基于lucene与IKAnalyzer的全文检索
1、全文检索概念
全文检索首先将要查询的目标数据源中的一部分信息提取出来,组成索引,通过查询索引达到搜索目标数据源的目的,所以速度较快。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)
全文检索技术是搜索引擎的核心支撑技术。
2、全文检索的应用领域
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
3、Lucene实现全文检索
3.1、什么是Lucene?
Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
Lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能。
3.2、Lucene与搜索引擎的区别
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。全文检索系统是一个可以运行的系统,包括建立索引、处理查询返回结果集、增加索引、优化索引结构等功能。例如:百度搜索、eclipse帮助搜索、淘宝网商品搜索。
搜索引擎是全文检索技术最主要的一个应用,例如百度。搜索引擎起源于传统的信息全文检索理论,即计算机程序通过扫描每一篇文章中的每一个词,建立以词为单位的倒排文件,检索程序根据检索词在每一篇文章中出现的频率和每一个检索词在一篇文章中出现的概率,对包含这些检索词的文章进行排序,最后输出排序的结果。全文检索技术是搜索引擎的核心支撑技术。
Lucene和搜索引擎不同,Lucene是一套用java写的全文检索的工具包,为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库,搜索引擎是一个全文检索系统,它是一个单独运行的软件。
3.3、安装Lucene
Lucene是开发全文检索功能的工具包,从官方网站下载Lucene,并解压。官方网站:http://lucene.apache.org/
3.4、Lucene主要包结构
| 包名 | 功能 |
|---|---|
| org.apache.lucene.analysis | 语言分析器,主要用于的切词,支持中文主要是扩展此类 |
| org.apache.lucene.document | 索引存储时的文档结构管理,类似于关系型数据库的表结构 |
| org.apache.lucene.index | 索引管理,包括索引建立、删除等 |
| org.apache.lucene.queryParser | 查询分析器,实现查询关键词间的运算,如与、或、非等 |
| org.apache.lucene.search | 检索管理,根据查询条件,检索得到结果 |
| org.apache.lucene.store | 数据存储管理,主要包括一些底层的I/O操作 |
| org.apache.lucene.util | 一些公用类 |
3.5、Lucene主要组件
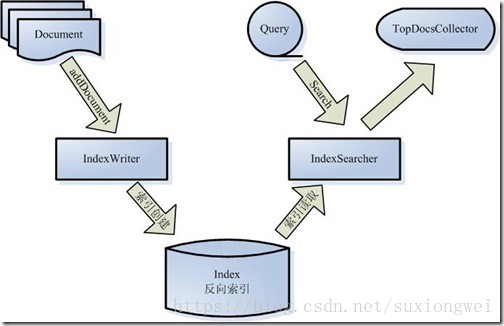
被索引的文档用Document对象 表示。
IndexWriter 通过函数addDocument 将文档添加到索引中,实现创建索引的过程。
Lucene 的索引是反向索引。
当用户有请求时,Query 代表用户的查询语句。
IndexSearcher 通过函数search 搜索Lucene Index 。
IndexSearcher 计算term weight 和score 并且将结果返回给用户。
返回给用户的文档集合用TopDocsCollector 表示。
3.6、Lucene API 的调用实现索引和搜索过程流程图

索引过程如下:
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
1、创建一个IndexWriter 用来写索引文件,它有几个参数,INDEX_DIR 就是索引文件所存放的位置,Analyzer 便是用来对文档进行词法分析和语言处理的。
2、创建一个Document 代表我们要索引的文档。
3、将不同的Field 加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field 来表示。
搜索流程如下:
搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容(这里指磁盘上的文件)。
1、IndexReader 将磁盘上的索引信息读入到内存,INDEX_DIR 就是索引文件存放的位置。
2、创建IndexSearcher 准备进行搜索。
3、创建Analyzer 用来对查询语句进行词法分析和语言处理。
4、创建QueryParser 用来对查询语句进行语法分析。
5、QueryParser 调用parser 进行语法分析,形成查询语法树,放到Query 中。
6、IndexSearcher 调用search 对查询语法树Query 进行搜索,得到结果TopScoreDocCollector 。
4、IKAnalyzer中文分词器
4.1、IKAnalyzer是什么?
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目 Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
5、项目源码 已托管到github,欢迎fork,star,学习讨论,共同进步。
5.1核心代码如下:
创建索引
@GetMapping("/createIndex")
public String createIndex(int limit,int offset) {
// 拉取数据
List<Baike> baikes = baikeMapper.getAllBaike(limit,offset);
Baike baike = new Baike();
//获取字段
for (int i = 0; i < baikes.size(); i++) {
//获取每行数据
baike = baikes.get(i);
//创建Document对象
Document doc = new Document();
//获取每列数据
Field id = new Field("id", baike.getId()+"", TextField.TYPE_STORED);
Field title = new Field("title", baike.getTitle(), TextField.TYPE_STORED);
Field summary = new Field("summary", baike.getSummary(), TextField.TYPE_STORED);
//添加到Document中
doc.add(id);
doc.add(title);
doc.add(summary);
//调用,创建索引库
indexDataBase.write(doc);
}
return "成功";
}@Component//使用@Configuration也可以
@PropertySource(value = "classpath:config.yml")//配置文件路径
public class IndexDataBase {
//Lucene索引文件路径
@Value("indexPath")
private String indexPath;
//定义分词器
static Analyzer analyzer = new IKAnalyzer();
/**
* 封裝一个方法,用于将数据库中的数据解析为一个个关键字词存储到索引文件中
* @param doc
*/
public void write(Document doc){
try {
//索引库的存储目录
Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
//传入目录和分词器
IndexWriter writer = new IndexWriter(dir, iwc);
//写入到目录文件中
writer.addDocument(doc);
//提交事务
writer.commit();
//关闭流
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}搜索:
//搜索,实现高亮
@GetMapping("/getSearchText")
public ModelAndView getSearchText(String keyWord,String field,ModelAndView mv) throws Exception {
List<Map> mapList = searchDataBase.search(field, keyWord);
mv.setViewName("/result");
mv.addObject("mapList",mapList);
return mv;
} @Component//使用@Configuration也可以
@PropertySource(value = "classpath:config.yml")//配置文件路径
public class SearchDataBase {
//Lucene索引文件路径
@Value("${indexPath}")
private String indexPath;
//定义分词器
static Analyzer analyzer = new IKAnalyzer();
//搜索
public List<Map> search(String field, String value) throws Exception{
//索引库的存储目录
Directory dir = FSDirectory.open(Paths.get(indexPath));
//读取索引库的存储目录
// 实例化读取器
IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath)));
//lucence查询解析器,用于指定查询的属性名和分词器
// 实例化搜索器
IndexSearcher searcher = new IndexSearcher(reader);
//搜索
// 构造QueryParser查询分析器
QueryParser parser = new QueryParser(field, analyzer);
BufferedReader in = new BufferedReader(new InputStreamReader(System.in, StandardCharsets.UTF_8));
String line = value != null ? value : in.readLine();
// 构造Query对象
Query query = parser.parse(line);
//最终被分词后添加的前缀和后缀处理器,默认是粗体<B></B>
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("<font color=").append("\"").append("red").append("\"").append(">");
SimpleHTMLFormatter htmlFormatter = new SimpleHTMLFormatter(stringBuffer.toString(),"</font>");
//高亮搜索的词添加到高亮处理器中
Highlighter highlighter = new Highlighter(htmlFormatter, new QueryScorer(query));
//获取搜索的结果,指定返回document返回的个数
// 收集足够的文档显示5页
TopDocs results = searcher.search(query, 5);
ScoreDoc[] hits = results.scoreDocs;
List<Map> list=new ArrayList<Map>();
//遍历,输出
for (int i = 0; i < hits.length; i++) {
int id = hits[i].doc;
Document hitDoc = searcher.doc(hits[i].doc);
Map map=new HashMap();
map.put("id", hitDoc.get("id"));
//获取到name
String name=hitDoc.get("summary");
//将查询的词和搜索词匹配,匹配到添加前缀和后缀
TokenStream tokenStream = TokenSources.getAnyTokenStream(searcher.getIndexReader(), id, "summary", analyzer);
//传入的第二个参数是查询的值
TextFragment[] frag = highlighter.getBestTextFragments(tokenStream, name, false, 10);
String baikeValue="";
for (int j = 0; j < frag.length; j++) {
if ((frag[j] != null)) {
//获取 foodname 的值
baikeValue=baikeValue+((frag[j].toString()));
}
}
map.put("title", hitDoc.get("title"));
map.put("summary", baikeValue);
list.add(map);
}
reader.close();
dir.close();
return list;
}
}6、写在最后
本文是基于lucene与IKAnalyzer的中文搜索的demo及学习记录,目的是对一些关于全文搜索学习资料的整理和建立一个简单的学习demo,其中很多图片和内容不是本人原创,如果涉及到侵权,请联系我,我马上撤下这些资源。