i =0
import requests
class WxMps(object):
"""微信公众号文章、评论抓取爬虫"""
def __init__(self, _biz, _pass_ticket, _app_msg_token, _cookie, _account,start_time, _offset=120):
self.offset = _offset
self.biz = _biz # 公众号标志
self.msg_token = _app_msg_token # 票据(非固定)
self.pass_ticket = _pass_ticket # 票据(非固定)
self.account = _account
self.startime = start_time
self.headers = {
'Cookie': _cookie, # Cookie(非固定)
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0; Mi Note 2 Build/OPR1.170623.032; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/044306 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070336) NetType/WIFI Language/zh_CN Process/toolsmp'
}
def start(self):
"""请求获取公众号的文章接口"""
# print(type(self))
offset = self.offset
while True:
api = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz={0}&f=json&offset={1}' \
'&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket={2}&wxtoken=&appmsg_token' \
'={3}&x5=1&f=json'.format(self.biz, offset, self.pass_ticket, self.msg_token)
print(api)
resp = requests.get(api, headers=self.headers).json()
print(resp)
ret, status = resp.get('ret'), resp.get('errmsg') # 状态信息
if ret == 0 or status == 'ok':
print('Crawl article: ' + api)
time.sleep(2)
offset = resp['next_offset'] # 下一次请求偏移量
general_msg_list = resp['general_msg_list']
msg_list = json.loads(general_msg_list)['list']
# 获取文章列表
for msg in msg_list:
app_msg_ext_info = msg.get('app_msg_ext_info') # article原数据
if app_msg_ext_info:
# 本次推送的首条文章
multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')
only_url_1 = app_msg_ext_info.get('content_url')
self._parse_article_detail(only_url_1, app_msg_ext_info)
# 本次推送的其余文章
if multi_app_msg_item_list:
for item in multi_app_msg_item_list:
only_url_2 = item.get('content_url')
self._parse_article_detail(only_url_2, item)
print('next offset is %d' % offset)
else:
print('Before break , Current offset is %d' % offset)
break_time = datetime.now()
print(break_time-self.startime)
break
def _parse_article_detail(self, content_url, main_article):
"""从文章页提取相关参数用于获取评论,article_id是已保存的文章id"""
content_url = content_url.replace('amp;', '').replace('#wechat_redirect', '').replace('http', 'https')
try:
html = requests.get(content_url, headers=self.headers).text
except:
print('获取评论失败' + content_url)
else:
# group(0) is current line
str_comment = re.search(r'var comment_id = "(.*)" \|\| "(.*)" \* 1;', html)
str_msg = re.search(r"var appmsgid = '' \|\| '(.*)'\|\|", html)
str_token = re.search(r'window.appmsg_token = "(.*)";', html)
if str_comment and str_msg and str_token:
comment_id = str_comment.group(1) # 评论id(固定)
app_msg_id = str_msg.group(1) # 票据id(非固定)
appmsg_token = str_token.group(1) # 票据token(非固定)
# 缺一不可
if appmsg_token and app_msg_id and comment_id:
print('Crawl article comments: ' + content_url)
self._crawl_comments(app_msg_id, comment_id, appmsg_token, main_article)
def _crawl_comments(self, app_msg_id, comment_id, appmsg_token, main_article):
"""抓取文章的评论"""
comment_list = []
api = 'https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0&__biz={0}' \
'&appmsgid={1}&idx=1&comment_id={2}&offset=0&limit=100&uin=777&key=777' \
'&pass_ticket={3}&wxtoken=777&devicetype=android-26&clientversion=26060739' \
'&appmsg_token={4}&x5=1&f=json'.format(self.biz, app_msg_id, comment_id,
self.pass_ticket, appmsg_token)
try:
resp = requests.get(api, headers=self.headers).json()
ret, status = resp['base_resp']['ret'], resp['base_resp']['errmsg']
if ret == 0 or status == 'ok':
time.sleep(2)
elected_comment = resp['elected_comment']
for comment in elected_comment:
content = comment.get('content') # 评论内容
like_num = comment.get('like_num') # 点赞数
comment_dict = {}
comment_dict["comment_content"] = content
comment_dict["like_num"] = like_num
comment_list.append(comment_dict)
self.write_in(main_article, self.account, comment_list)
except Exception as e:
print(e,'error3')
def write_in(self, main_url, account, comment_list):
print("------json")
data1 = {}
# print(type(main_url))
data1['title'] = main_url.get('title')
data1['url'] = main_url.get('content_url')
data1['account'] = account
# print(data1)
content_url = main_url.get('content_url')
content = self.get_content_requests(content_url)
# print("处理内容")
data2 = {}
data2['title']= main_url.get('title')
data2['digest']= main_url.get('digest')
data2['content']= content
data2['comments']= comment_list
# print(data2)
global i
i += 1
print(i)
#备份
with open(r'{}.json'.format(account), 'a+', encoding='utf-8' ) as f:
json.dump(data1, f, ensure_ascii=False, indent=4)
f.write(',')
f.write('\n')
#文章
with open(r'{}-articles.json'.format(account), 'a+', encoding='utf-8') as f:
json.dump(data2, f, ensure_ascii=False, indent=4)
f.write(',')
f.write('\n')
def get_content_requests(self,content_url):
response = requests.get(content_url).text
html = etree.HTML(response)
content = html.xpath('//*[@id="js_content"]//p')
content_string = ""
for temp in content:
if temp != None and temp != '\n':
# file.writelines(temp.xpath('string(.)') + '\n')
content_string = content_string + temp.xpath('string(.)') + '.'
return content_string
if __name__ == '__main__':
biz = 'MjM5MjAwODM4MA==' # 公众号的专有id
pass_ticket = '' #pass_ticket
app_msg_token = '' # appmag_token
cookie = '' # cookie
# global file_path##需修改
account = 'CSDN' # 公众号名字,用于保存的文件命名
# 以上信息不同公众号每次抓取都需要借助抓包工具做修改
start_time = datetime.now()
wxMps = WxMps(biz, pass_ticket, app_msg_token, cookie, account,start_time )
wxMps.start() # 开始爬取文章及评论
这种方式是由于微信大更新,fiddle抓包不适用而采用,相比fiddle抓包的优点:简单容易,直接浏览器打开你想要爬取的公众号的随意一篇文章即可获取所有文章的评论和内容;其次,不需要担心会被封号,之前的fiddle抓包是抓手机浏览文章时反馈的数据报,会带有微信账号信息,一旦被微信检测到恶意刷文章,就会被封号处理。请大家尽快保存使用,如果微信再一次大更新,小编会尽力更新方法和代码。如果转载,请附上我的链接,谢谢。最后 附上代码的成果图

