前言
再讲SQL路由之前,先简要的将一个SQL解析,SQL解析是sharding-jdbc非常底层的东西,了解这个,
对于真正用这个中间件的作用相对来说稍微弱一点,但是也要了解一个大概。
ParsingSQLRouter
在SQL路由之前,都会调用该类的parse方法,进行SQL解析
public final class ParsingSQLRouter implements SQLRouter {
// 分片规则
private final ShardingRule shardingRule;
// 数据源类型,比如: MySQL
private final DatabaseType databaseType;
// 是否显示SQL
private final boolean showSQL;
private final List<Number> generatedKeys;
}
@Override
public SQLStatement parse(final String logicSQL, final int parametersSize) {
// 构建SQL解析引擎
SQLParsingEngine parsingEngine = new SQLParsingEngine(databaseType, logicSQL, shardingRule);
// 解析SQL
SQLStatement result = parsingEngine.parse();
// 如果是insert操作,需要额外对主键做处理
if (result instanceof InsertStatement) {
((InsertStatement) result).appendGenerateKeyToken(shardingRule, parametersSize);
}
return result;
}
SQL解析步骤
SQLParsingEngine的parse方法如下,根据dbType , 和查询语句的Type,构建SQL解析器,并且进行解析
public SQLStatement parse() {
// 第一步
LexerEngine lexerEngine = LexerEngineFactory.newInstance(dbType, sql);
// 第二步
lexerEngine.nextToken();
// 第三步
return SQLParserFactory.newInstance(dbType, lexerEngine.getCurrentToken().getType(), shardingRule, lexerEngine).parse();
}
第一步:
根据databaseType,选用不一样的词法解析器
// com.dangdang.ddframe.rdb.sharding.parsing.lexer.LexerEngineFactory
public static LexerEngine newInstance(final DatabaseType dbType, final String sql) {
switch (dbType) {
case H2:
case MySQL:
return new LexerEngine(new MySQLLexer(sql));
case Oracle:
return new LexerEngine(new OracleLexer(sql));
case SQLServer:
return new LexerEngine(new SQLServerLexer(sql));
case PostgreSQL:
return new LexerEngine(new PostgreSQLLexer(sql));
default:
throw new UnsupportedOperationException(String.format("Cannot support database [%s].", dbType));
}
}
第二步:
调用词法解析器进行分词 , 主要就是将SQL进行分词。
第三步:
获取SQL解析器,并且进行SQL解析
public static SQLParser newInstance(final DatabaseType dbType, final TokenType tokenType, final ShardingRule shardingRule, final LexerEngine lexerEngine) {
if (!(tokenType instanceof DefaultKeyword)) {
throw new SQLParsingUnsupportedException(tokenType);
}
switch ((DefaultKeyword) tokenType) {
case SELECT:
// 查询语句
return SelectParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case INSERT:
// 插入语句
return InsertParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case UPDATE:
// 更新语句
return UpdateParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case DELETE:
// 删除语句
return DeleteParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case CREATE:
// 创建语句
return CreateParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case ALTER:
// alter语句
return AlterParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case DROP:
// DROP 语句
return DropParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case TRUNCATE:
return TruncateParserFactory.newInstance(dbType, shardingRule, lexerEngine);
default:
throw new SQLParsingUnsupportedException(lexerEngine.getCurrentToken().getType());
}
}
根据databaseType 选用不同的词法解析器,主要是因为各大厂商的SQL语法有些不同,所以需要根据databaseType来区分,
扫描二维码关注公众号,回复:
2681294 查看本文章

然后根据SQL语句的类型,调用不同的SQL解析器,将SQL解析。 关于SQL解析这一块我也没有去细看,sharding-jdbc1.5以后
将SQL解析引擎替换了druid , 对SQL采取半理解的模式。
总结:
SQL解析分为两步, 第一步为 词法解析, 词法解析的意思是就是将SQL进行拆分。
例:
select * from t_user
词法解析:
[select] [*] [from] [t_user]
这么做的目的是什么? 是为了后面的SQL解析, 一个很直白的说法,通过词法解析,我们可以知道这个SQL语句是什么类型的SQL语句 ,到底是select,还是
insert , 都需要词法解析器去做。
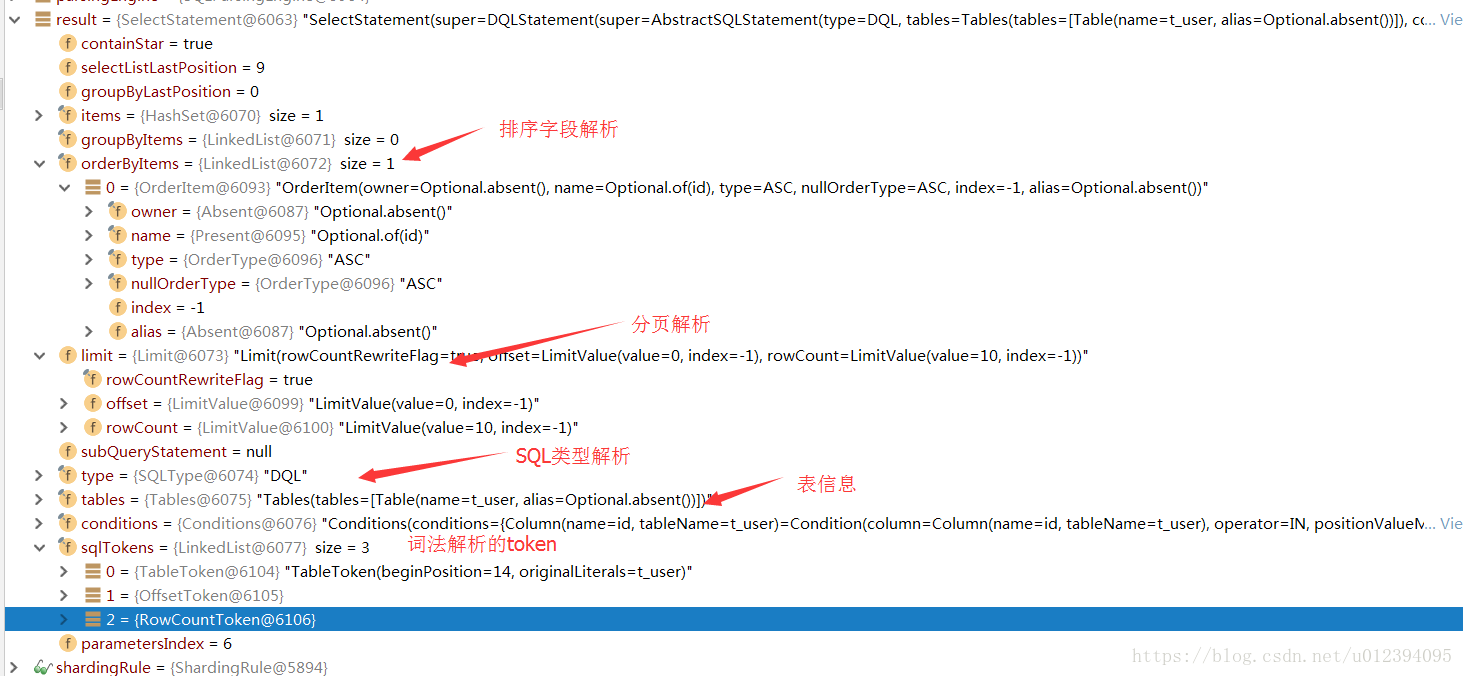
SQL解析最后这一块我没有细看原理,不过我可以给大家截一张图
SQL语句
<select id="selectUser" resultType="com.sharding.entity.User">
select * from t_user where id in
<foreach collection="ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
order by id limit 0,10
</select>
上面的SQL,通过SQL解析器最后解析的结果如下: