Navicat for MySQL建表
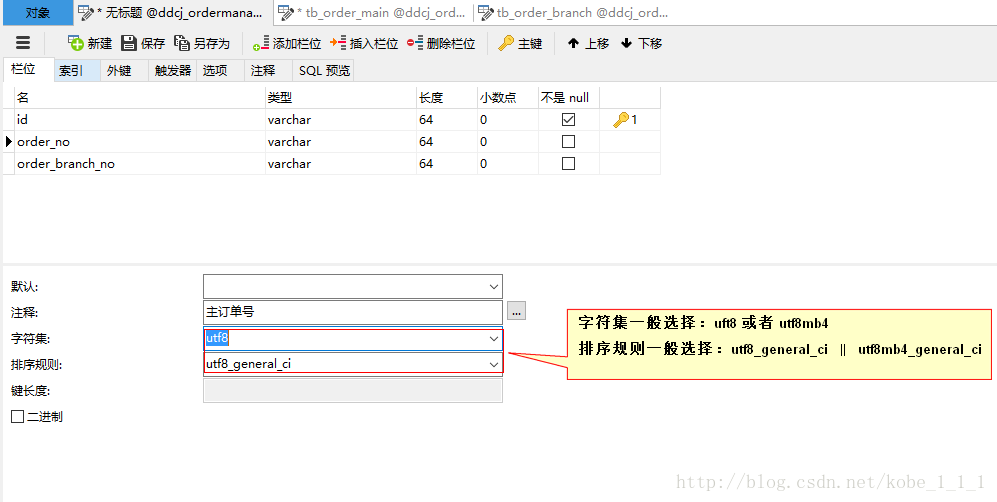
说一下utf8和utf8mb4的区别。utf8mb4是后出现的,是mysql5.5才有的字符。
既然utf8mb4是后出现的,那么可想而知,它肯定是为了弥补utf8存在的某些缺陷。
那么MySql5.5版本之前存在什么缺陷呢?
低版本的mysql支持的utf8编码,最大字符长度为3字节,如果遇到4个字节的字符就会出现错误。
- utf8
utf是unicode Transformation Format的缩写,意思是Unicode转换格式。utf-8是Unicode的一种实现方式。需要注意的是,Unicode的编码方式不同于实现方式。一个Unicode字符的编码是确定的,但在实际传输过程中由于系统平台的设计不一致,对Unicode编码的实现方式也不一样。 - Unicode
好吧,我再说一下什么是Unicode。都知道计算机傻到只能识别0和1,那么计算机在存储字符的时候,存储的依旧是数字。只不过,每一个数字和字符都存在一一对应的关系。这样,其实就是对字符进行了一次编码,比如说a—>97;&—>38;
Unicode其实就是一种编码方式。世界上的每一个字符通过Unicode编码都对应上了一个唯一的数字。
目前实际使用的Unicode版本使用16位编码空间,也就是每一个字符占2个字节。这样理论上最多可以表示2^16(65536)个字符,基本满足了各种语言的使用。而这些16位Unicode字符就构成了基本多文种平面(BMP)
最新的Unicode版本,定义了16个辅助平面,加上基本多文种平面总共17个平面。为了表示这17个平面中的所有字符,需要16+5=21 位的编码空间。虽然占用不到3个字节的空间,但是辅助平面的字符却要占用4个字节的空间。
如果要想保存4个字节的辅助平面字符,如emoji表情,就需要使用utf8mb4,它可以直接保存emoji表情,而不是存储它的替换字符。
- 新建mysql库或者表的时候还会设计到一个排序规则
utf8_unicode_ci比较准确
utf8_general_ci速度比较快
通常情况下 utf8_general_ci的准确性就够我们用的了,在我看过很多程序源码后,发现它们大多数也用的是utf8_general_ci,所以新建数据 库时一般选用utf8_general_ci就可以了
如果是utf8mb4那么对应的就是 utf8mb4_general_ci utf8mb4_unicode_ci