今天在复习爬虫知识的时候,爬取一个静态网站的站点,爬取下来的字符内容无论如何也不是在网页的开发者工具中看到的。先把问题记录于下!
吸取教训:不要再非重点问题上耗费太多时间,遇到一筹莫展的情况很正常,如果毫无头绪,不如先放到一边,不过记得要把问题记录下来。
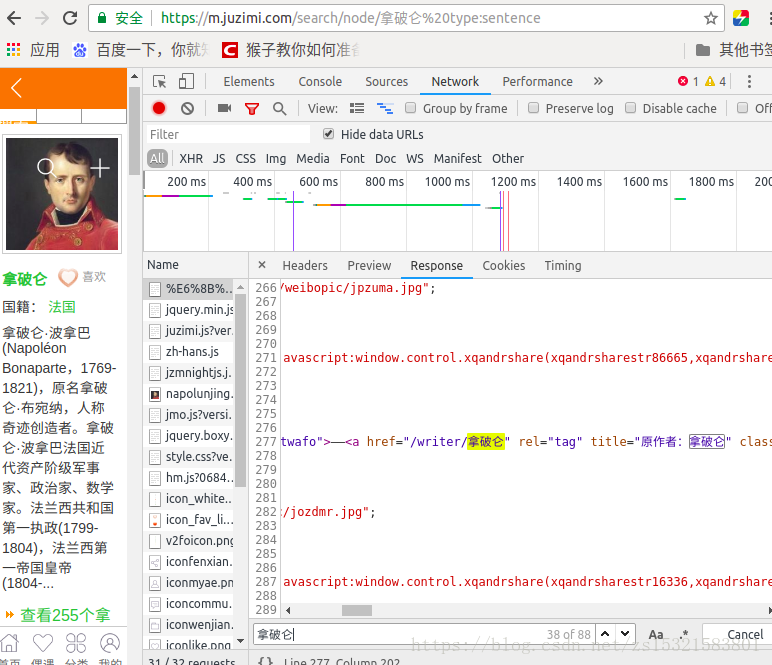
我想要爬取句子迷中关键字为”拿破仑“的语录。
header = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.344'
'0.84 Safari/537.36'}
url = 'https://m.juzimi.com/search/node/%E6%8B%BF%E7%A0%B4%E4%BB%91%20type:sentence'
html = requests.get(url, headers=header)
'拿破仑' in html.text
Out[2]: False结果显示:False
但网页中的响应栏明明不是这样的,搞不懂了!!