一、利用Dom4j进行生成和解析XML文件,简要过程如下:
//////////使用Dom4j创建XML文档
//【1】定义一个XML文档对象
Document document=DocumentHelper.createDocument();//【2】定义一个XML元素,添加根结点
Element root=document.addElement("根结点名称");
///Element接口重要常用方法
///addComment 添加注释
///addAttribue 添加属性
///addElement 添加子元素
//【3】通过XMLWriter生成物理文件
XMLWriter writer=new XMLWriter(fos,format);
writer.write(document);
///参数fos是指输出流;参数format为格式化文件
//OutputFormat类格式化输出-默认采用createC-
//ompactFromat比较紧凑-最好使用createPrettyPrint
事例程序如下:
public class dom4j {
/**
* @param args参数传递
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
dom4j dom=new dom4j();
System.out.println("index:"+dom.createXMLFile("E:/student.xml"));
}
public int createXMLFile(String fileName){
int index=0;
Document document=DocumentHelper.createDocument();///创建根结点
Element root=document.addElement("students");///添加根结点
root.addComment("学生集合");//添加注释
Element first=root.addElement("student");//根结点添加子结点
first.addAttribute("id", "1410101");
Element thirt=first.addElement("name");
thirt.addText("王菲");
Element four=first.addElement("age");
four.addText("18");
Element five=first.addElement("sex");
five.addText("女");
Element second=root.addElement("student");
second.addAttribute("id", "1410102");
Element name=second.addElement("name");
name.addText("张三");
Element age=second.addElement("age");
age.addText("19");
Element sex=second.addElement("sex");
sex.addText("男");
OutputFormat format=OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
try {
FileOutputStream fos=new FileOutputStream(fileName);
XMLWriter writer=new XMLWriter(fos,format);
writer.write(document);
writer.close();
index=1;
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("文件流失败...");
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("编码格式出错...");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("文件写入失败...");
}
return index;
}
}运行程序将在E盘下生成XML文件,内容如下:
<students>
<!--学生集合-->
<student id="1410101">
<name>王菲</name>
<age>18</age>
<sex>女</sex>
</student>
<student id="1410102">
<name>张三</name>
<age>19</age>
<sex>男</sex>
</student>
</students>
//////使用Dom4j解析XML文件
///【1】构建XML文档对象
SAXReader reader=new SAXReader();////创建SAXReader对象--用来读取文档
Document document=reader.read(new File("E:/student.xml"));///读取XML文档对象
//【2】获取根结点
Element root=document.getRootElement();
///【3】获取子结点
//【--1--】通过element()方法获取指定名称的第一个节点
Element student=root.element("student");
for(Iterator iterator=student.elementIterator();iterator.hasNext();){
Element element=(Element)iterator.next();
System.out.println(element.getStringValue());
}
//【--2--】通过elements()方法获取指定名称的全部节点
Element student=root.elements("student");
for(Iterator iterator=student.elementIterator();iterator.hasNext();){
Element element=(Element)iterator.next();
System.out.println(element.getStringValue());
}///【4】获取属性的方法

Element student=root.element("student");
Attribute attribute=student.attribute("id");///按照顺序获取属性
//student.attribute(0);
List list=student.attribute("id");///获取全部属性
///【5】修改XML文档
Element root=document.getRootElement();///获取根结点
Element student=root.element("studnet");///获取要修改的父结点
Element name=student.element("name");///获取修改节点
name.setText("--");///修改节点内容
name.setName("--");///个性节点名
Attribute id=student.attribute("id");
id.setText("3");////【6】删除节点或者属性
Element root=document.getRootElement();///获取根结点
Element student=root.element("studnet");///获取要删除的父结点
Element name=student.element("name");///获取删除节点
name.remove(name);////删除指定节点
studnet.remove(studnet.attribute("id"));//删除节点属性值<%@page import="java.util.ArrayList"%>
<%@page import="stu.student"%>
<%@page import="java.util.List"%>
<%@page import="org.dom4j.Element"%>
<%@page import="java.io.File"%>
<%@page import="org.dom4j.Document"%>
<%@page import="org.dom4j.io.SAXReader"%>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Student</title>
</head>
<body>
<h4>学生信息查询</h4>
<hr color="green" />
<table>
<tr align="center" height="22" >
<td >ID</td>
<td >Name</td>
<td >Sex</td>
<td >Age</td>
</tr>
<%
SAXReader reader=new SAXReader();
Document document=reader.read(new File("E:/student.xml"));
Element root=document.getRootElement();
List<Element> students=root.elements();
List<student> student_type=new ArrayList<student>();
for(Element element : students){
student stu=new student();
stu.setId(Integer.valueOf(element.attributeValue("id")));
stu.setNameString(element.elementText("name"));
stu.setAge(Integer.valueOf(element.elementText("age")));
stu.setSex(element.elementText("sex"));
student_type.add(stu);
System.out.println("ID:"+stu.getId()+" Name:"+stu.getNameString());
}
request.setAttribute("lists",student_type);
%>
<c:forEach var="student" items="${lists }">
<tr>
<td >${student.id}</td>
<td >${student.nameString}</td>
<td >${student.sex}</td>
<td >${student.age}</td>
</tr>
</c:forEach>
</table>
</body>
</html>
二、利用DOM进行XML文件的解析,简要过程如下:
【1】创建DocumentBuilderFactory工厂-通过该工厂得到DOM解析器工厂实例
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
【2】通过解析器工厂获取DOM解析器
DocumentBuilder builder=factory.newDocumentBuilder();
【3】从XML文件中解析Document对象语法:XML路径信息
Document document=builder.parse(String path);
【4】从XML标签中获得所有属性值语法如下:
NodeList nodeList=document.getElementsByTagName(String tagname);
附上实例进行说明过程:XML文件
<?xml version="1.0" encoding="UTF-8"?>
<people>
<student>
<names>张林</names>
<school>武汉大学</school>
<sex>女</sex>
<age>25</age>
</student>
<student>
<names>王丽</names>
<school>郑州大学</school>
<sex>女</sex>
<age>18</age>
</student>
<student>
<names>王三</names>
<school>北京大学</school>
<sex>男</sex>
<age>19</age>
</student>
</people>JSP页面代码如下:
<%@page import="com.sun.corba.se.impl.naming.pcosnaming.NameServer"%>
<%@page import="org.w3c.dom.NodeList"%>
<%@page import="org.w3c.dom.Document"%>
<%@page import="javax.xml.parsers.DocumentBuilder"%>
<%@page import="javax.xml.parsers.DocumentBuilderFactory"%>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>index</title>
</head>
<body>
<table>
<tr>
<td width="40px">姓名</td>
<td width="80px">学校</td>
<td width="40px">性别</td>
<td width="40px">年龄</td>
</tr>
<%
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
factory.setIgnoringComments(true);
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(pageContext.getServletContext().getResourceAsStream("xml/peoper.xml"));
NodeList names=document.getElementsByTagName("names");
NodeList school=document.getElementsByTagName("school");
NodeList sex=document.getElementsByTagName("sex");
NodeList age=document.getElementsByTagName("age");
for(int i=0;i<names.getLength();i++){
%>
<tr>
<td>
<%=names.item(i).getFirstChild().getNodeValue() %>
</td>
<td>
<%=school.item(i).getFirstChild().getNodeValue() %>
</td>
<td>
<%=sex.item(i).getFirstChild().getNodeValue() %>
</td>
<td>
<%=age.item(i).getFirstChild().getNodeValue() %>
</td>
</tr>
<%} %>
</table>
</body>
</html>
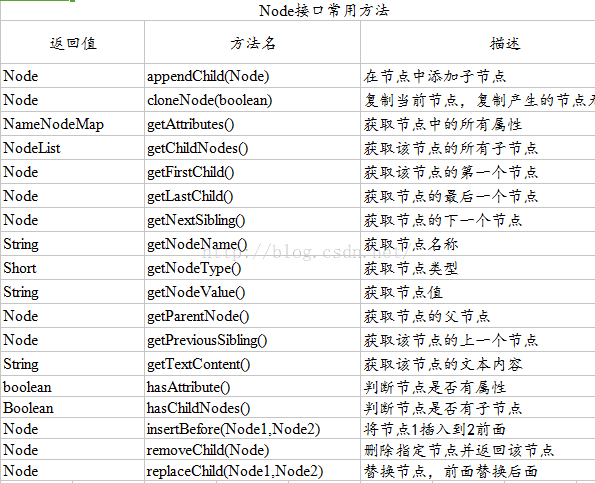
DOM接口常用方法用下面的表格进行表示: