前言
本篇文章会从Sharding-JDBC用途、使用场景、架构,Sharding-JDBC配置使用,Sharding-JDBC分库分表实战,Sharding-JDBC事务应用与数据治理等几个方面去解析Sharding-JDBC ;对于它来说和mycat的最大区别还是作为客户端数据中间件做为解决海量数据存储的方式。
官网:ShardingSphere (apache.org)
Sharding-JDBC用途、使用场景、架构
说到 Sharding-JDBC 一定要说到ShardingSphere。
Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。


Sharding-JDBC
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
-
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。


Sharding-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。

生态链的形式。
对比起来

混合架构

功能清单
- 分库 & 分表
- 读写分离
- 分布式主键
分布式事务(doing):
- XA强一致事务
- 柔性事务
- 配置动态化
- 熔断 & 禁用
- 调用链路追踪
- 弹性伸缩 (Planning)
数据分片内核工作原理

版本规划

Sharding-JDBC配置使用
不使用spring的方式
引入Maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>



使用原生JDBC


使用Spring
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>sharding.jdbc.datasource.names=ds0,ds1
sharding.jdbc.datasource.ds0.type=org.apache.commons.dbcp2.BasicDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
sharding.jdbc.datasource.ds0.username=root sharding.jdbc.datasource.ds0.password=
sharding.jdbc.datasource.ds1.type=org.apache.commons.dbcp2.BasicDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
sharding.jdbc.datasource.ds1.username=root sharding.jdbc.datasource.ds1.password=
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding- column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm- expression=ds$->
{user_id % 2} sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->
{0..1}.t_order$->{0..1} sharding.jdbc.config.sharding.tables.t_order.table-
strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table- strategy.inline.algorithm-
expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->
{0..1}.t_order_item$->{0..1} sharding.jdbc.config.sharding.tables.t_order_item.table-
strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table- strategy.inline.algorithm-
expression=t_order_item$->{order_id % 2}

在Spring中使用DataSource
@Resource
private DataSource dataSource;数据源配置

spring boot 配置

数据源配置说明

注意,可配置属性说明 ,下面的。一些数据配置

Sharding-JDBC分库分表

进行垂直和水平拆分开,

数据节点
数据分片的最小单元。由数据源名称和数据表组成,例: ds0.t_order0
真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order0到t_order1
数据节点
tables:
t_order:
actualDataNodes: ds$->{0..1}.t_order$->{0..1}数据节点数据节点分布说明
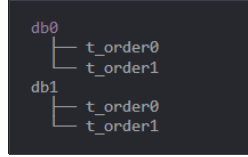
db0.t_order0,db0.t_order1,db1.t_order0,db1.t_order1
db$->{0..1}.t_order$->{0..1} 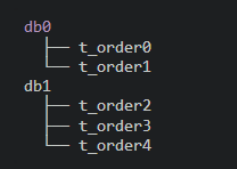
db0.t_order0,db0.t_order1,db1.t_order2,
db1.t_order3,db1.t_order4
db0.t_order$->{0..1},db1.t_order$->{2..4}分片策略

- 分片键
- 分片算法
JDBC提供的5种分片策略
databaseStrategy:
inline:
shardingColumn: user_id
algorithmInlineExpression: ds${user_id % 2}- ${begin..end}表示范围区间
- ${[unit1, unit2, unit_x]}表示枚举值
- 行表达式中如果出现连续多个${ expression }或$->{ expression }表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。

- 对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
- StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm 两个分片算法。
- PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
- RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。

complex 复合分片策略
- 对应ComplexShardingStrategy。复合分片策略提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
- ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
- 对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
- 对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。

JDBC配置默认数据源、分片策略

分布式主键

配置说明
defaultkeyGenerator: #默认的主键生成算法 如果没有设置,默认
为SNOWFLAKE算法
column: # 自增键对应的列名称
type: #自增键的类型,主要用于调用内置的主键生成算法有三个可 用值:SNOWFLAKE(时间戳+worker id+自增
id),UUID(java.util.UUID类生成的随机UUID),LEAF,其中S
nowflake算法与UUID算法已经实现,LEAF目前(2018-01-14)尚 未实现
props:# 定制算法需要设置的参数,比如SNOWFLAKE算法的worker.id
与max.tolerate.time.difference.milliseconds
绑定表

SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);广播表
shardingRule:
broadcastTables:
- t_configJDBC事务应用与数据治理
Spring-boot-starter 方式
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>业务代码中应用
@ShardingTransactionType(TransactionType.LOCAL)
@Transactional@ShardingTransactionType(TransactionType.XA)
@Transactional分布式事务应用
- 配置集中心化:越来越多的运行时实例,使得散落的配置难于管理,配置不同步导致的问题分严重。将配置集中于配置中心,可以更加有效进行管理。
- 配置动态化:配置修改后的分发,是配置中心可以提供的另一个重要能力。它可支持数据源、 表与分片及读写分离策略的动态切换。